AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE REVIEW
paper review
ABSTRACT
Transformer architecture는 NLP task에서는 표준이 되었지만 computer vision task에서는 아직 제한적
CNN에 대한 의존이 필요하지 않고, image patch의 seqeuence을 transformer에 적용하여 image classification task에서 잘 수행되는 ViT 제안
많은 양의 데이터에 대해 pre-trained 한 뒤 여러가지 recognition benchmark dataset에 대해 transfer learning을 수행하면 Vision Transformer(ViT)는 훨씬 적은 computational resource를 가지며 SOTA CNN과 비교하여 더 우수한 결과를 얻음
1 INTRODUCTION
Transformers는 NLP에서 많이 사용되고 있고 대부분의 방식은 large text corpus에서 pre-train을 수행하고 task-specific dataset에 대해 fine-tuning을 수행(BERT)
Transformers의 계산 효율성 및 확장성으로 과거보다 더 큰 사이즈의 모델을 훈련하는 것이 가능해짐 (모델과 데이터의 사이즈 증가에도 포화 되지 않음)
하지만 여전히 computer vision 분야에서는 convolutional architecture가 대세였고, transformer의 NLP 영역에서의 성공을 보고 많은 연구들에서 CNN구조에 self-attention을 혼합하여 실험 (convolutional layer를 전부 self-attention으로 대체한 연구도 있었음)
하지만, attention의 독특한 계산방식 때문에 현대의 하드웨어 가속기에 효율적으로 확장되지는 못함(이미지 전체를 그대로 넣어야 해서 단어 벡터에 비해서 연산이 너무 클 것)
→ 최소한의 수정으로 Transformer를 이미지에 직접 적용하는 실험을 진행
- image를 patch로 분할하고 이 patch의 linear embedding sequence를 Transformer의 입력으로 전달(image patch는 NLP의 token(word)과 동일한 방식)
하지만, ImageNet과 같은 중간 규모의 dataset에서 학습할때 적당한 결과를 산출하여 비슷한 크기의 ResNet보다 정확도가 떨어짐
→ Transformer는 translation equivariance 및 locality와 같은 CNN 고유의 inductive bias가 없기 때문에 불충분한 양의 data에 대해 학습할 때 일반화가 잘 되지 않을것
그러나 large-scale dataset(14M-300M Images)에서 모델을 학습하면, large-scale training이 inductive bias를 능가
ViT가 충분한 규모로 pre-trained 되고, 더 적은 데이터로 transfer 될 때 기존의 SOTA 모델들의 성능에 필적하거나 더 좋은 결과를 달성
2 RELATED WORK
Transformer는 NMT(Neural Machine Translation)을 위한것이며 많은 NLP task에서 SOTA를 달성
대규모의 transformer 기반 모델들은 일반적으로 대규모 말뭉치에 pre-train을 시킨 후에 task에 맞게 fine-tuning을 시키는 방식으로 학습을 진행
- BERT는 denoising self-supervised pre-training task, GPT는 language modeling pre-training task
self-attention을 image에 naive하게 적용하려면 각 픽셀이 다른 모든 픽셀에 attend 되어야 함
→ 픽셀 수에 대해 매우 높은 계산 복잡도를 야기하며, 이에 다양한 input size에 확장되는 것이 어려움
이에 transformer를 image processing에 적용시키기 위해서 몇가지 근사(approximation)방법들이 시도됨
- local self-attention, sparse attention, applying it in blocks of varying size 등
→ specialized attention 구조들은 효율적으로 구현되기 위해서는 복잡한 엔지니어링이 필요
가장 최근의 연구인 iGPT는 image resolution과 color space를 줄인 후 이미지에 대해 transformer를 적용: unsupervised 방식으로 학습되고 얻어진 representation으로 fine-tuning을 수행하거나 linear를 수행하여 ImageNet에서 72%의 정확도를 달성
본 논문은 기존 ImageNet 데이터셋보다 더 많은 이미지를 보유한 recognition 데이터셋을 활용한 연구
추가적인 데이터소스의 사용은 표준 벤치마크들에서 SOTA를 달성하게한다는 연구들이 있으며, 더 나아가 CNN의 성능이 데이터셋 size에 따라 어떻게 달라질 수 있는지에 대한 연구와 대규모 데이터셋(ImageNet-21k, JFT-300M)에 대한 CNN의 전이학습을 경험적으로 탐구하는 연구도 있었음
본 연구는 두 대규모 데이터셋에 초점을 맞추고 있고, 이전 연구에서 사용한 ResNet이 아닌 Transformer를 사용
3 METHOD
모델 설계 시 기존 transformer와 최대한 유사하게 구성하려 하였고, 쉽게 확장이 가능한 NLP transformer 구조 덕분에 효율적인 구현을 거의 바로 사용할 수 있음
3.1 VISION TRANSFORMER (ViT)
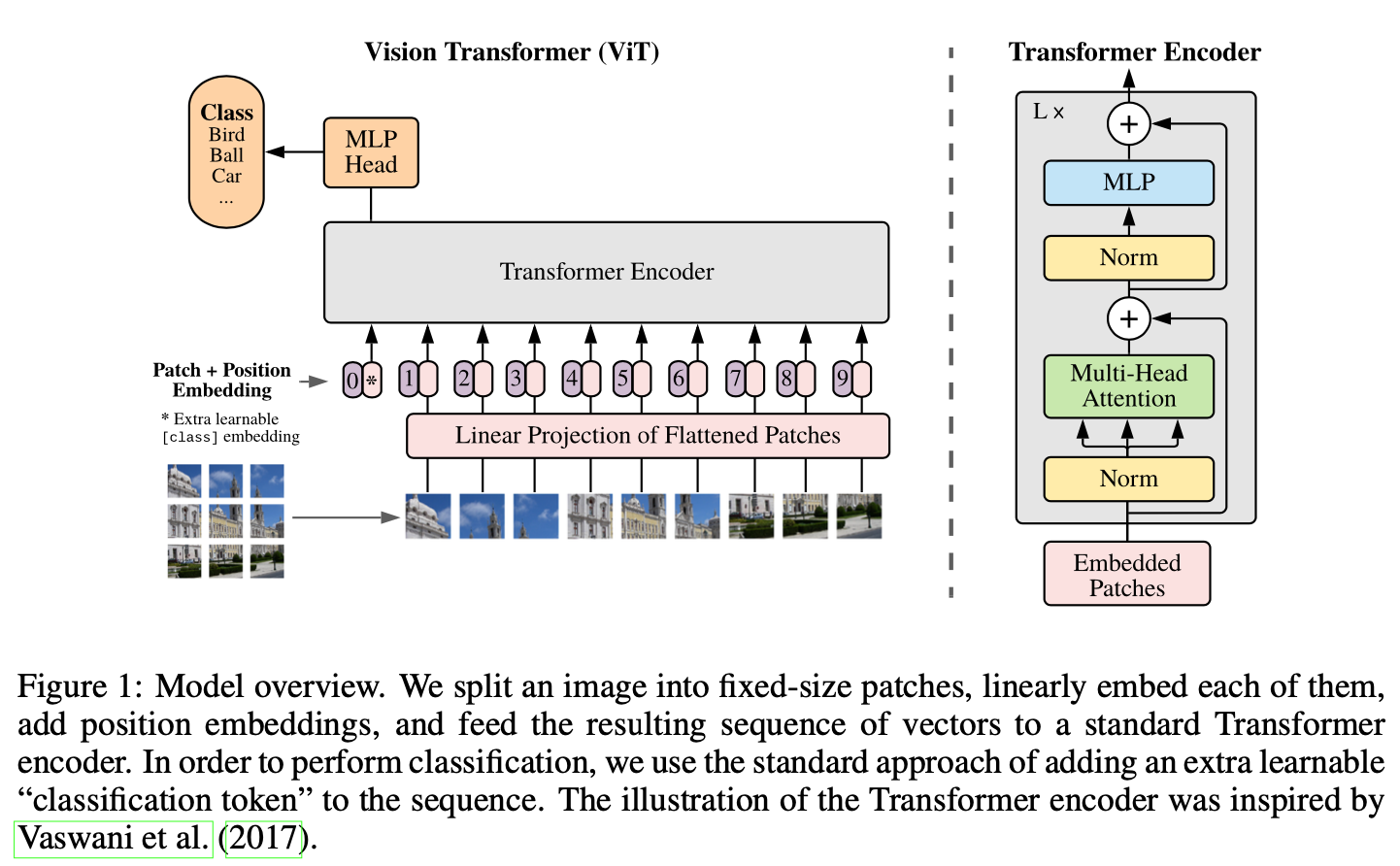
Standard Transformer는 token embedding의 1D sequence를 입력으로 받음: 이미지를 처리하기 위해 H x x w x C의 차원을 flatten된 2D patch N x (P*P x C) 차원으로 재구성
- (H,W)는 원본 이미지의 resolution이고 (P,P) 는 각 이미지 patch의 resolution, C는 이미지의 채널 수
- N = HW/P^2는 patch의 수 (transformer에 input되는 sequence의 수)
transformer는 내부의 모든 layer들의 latent vector의 size가 D로 통일: 2차원 patch들을 다시 1차원으로 flatten하고 이를 trainable한 linear projection을 거쳐 D차원 벡터로 매핑 (patch embedding)
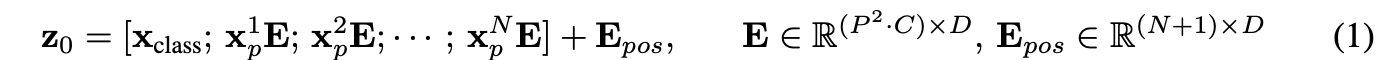
BERT의 [CLS]토큰과 유사하게, 임베딩된 패치들의 맨 앞에 하나의 학습가능한 class 토큰 임베딩 벡터를 추가
- [CLS]의 임베딩벡터는 Transformer의 여러 encoder층을 거쳐 최종 output으로 나왔을 때, 이미지에 대한 1차원 representation vector로써의 역할(label y)
- 마지막 layer에서 classification head(MLP head)가 부착되는데, 에서는 pre-training시는 MLP with one hidden layer, fine-tuning에는 MLP with no hidden layer(only single linear layer)이 수행
이미지의 위치정보를 유지하기 위해 patch embeddings에 trainable한 position embeddings이 더해짐
- 2D-aware position embedding을 사용했지만 1D position embedding과 비교했을 때, 유의미한 성능향상을 가져다주지 않아 1D 사용
→ 위의 과정을 통해 최종 임베딩 벡터들이 나오고 이 시퀀스가 encoder에 input으로 제공
transformer 인코더는 multi-headed self-attention(MSA) layer들과 MLP 블록들이 교차되어 구성
- Layer-normalization이 모든 block의 전에 적용되며, residual connection이 모든 블록 이후에 수행
- MLP는 GELU(Gaussian Error Linear Unit)를 activation으로 사용하는 2개의 layer를 포함
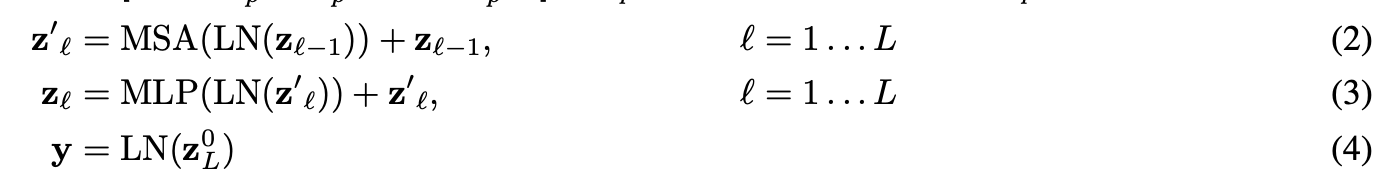
Inductive bias.
ViT는 일반적인 CNN과 다르게 공간에 대한 image-specific inductive bias를 덜 가지고 있음
CNN에서 locality, 2-dim neighborhood 구조, translation equivariance는 전체 모델의 각 layer에 적용됨
ViT에서는 MLP층만 local하고 translationally equivariant하고, self attention layer는 global함
2-dim neighborhood 구조는 매우 드물게 사용됨: 모델의 초기에 이미지를 patch로 자를 때와, 다른 해상도를 가진 이미지의 position embedding을 fine tune할 때
이것들 외에는 초기화 할 때의 position embedding은 2d 위치 정보를 담고있지 못하고, 패치들 간의 공간적 관계는 scratch부터 학습 되어야 함
Hybrid Architecture.
raw image patches를 대신해 CNN의 feature map으로부터 input sequence가 형성될 수 있음
이러한 하이브리드 모델에서 식(1)의 patch embedding projection E는 CNN의 feature map으로부터 추출된 패치들에 적용
위에서와 동일하게 classification input 임베딩과 position embedding들이 추가됨
3.2 FINE-TUNING AND HIGHER RESOLUTION
ViT를 large dataset들에 pre-train하고 더 작은규모의 downstream task 데이터셋에 fine-tune
이 과정에서 pre-trained prediction head(MLP head)는 제거되고 0으로 초기화된 D×K의 feed forward layer를 부착: classification layer를 다시 학습시키는 전통적인 fine-tuning 방식을 따름
- K는 downstream classification task의 class 개수
최근 연구들에서 pre-training보다 더 높은 해상도로 fine-tune 하는것이 benefical 하다는 사실이 밝혀짐
→ 이에 fine-tuning에서 사전훈련 데이터보다 더 높은 해상도에서 진행했으며, 이러한 고해상도 image를 전달할 때 patch size (P×P)는 유지하므로 input sequence length N이 더 길어짐
ViT는 임의의 sequence length를 처리해야 하므로, pre-trained position embedding은 의미가 없어짐
→ 따라서 원본 이미지에서의 위치에 따라 길이에 맞춰 2D interpolation을 수행
이러한 Resolution 조정 및 patch extraction은 이미지의 2D 위치에 대한 inductive bias가 없는 Vision Transformer에게 위치에 대한 개념을 수동으로 주입되는 유일한 과정
4 EXPERIMENTS
ResNet, ViT, 그리고 하이브리드 모델의 representation learning capabilities를 평가
각 모델이 요구하는 데이터의 양상을 파악하기 위해 다양한 사이즈의 데이터셋으로 사전훈련을 진행했고 많은 벤치마크 task 대해 평가
계산 비용에 관해서 ViT가 더욱 낮은 cost로 대부분의 recognition benchmark에서 SOTA 달성
self-supervised를 이용한 작은 실험을 수행했고, ViT가 self-supervised에서도 가능성이 있음을 보임
4.1 SETUP
Datasets.
large-scale dataset에 pre-trained
- ILSVRC-2012 ImageNet dataset (1.3M images)
- ImageNet-21k(14M images)
- JFT(303M images)
pre-trained한 모델들을 벤치마크 task에 transfer
- ImageNet(오리지널 validation 라벨과 cleaned-up ReaL 라벨)
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
19-task VTAB classification suite에도 실험을 했는데, 적은 데이터를 이용한 transfer을 평가
- Natural - Pets, CIFAR, etc.
- Specialized - medicla, satellite imagery
- Structured - geometric
Model Variants.
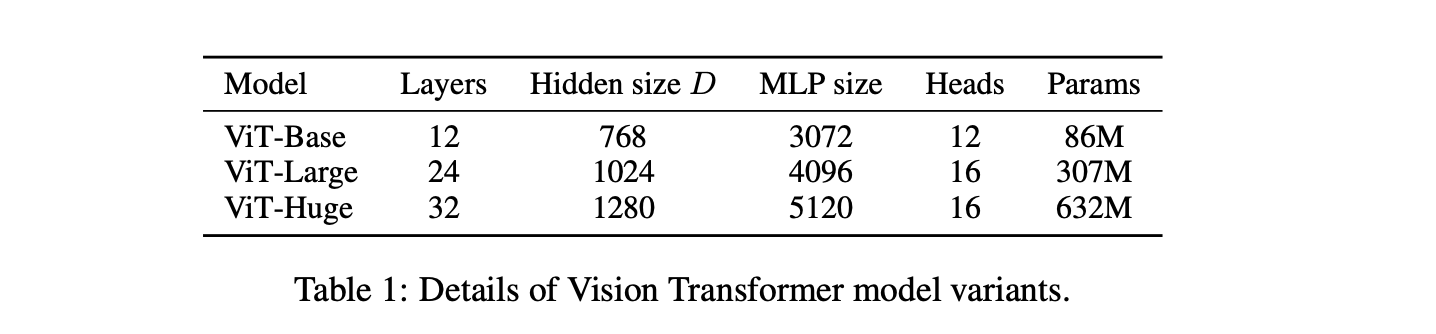
BERT에 사용된 뼈대를 base로 삼았으며 'Base'와 'Large'모델은 BERT와 완전히 동일→ 더 큰 규모의 'Huge'모델을 추가 (ViT-L/16 → 16*16 patch size를 사용하는 Large variant 모델)
패치 사이즈와 input sequence의 길이는 반비례하므로, 패치 크기가 작을수록 계산 코스트가 증가
비교 대상을 baseline CNN ResNet을 사용하였는데, original ResNet의 Batch Normalization을 Group Normalization으로 대체하였고 standardized convolution을 사용
→ 이러한 작은 변형이 transfer learning의 성능을 더 향상시키며, 이 modified model을 ResNet(BiT)로 표기
하이브리드 모델에서는 CNN의 중간 feature map들을 ViT에 1*1 패치로 나누어서 넣음
Training & Fine-tuning.
pre-training
- Adam optimizer를 활용했으며 하이퍼파라미터 세팅은 β1= 0.9, β2=0.999, batch_size = 4096
- weight decay 0.1을 적용하여 모든 모델에 대해 transfer시 유용한 도움을 주는것을 발견
- linear learning rate warmup and decay를 사용
fine-tuning
- SGD with momentum optimizer를 활용, batch_size = 512
- higher resolution finetuning(512 or 518)
- Polyak & Juditsky averaging(with factor of 0.9999)
Metrics.
few-shot accuracy
- training images의 subset에 대한 (frozen) representation을 {−1,1}^K에 매핑하는 최소제곱회귀
- closed form으로 구할 수 있어서, 간혹 fine-tuning accuracy의 연산량이 부담될 때만 사용
fine-tuning accuracy
- 각 dataset에 fine-tuning한 다음 모델의 성능
4.2 COMPARISION TO STATE OF THE ART
ViT variants 모델들 중 가장 큰 size의 ViT-H/14와 ViT-L/16을 SOTA 성능의 CNN들과 비교
- Big Transfer(BiT) : large ResNet을 이용해 supervised transfer learning 수행
- Noisy Student : large EfficientNet을 이용해 semi-supervised learning 수행(ImageNet과 라벨이 지워진 JFT-300M 데이터셋)
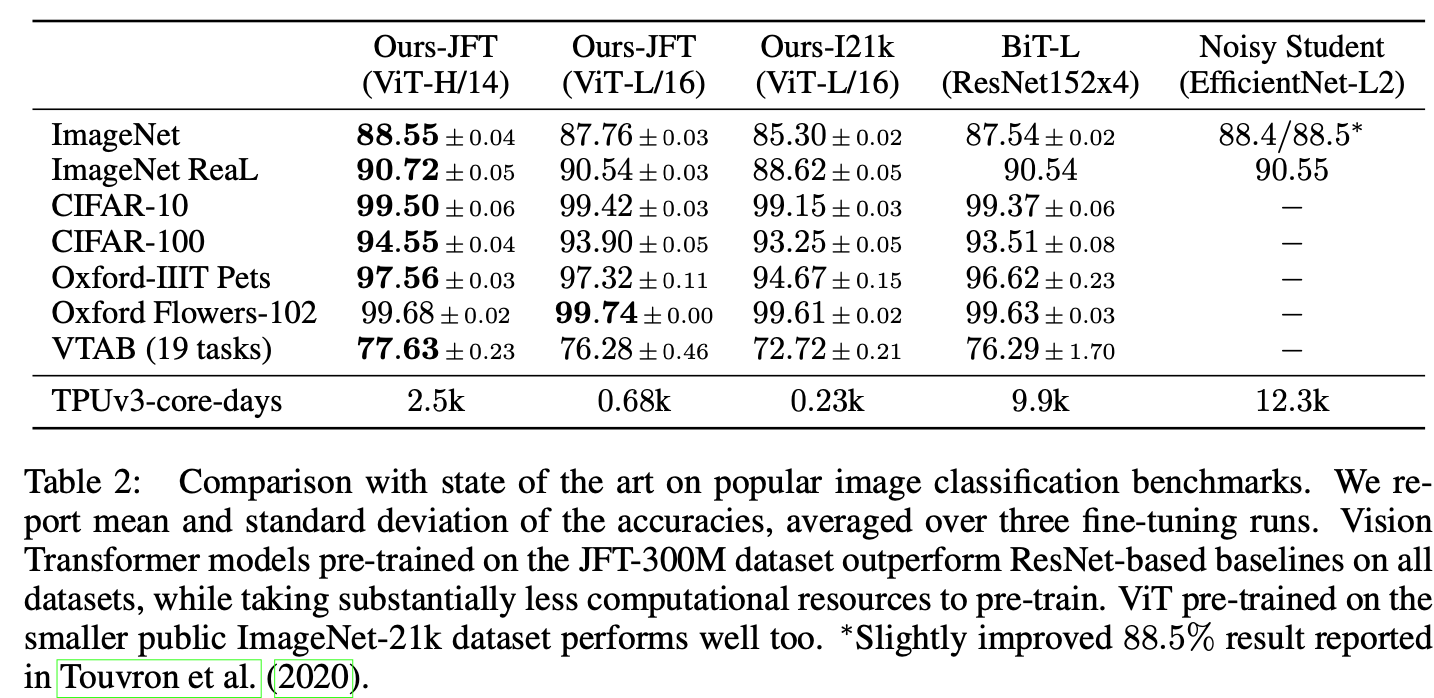
JFT-300M에서 pre-train된 ViT-L/16 모델은 모든 작업에서 BiT-L을 능가하는 동시에, 연산량은 압도적으로 낮았음
더 큰 모델인 ViT-H/14는 특히 ImageNet, CIFAR-100 및 VTAB 같은 까다로운 데이터 세트에서 성능을 더욱 향상→ 훨씬 적은 연산량
(그러나 pre-training efficiency는 architecture 뿐만 아니라 training schedule, optimizer, weight decay 등 에도 영향을 받을 수 있음)
public ImageNet-21k 데이터 세트에서 사전 훈련된 ViT-L/16 모델은 대부분의 dataset에서 성능이 우수하며, pre-training에 필요한 resource는 적음
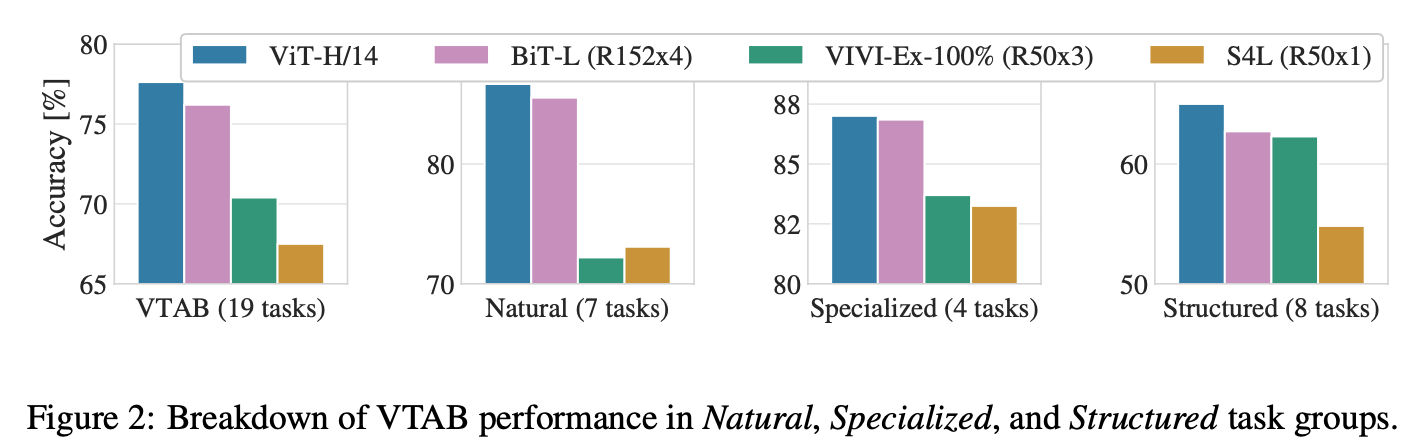
VTAB 작업을 각 그룹으로 분해하고, 이전 SOTA 방법인 BiT, VIVI와과 비교: ViT-H/14는 nature, structure task에서 BiT-R152x4와 이외 모델을 능가
4.3 PRE-TRAINING DATA REQUIREMENTS
Vision Transformer는 대규모 JFT-300M dataset에서 pre-train을 받을 때 우수한 성능을 발휘
→ dataset의 크기가 얼마나 큰 영향을 미칠까?
- ImageNet → ImageNet-21k → JFT-300M의 흐름으로 데이터셋의 크기를 증가시키며 pre-train 진행
- 더 작은 dataset에서 높은 성능을 얻기 위해 weight decay, dropout & label smoothing와 같은 규제를 적용
- ImageNet으로 미세조정한 후의 결과이고, 다양한 크기의 BiT모델의 성능 영역을 보여줌
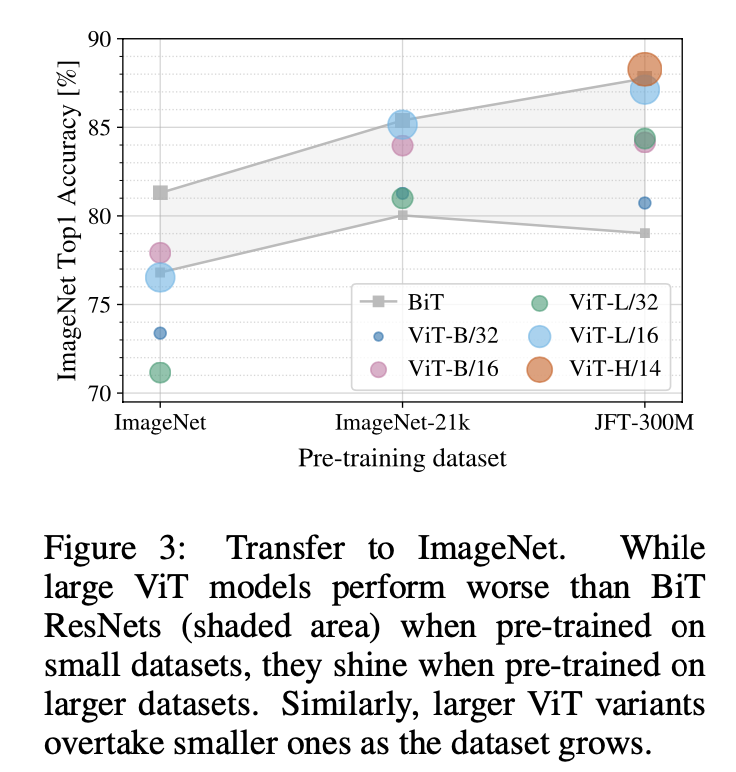
- 가장 작은 dataset에 대해 pre-train을 수행한 경우 ViT-Large 모델은 정규화에도 불구하고 ViT-Base보다 성능이 떨어지지만, ImageNet-21k dataset을 사용하면 성능이 비슷함
- JFT-300M dataset에서는 ViT가 BiT보다 더 좋은 성능을 보여줌
- 전체 JFT-300M 데이터 세트뿐만 아니라 9M, 30M 및 90M의 무작위 하위 집합에 대해 모델을 훈련
- 하위 집합에 대해 추가적인 정규화를 수행하지 않으며 모든 설정에 동일한 hyperparameter 사용 → 정규화의 효과가 아닌 본질적인 모델 속성을 평가
- few-shot linear accuracy로 모델 간의 비교
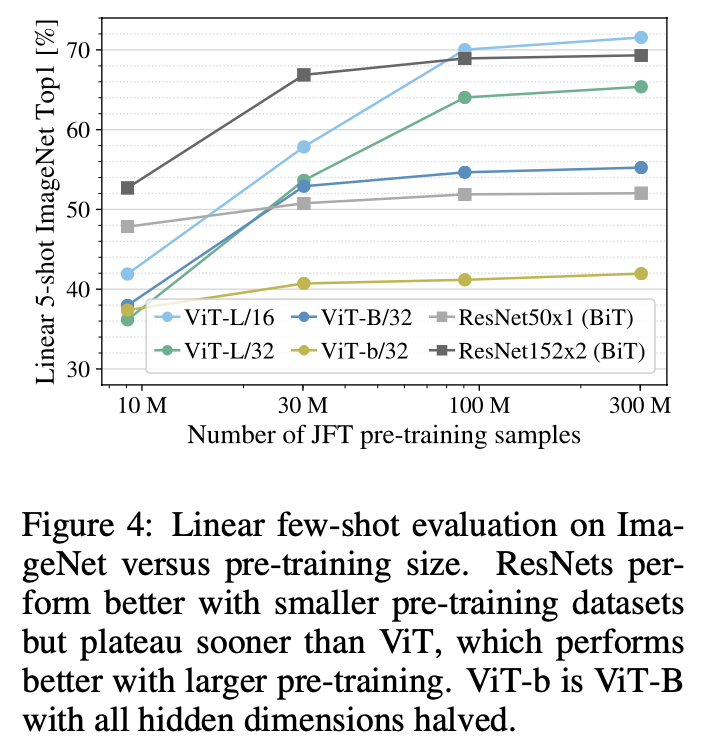
- 작은 dataset에서 pre-train에는 BiT가 ViT를 앞섰음(ViT는 작은 dataset에 overfit됨)
- 90M 이상 하위 집합에서는 더 우수
→ convolution inductive bias가 상대적으로 작은 dataset에서는 useful하지만, 큰 dataset의 경우 데이터에서 적절한 패턴을 학습하는 것이 더 beneficial
- 하위 집합에 대해 추가적인 정규화를 수행하지 않으며 모든 설정에 동일한 hyperparameter 사용 → 정규화의 효과가 아닌 본질적인 모델 속성을 평가
4.4 SCALING STUDY
JFT-300M dataset의 transfer를 수행함에 있어 각 모델의 performance 대비 pre-training cost를 평가: ResNet 7개와 ViT 6개, hybrid 5개의 모델
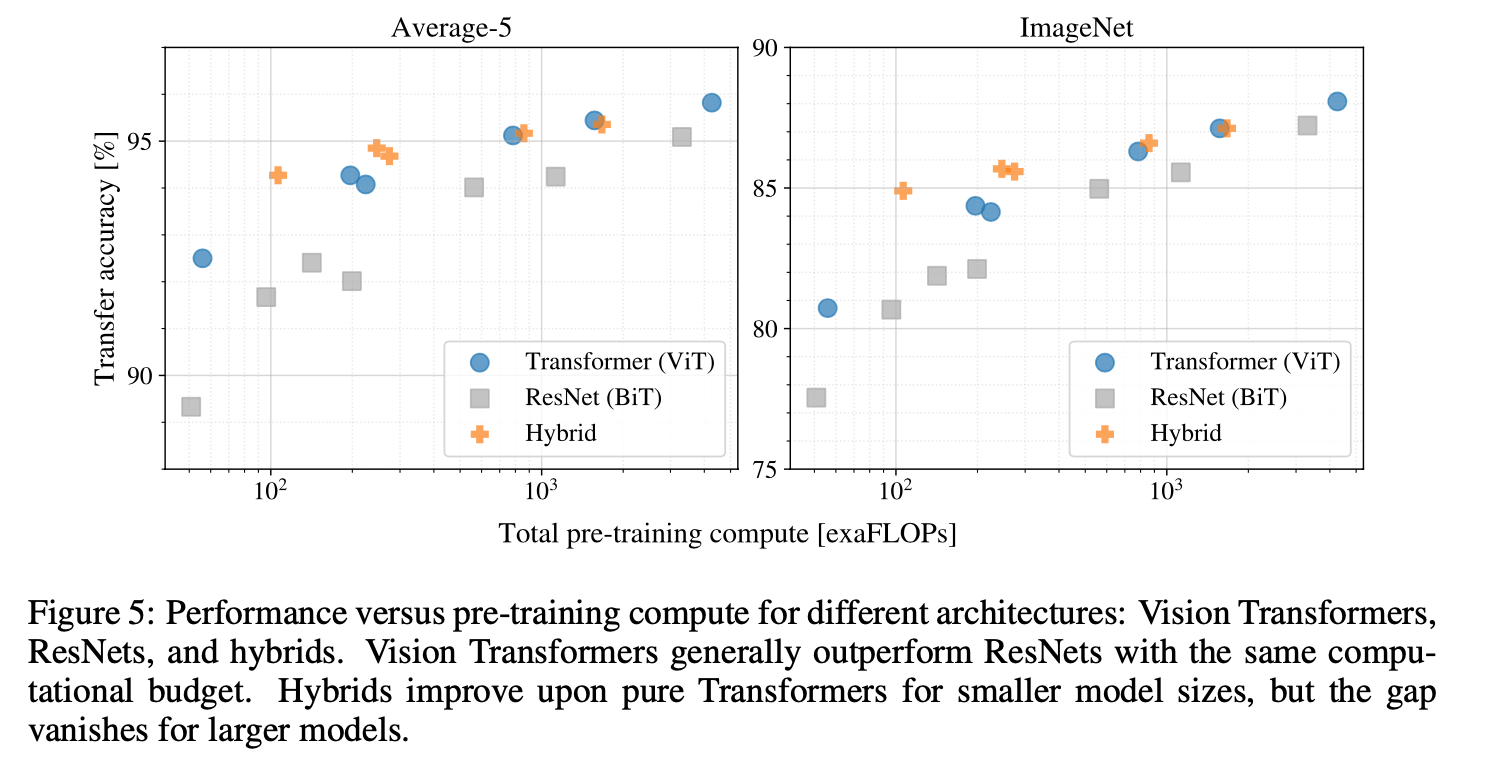
- ViT는 성능/컴퓨팅 trade-off에서 ResNet 모델들을 압도함: ViT는 동일한 성능을 달성하기 위해 약 2-4배 적은 컴퓨팅을 사용
- hybrid model이 적은 계산에서는 ViT를 약간 능가하지만, 더 큰 모델의 경우 차이가 사라짐
- ViT는 실험을 시도해본 range 내에서 saturated 되지 않았기에, 향후 확장 노력에 동기를 부여
4.5 INSPECTING VISION TRANSFORMER
ViT가 이미지를 어떻게 처리하는지 이해하기 위해 내부의 representation들을 분석
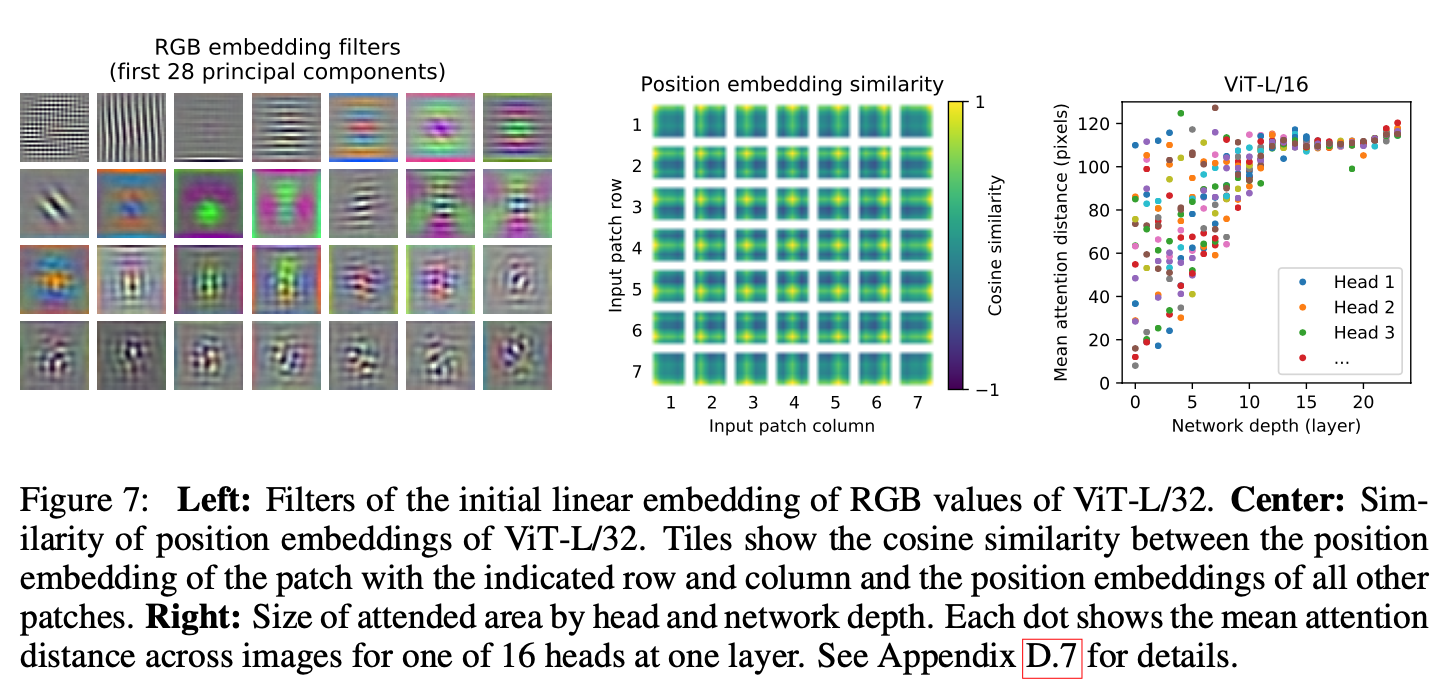
좌측
- Vision Transformer의 첫 번째 레이어는 평평한 패치를 저차원 공간에 선형으로 투영(PCA)
- 학습된 임베딩 필터의 주요 구성 요소: 각 패치 내에서 미세 구조의 저차원 표현을 위한 기저함수와 유사
- projection이후에는 학습된 position embedding이 patch representation에 추가
가운데
- positional embedding의 유사도를 통해 이미지 내부의 거리 개념을 인코딩하는 방법을 학습
- 같은 행/열에 있는 patch는 positional embedding이 더 유사한 경향이 있음
- 1d pos embedding과 2d pos embedding의 차이는 거의 없으며 오히려 1d가 더 나음
우측
- self attention은 ViT가 낮은 layer에서도 이미지 전체의 정보를 통합하여 사용할 수 있게 함
- 정보가 attention weights에 의해 통합되는 image space내의 평균거리를 계산 (attention distance는 CNN의 receptive field size와 유사함)
- 일부 head는 하위 layer에 있는 대부분의 이미지에 attention을 하여 global하게 모델에서 사용됨을 보여줌(특정 부분은 전체적으로 보고 일정 부분은 특정 요소로만 파악)
- depth가 깊어짐에 따라 attention distance가 증가하며, 모델이 의미상의 분류와 관련된 이미지 영역에 관여한다는 것을 알 수 있음(층이 높아지면서 더 넓은 데이터를 이해하는 것)

ViT가 실제로 분류에 의미적으로 관련있는 영역에 attend한다는 것을 발견함
4.6 SELF-SUPERVISION
Transformer는 NLP task에서 높은 성능을 보여주는데, 확장성뿐만 아니라 self-supervised pre-training에서 비롯됨
→ BERT에서 사용되는 MLM(Masked Language Modeling)을 모방하여 self-supervision을 위한 Masked Patch Prediction에 대한 사전 탐구를 수행
Self-supervised pre-training을 수행한 ViT-B/16 모델은 ImageNet에서 79.9%의 정확도를 달성하여 scratch로 부터 train을 수행한것보다 2%가 향상되었지만, supervised pre-training보다는 4% 떨어짐
5 CONCLUSION
Image recognition에서 Transformer를 직접 적용하는 방법을 제안
Computer Vision에서 Self-attention을 사용하는 이전 연구들과 달리, 본 논문에서는 architecture에 image-specific inductive bias를 사용하지 않고, 이미지를 patch로 해석하고 NLP에서 사용되는 standard transformer encoder로 처리함
large-scale dataset에 대한 pre-train과 결합될때 좋은 성능을 보이며,많은 image classification dataset에서 SotA를 능가하거나 능가하는 동시에 pre-train 비용이 상대적으로 저렴함
하지만 많은 challenge가 존재
- detection 및 segmentation과 같은 computer vision task에 ViT를 적용하는 것
- pre-training method에 대해 연구하는 것: 초기 실험에서 self-supervised pre-training이 개선된점을 보여주었지만, supervised pre-training을 능가하지 못함
- 모델의 크기가 증가하여도 “saturate”상태가 아닌것으로 보이기 때문에 ViT를 더 확장할 수 있음
