
저는 이지스퍼블리싱 출판사의 'Do it! 데이터 분석을 위한 판다스 입문'의 책으로 공부하고 정리합니다.🐼
실습 프로젝트 내려 받는 곳
자료는 이곳에서 다운로드 받을 수 있습니다.
2장
2-3. 기초 통계 계산하기
사용 데이터는 gapminder입니다.
import pandas as pd
df = read_csv('..경로/gapminder.tsv', sep='\t')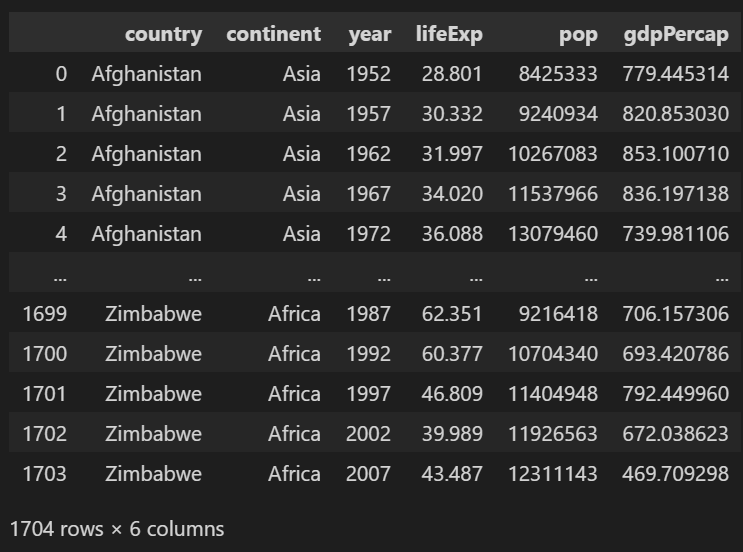
이렇게 생겼습니다.
1. lifeExp 열을 연도별로 그룹화하여 평균 계산하기
연도별 lifeExp 열의 평균을 계산하고 싶습니다. 그러면 먼저 데이터를 year로 그룹화하고 lifeExp열의 평균을 구하면 됩니다.
여기서는 groupby 메서드에 year을 전달하고 연도별을 그룹화 한 다음에 lifeExp 열을 지정하여 mean 메서드로 평균을 구합니다.
print(df.groupby('year')['lifeExp'].mean())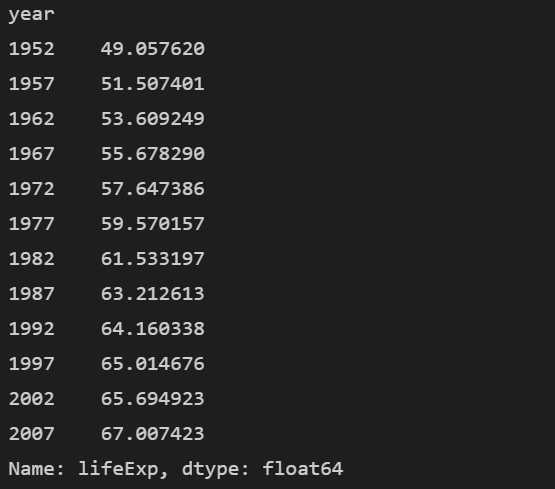
2. 데이터프레임을 연도별로 그룹화하기
하나씩 살펴보겠습니다.
group_year = df.groupby('year')
print(group_year)
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000023F9B960730>이렇게하면 연도별로 그룹화한 데이터프레임이 만들어지고, 저장된 메모리의 위치가 나옵니다.
3. 연도별로 그룹화한 lifeExp 열 추출
이제 여기서 우리가 궁금해했던 열은 lifeExp였습니다.
group_year_lifeExp = df.groupby('year')['lifeExp']
print(group_year_lifeExp)
<pandas.core.groupby.generic.SeriesGroupBy object at 0x0000023F9B9606A0>복잡하게 생각하지 말고, 열 추출할 때 대괄호 안에 '열이름' 명을 넣어주었다는 것을 떠올리면, year 속성으로 묶인 데이터프레임에서 'lifeExp'의 열을 뽑아주는구나! 알 수 있습니다.
4. 평균을 구하는 mean 메서드
이제 연도별로 묶은 lifeExp의 평균을 알고 싶습니다. 그러면 mean() 메서드만 추가해주면 됩니다
mean_year_lifeExp = df.groupby('year')['lifeExp'].mean()
print(mean_year_lifeExp)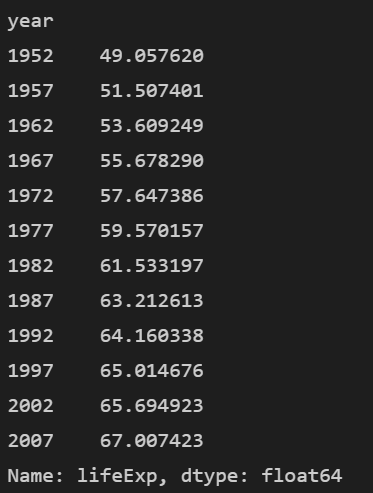
저장한 변수명 뒤에 붙이면 되지만... 하나씩 이어 붙이는 방법으로 보겠습니다.
이제 1번에서 구했던 값이 차례대로 나왔습니다.
5. 두 열의 평균 값을 연도, 지역별로 그룹화하여 계산하기
이번엔 두 개의 열의 평균 값을 연도별, 지역별로 그룹화 해봅시다.
multi = df.groupby(['year', 'continent'])[['lifeExp','gdpPercap']].mean()
print(multi)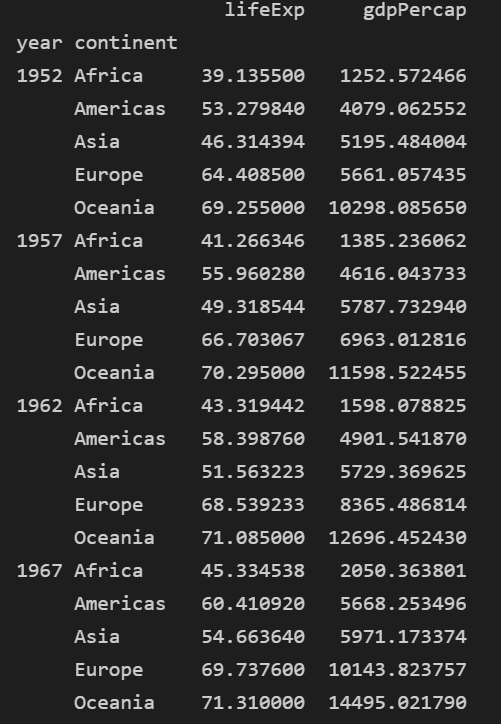
이런식으로 연도 끝까지 추출됩니다
열이 두 개일 경우 대괄호에 다시 담아서 넣어주는 규칙 그대로 사용 중입니다.
6. 그룹화한 데이터 개수 세기
그룹화한 데이터의 개수가 몇 개인지 알기 위한 방법입니다. 이걸 통계에서는 빈도수라고 부릅니다. 데이터의 빈도수는 nunique 메서드를 사용할 수 있습니다.
continent를 기준으로 데이터 프레임을 만들고 country 열만 추출하여 데이터 빈도수를 계산해 봅시다.
print(df.groupby('continent')['country'].nunique())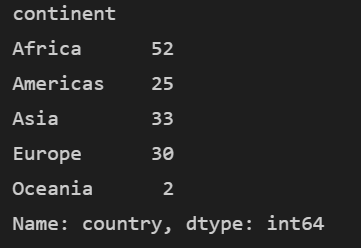
지역별로 몇 개의 동네가 있는지 알 수 있습니다!
groupby 속성으로 특정 열을 뽑고 다양한 메서드를 사용해서 기초적인 통계를 확인해보았습니다!👏
