👩🔬 이번에는 혼공머 책의 챕터 7-3 파트입니다.
참고 자료
📕 혼자공부하는머신러닝+딥러닝, 한빛미디어
📙 밑바닥부터 시작하는 딥러닝, 한빛미디어
드롭아웃(Dropout)
드롭아웃의 방식은 훈련 과정에서 층에 있는 일부 뉴런을 랜덤하게 꺼서 과대적합을 막습니다. 즉, 뉴런의 출력을 0으로 만들어버리는 것입니다.
드롭아웃은 뉴런을 임의적으로 삭제를 진행하는데요. 삭제된 뉴런은 아래 그림과 같이 다음 층으로 신호를 전달하지 않습니다.
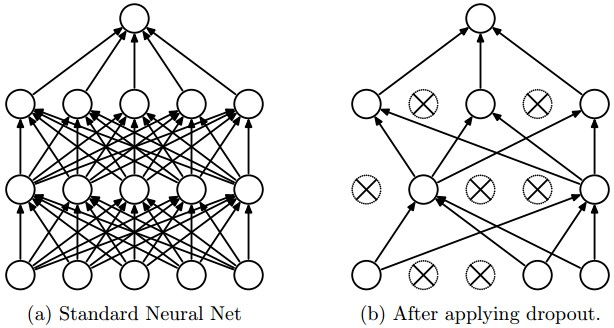
train 때는 데이터를 흘릴 때마다 삭제할 뉴런을 무작위로 선택하고, test할 때는 모든 뉴런에 신호를 전달합니다.
단, test시 각 뉴런의 출력에 train 때 삭제 안 한 비율을 곱해서 출력합니다.
여기서 얼마나 삭제할지는 우리가 정해야 할 하이퍼 파라미터입니다.
드롭아웃은 왜 오버피팅(overfitting)을 막을까요?
일부 뉴런을 삭제하면 뉴런이 특정 뉴런에 과대하게 의존하는 것을 막아줍니다. 일부 뉴런의 출력이 없다는 것이 안정적인 예측을 만들어준다고 합니다.
이는 역전파 때의 동작 ReLU와도 같다고 합니다.
순전파 때 신호를 통과시키는 뉴런은 역전파 때도 신호를 그대로 출력시키고, 순전파 때 통과시키지 않는 뉴런은 역전파 때도 신호를 차단합니다.
정리
- 오버피팅을 막기 위한 방법으로 사용된다.
- 역전파 때도 삭제된 뉴런은 사용하지 않는다.
- 평가와 예측에 모델을 사용할 때는 드롭아웃이 적용되지 않는다.
🔗 Dropout (드롭아웃) regularization
드롭아웃에 대해 포스팅한 적이 있으니 참고하시길 바랍니다. :)

AI/ML Engineer