Abstract
인간이 생성한 번역을 자동으로 수정하는 작업인 translation error correction(TEC)
machine translation(MT)의 불완전성은, *automatic post-editing으로 post-hoc 번역을 개선하기 위해 오랫동안 노력해옴
(*기계번역 시스템의 결과물을 교정하여 더 나은 번역문을 만들어내는 기계번역의 하위분야; 기계번역 모델을 변경하는 것이 아닌 기계번역 시스템의 결과 문장을 교정하여 번역품질을 높이는 연구분야)
대조적으로, 인간은 오타에서부터 번역 규칙의 불일치에 이르기까지, 기계가 지원하기에 적합한 뚜렷한 오류를 만든다는 직관에도 불구하고, human translation을 자동으로 수정하는 문제에는 거의 관심을 기울이지 않음
따라서, 세 개의 TEC 데이터 세트로 ACED 말뭉치를 구축하고, human error을 수정하는 데 특화된 전용 TEC 모델을 개발
human error에 기반한 합성 오류에 대한 pre-train이 TECF 점수를 5.1점만큼 향상시킴
9명의 전문 번역 편집자를 대상으로 human-in-the-loop user study를 수행했고, TEC 시스템의 도움으로 그들이 상당히 높은 품질의 수정된 번역을 생산하게 되었다는 것을 발견함
1 Introduction
최근 machine translation(MT)의 발전에도 불구하고, 세계의 엄청난 양의 번역된 콘텐츠는 여전히 인간에 의해 쓰여짐
인간은 종종 신뢰할 수 있는 고품질 번역을 생산하는 것으로 가정되지만, 실제로는 철자법, 문법, 그리고 번역 오류를 포함한 오류를 만들어냄
→ 본 논문에서는 translation error correction(TEC) 작업을 소개: source 문장과 인간이 생성한 번역 t가 주어지면, TEC의 목표는 t의 모든 오류를 수정하여 개선된 번역 t'를 생성하는 것
"Translation correction"은 기계 생성 번역의 오류를 수정하는 것을 목표로 하는 automatic post-editing (APE) 작업을 통해 MT 커뮤니티에서 오랫동안 연구되어옴
TEC는 구조적으로 APE와 동일하지만, MT system에서 발생한 오류와 다른, 인간에 의해 발생한 오류의 데이터 분포를 모델링해야 함
따라서, 다양한 도메인의 세 개의 TEC 데이터 세트 모음인 ACED 말뭉치를 구축, 분석 및 릴리스하여 TEC의 오류 분포를 특성화(총 35,261개의 English-German 번역 과정에서 전문 번역가에 의해 생성되고 수정됨)
APE는 MT 시스템의 특징인 fluency errors(74%)가 우세하지만, TEC는 인간 번역자가 저지르기 쉬운 오류의 광범위한 분포를 보여줌
이 오류 분석을 사용해서, 인간이 만든 오류와 더 유사한 synthetic corruptions에 대해 pre-train하는 TEC 접근 방식을 제안
TEC의 작업은 현재 번역을 검토하고 편집하기 위해 고용된 reviewer(인간)에 의해 수행되는 경우가 많음
→ TEC 시스템은 reviewer들이 도움 없이 더 빨리 편집하거나 더 높은 품질의 최종 번역을 만드는 데 도움이 될 수 있는가? : 최고 성능의 TEC 모델을 사용하여 9명의 전문 번역가와 함께 human-in-the-loop user study를 진행
TEC 시스템으로 도움을 받았을 때 생성된 리뷰가, 시스템 없이 생성된 리뷰보다 더 높은 품질로 평가되었고, 수동 작업이 덜 수행된 상태로 생성되었다는 것을 발견함
또한 질적으로, 사용자들은 제안의 실제의 문장과 일관성이 중요하다고 논평하고, 미래에 자동화된 지원이 기술적 오류를 발견하고, 파악해야 할 오류에 대한 인식을 개선하는 데 도움이 될 것이라고 추측함
앞으로 연구 커뮤니티가 model outputs(APE) 또는 human outputs(TEC)을 수정하는 학습 중 어디에 집중해야 하는지에 대한 자연스러운 질문이 발생
→ 최근 MT가 개선됨에 따라 APE 모델은 이미 고품질인 model outputs 개선하기가 점점 더 어려워짐
→ 반면에, 인간은 계속해서 오류를 만들어낼 것 이라고 예상: TEC 모델은 인간을 지원하는 방법으로 계속해서 혜택을 제공할 것
- commercial translation workflow에서 자연스럽게 생성된 human translation과 수정본의 세가지 dataset을 포함하는 TEC의 첫번째 corpus인 ACED를 출시
- ACED에서, 인간이 저지르는 오류의 종류를 분석하여 APE가 translation flunency를 수정하는 것에 의해 지배되는 반면, TEC는 번역에 나타나는 더 광범위한 오류를 수정하는 데 초점을 맞추고 있음을 발견함
- APE와 같은 유사한 작업에 대해 개발된 접근법을 능가하는 TEC에 대한 pre-train 접근법을 제안: 인간 번역 오류를 수정하기 위한 뚜렷한 접근법의 필요성을 시사함
- 전문 번역가들이 TEC 모델의 도움을 받을 때 더 높은 품질의 번역을 생산한다는 것을 발견하고 human-in-the-loop user study를 수행
2 The ♠ ACED Corpus for TEC
source language s과 인간이 생성한 번역 t가 주어지면, TEC의 목표는 수정된 대상 언어 문장 t'를 생성하는 것
ASICS, Emerson, DIGITALO-CEAN(DO)의 세 가지 TEC 데이터 세트인 ACED 말뭉치를 소개하며, 각각은 다양한 도메인의 English-German 문장 (s, t, t')으로 구성됨
1) ACED의 모든 번역은 경험이 많은 전문 번역가들에 의해 만들어짐: 각 문서는 interactive neural MT system을 사용하여 사람에 의해 처음부터 번역되고, 검토자에 의해 검토됨
→ 결과적으로, ACED corpus의 예는 번역자가 저지르는 실제 오류를 나타냄
2) ACED는 다양함: 다양한 도메인의 세 개의 데이터 세트가 서로 다른 오류 분포와 TEC 작업에 대한 초기 작업의 어려움을 나타냄
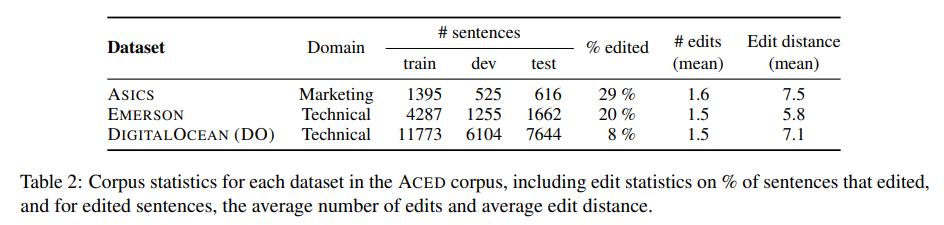
- ASICS: 제품명과 설명이 포함된 마케팅 콘텐츠
- EMERSON: 산업 제품 이름
- DO: 소프트웨어 엔지니어링 튜토리얼
2.1 How do TEC and APE errors differ?
TEC 작업의 human error가 APE의 model error와 어떻게 다른지 이해하기 위해
ACED 오류 유형 vs WMT 2021 APE 공유 작업 세트에서 무작위로 샘플링된 100개의 오류
→ 비교한 다음, 다음 세가지 유형중 하나로 분류하는 오류 분류법을 정의하여 오류 유형으로 주석을 달음
(1) Monolingual edits: target-side text에서만 식별할 수 있음: typos(spelling, punctuation, spacing, orthographic issues), grammar and fluency로 나눔(awkward phrasing, word choice, or non-native-sounding disfluencies)
(2) Bilingual edits: 소스와 대상 텍스트 간의 불일치: 과도하거나 과소 번역, 오역
(3) Preferential edits: 언어 외 프로젝트 요구 사항(용어 또는 문체 선호도)에 설명된 대로 고객의 선호도와 일치하지 않는 텍스트

- TEC는 error correction에 관심을 둠
- 오류 유형은 모델이 편집을 수정하는 방법을 학습하는 데 필요한 기능을 분리하기 위한 것
모델의 유형별 평가를 위한 evaluation 세트로 사용하기 위해 ASICS의 모든 테스트 문장에 대한 오류 레이블에 주석을 달고 release함
대규모 EMERSON과 DO dataset에서는 주석을 달 50개의 오류를 무작위로 샘플링 함
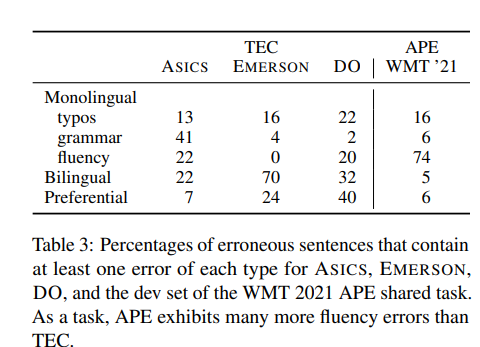
→ 각 유형에 대해 적어도 하나의 오류가 있는 문장의 비율을 나타냄(각 문장에는 여러 오류 유형이 있을 수 있음)
→ APE의 문장 중 74%는 fluency 오류를 보이는 반면, 다른 유형은 APE에서 두드러지게 보이지 않음
→ 이 오류 분포는 서로 다른 모델링 기술을 사용하는것이 낫다는 것을 보여줌
→ APE는 MT 시스템의 fluency 번역 특성을 수정하는 반면, TEC는 인간이 더 일반적으로 나타내는 오타, 불일치 및 문법 오류를 식별하고 수정하는 데 중점을 두도록 설계됨
2.2 How difficult is it to learn to edit?
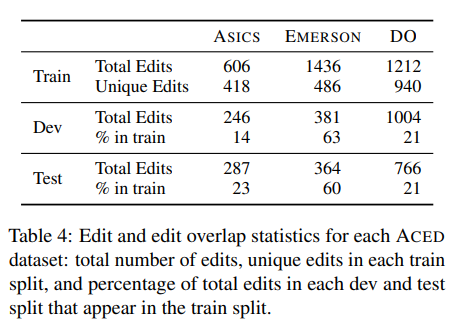
ACED에서 올바른 편집을 학습하는 것이 얼마나 어려울 수 있는지 정량화하기 위해 edit overlap 대한 통계
모델이 수행할 것으로 예상되는 편집이 train set에 정확히 나타나는 비율은 얼마인가?
→ ASICS 및 DO에서는 dev 및 test의 총 편집 수의 약 20%가 train set에 나타나는 반면, EMERSON은 약 60%의 dev 및 test 편집이 train 세트에 나타남
-- 무슨말인지 모르겠음 --
edit overlap rate는 precision and recall에 대한 상대적인 스케일 감각을 제공하지만, recall에 대한 upper bound는 제공하지 않음
train 세트에 정확히 나타나지 않는 편집 내용을 학습할 수 있음: 제품 이름을 대문자로 표시하는 경우("Winterized" → "WINTERIZED")은 많은 개별 편집으로 나타나는 학습 가능한 패턴
또한 일부 오류는 typo, grammatical, fluency, or bilingual error이기 때문에 fine-tuning 없이 수정 가능
반대로, 주변 문장 맥락에 따라 훈련 세트에 나타나는 편집을 잘못하는 것도 가능함
3 Approaches to TEC
TEC 모델을 제안하고, 관련 작업을 위해 설계된 여러 모델과 비교하여 TEC에도 효과적인지 여부를 결정함
모든 모델은 왼쪽에서 오른쪽으로 대상 시퀀스 t'를 생성하는 Transformer를 사용
모두 WMT18 번역 과제의 36M 문장에 대해 pre-train이 되었고, ACE에서 fine-tuning(Moses toolkit)
33k byte pair encoding subwords와 함께 English-German vocabulary를 사용
- dropout 0.1
- learning rate 0.0002인 Adam Optimizer
- greedy inference
3.1 Dual-Source Encoder-Decoder Model
APE와 TEC 모델에 사용하는 dual-source encoder decoder model: transformer에 source 문장과 원본번역을 추가로 인코딩하도록 architecture을 조정함
→ dual-source model이 원래 번역 t에서 토큰을 복사할 수 있도록 추가 인코더-디코더 주의 계층으로 모델을 보강하는 복사 메커니즘을 구현함
3.2 Synthetic Data Generation
TEC 및 GEC 모델의 경우 사전 훈련을 위해 (s, t, t')을 생성
번역 데이터의 target측을 t'로 corrupting하여 t를 생성하고, 각 문장에 대해 corruption 확률 p_c~ N(μ = 0.01,σ = 0.04)을 0으로 샘플링함
해당 문장의 각 문자와 단어에서 확률 p_c를 사용하여, 해당 위치에 적용할 것을 하나를 무작위로 선택(insertion, deletion, transposition, repetition)
3.3 TEC Models
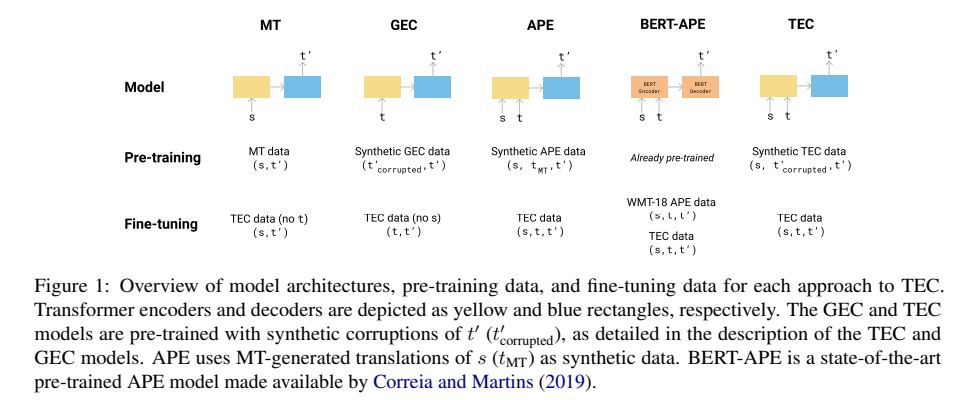
본 논문에서 비교하는 다섯 가지 접근법
TEC: 두 개의 입력(s, t)과 출력 t'를 인코딩한 synthetic data를 pre-train하는 dual source encoder-decoder 모델을 구현한 후, ACED에 대해 fine-tuning
MT: English-German neural machine translation model(standard model)을 훈련하고, (s,t’) 쌍을 ACED에 대해 fine-tuning
GEC: 잘못된 독일어 문장 t를 입력으로 받아 수정된 t'를 출력하는 encoder-decoder GEC 모델을 평가 → TEC 모델과 동일한 복사 메커니즘을 사용하여 t를 생성하고, pre-train을 하기 위해, t' corrupt하고, ACED에 대해 fine-tuning
APE: TEC 모델과 동일한 dual source encoder-decoder을 구현하고, (s, t, t')에 대해 pre-train → train dataset를 두 부분으로 나누고, 각각의 절반에 MT 모델을 훈련하고, 각 모델을 사용하여 훈련 중에 사용하지 않았던 데이터 세트의 나머지 절반을 번역함, 그런 다음 ACED에 대해 fine-tuning
BERT-APE: 최첨단 APE 모델을 작업에 직접 적용할 수 있는지 여부도 평가(BERT 기반 encoder-decoder) → APE dataset 사용하고 ACED에 대해 fine-tuning
4 Results & Discussion
TEC의 주요 metric은 error toolkit으로 계산된 MaxMatch 점수(M^2): M^2는 discrete edits를 추출하기 위해 t와 t'를 정렬하는 GEC의 표준 메트릭
(원래 번역이 대부분 정확하기 때문에 F_0.5를 비교하여 가중치를 높이는 GEC 평가 관행을 따르기로 함)
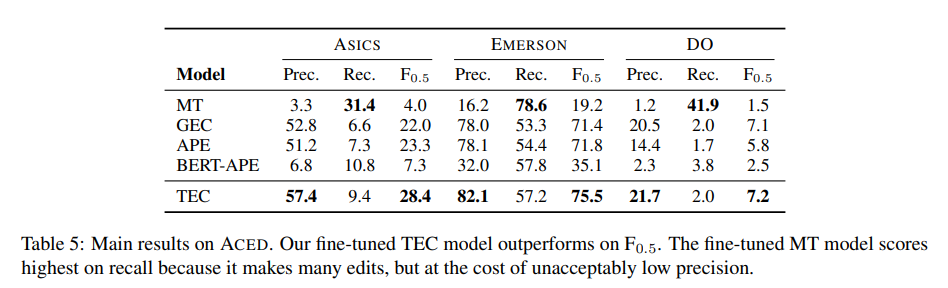
- TEC가 모든 dataset에서 가장 좋은 F_0.5 점수를 달성함 → 실제 human correction 대한 fine-tuning은 상당한 이점을 제공함
- MT(t를 무시하는)과 GEC (s를 무시하는)두 모델 모두 TEC보다 성능이 떨어짐
- MT 모델의 높은 edit recall은 많은 edit을 제안하였기 때문이고, precision은 낮아짐
- GEC 모델은 높은 precision이지만 recall이 낮음
Can APE models be directly adapted for TEC?
TEC는 APE와 구조적으로 동일하므로, APE 목표에 대해 훈련된 모델이 TEC에 직접 적용할수 있는지는 자연스러운 의문
→ APE와 TEC 모델은 pre-train에서만 차이가 있지만, 성능 차이는 상당하며, 이는 GEC와 유사한 data synthesis 절차가 TEC에 더 적합함을 나타냄
또한, ACED에서 fine-tuning 전의 SOTA인 BERT-APE 모델은 너무 많은 edit을 하기 때문에 precision도 낮고, F_0.5 score도 낮음
→ 기계 오류를 수정하는 데 탁월한 모델이, 인간 번역에서 잘 작동한다고 가정할 수 없다는 것을 강조
4.1 Fluency & Per-category Error Analysis
ASICS에서 대체 메트릭을 사용하여 보다 심층적인 비교를 수행: 주석이 달린 오류 레이블이 진단 도구로 포함
-
모델이 얼마나 편집하고 있는지 이해하기 위해, 전체적 rewrite의 fluency를 측정하기 위해 GEC 평가에 사용되는 BLEU의 변형인 GLEU 메트릭과 n-gram 중첩을 살핌
-
우리는 t'와 정확한 일치를 측정하는 sentence-level accuracy를 비교함: 전반적인 문장 수준 정확도를 계산함
또한, 해당 오류 유형으로 주석이 달린 (편집된) 문장에 대해 오류 유형별 정확도를 보고함
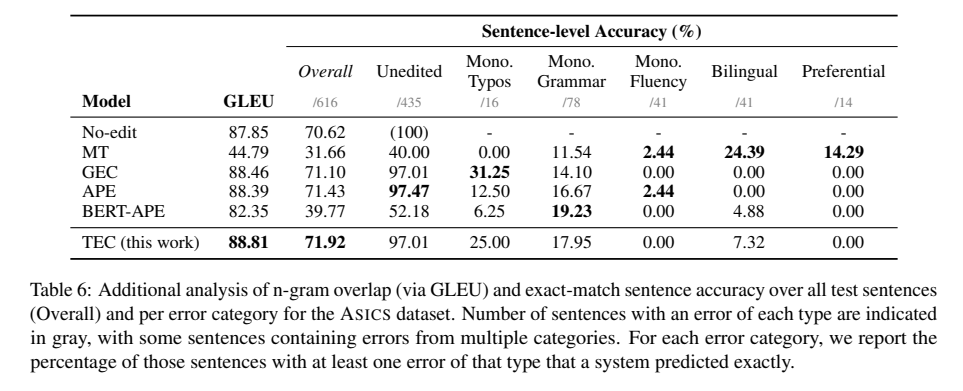
→ TEC 모델은 모든 문장에 걸쳐 두 가지 대체 메트릭에서 전체적으로 최고의 점수를 달성
→ 특히, APE 모델은 Mono.Typos는 가장 정확도가 떨어짐: neural MT decoder는 오타와 유사한 오류를 덜 발생시키기 때문
→ 향후 다양한 모델의 강점을 활용하여 TEC를 개선할 수 있음
5 User Study: Assisting Professional Translators with TEC
현재 TEC는 인간이 수동으로 수행함 → TEC 시스템이 인간에게 유용할 수 있는지 조사하기 위해, TEC모델로 human-in-the-loop user study 를 수행
5.1 Methodology
reviewer 역할을 할 전문 번역가 9명을 모집하고, 내용과 선호하는 용어에 익숙해지기 위해 ASICS train set의 문장을 읽고 참조하도록 함
그 후, 각각 ASICS 시험 세트에서 74개의 문장을 검토하도록 배정받음: 74개 문장 중에서 TEC 시스템은 57개 문장에 대해 제안된 편집을 예측했고, 나머지 17개 문장에 대해서는 TEC 시스템은 어떠한 편집도 예측하지 않음

- 각 검토자에 대해 74개의 문장을 무작위로 추출하여, 문장이 가능한 경우 절반은 TEC 제안을 보여주는 "assisted condition”에 있고 나머지 절반은 TEC 제안을 보여주지 않는 "unassisted condition"을 설정
- 그리고 문장에 제안이 있는 경우, 검토자는 먼저 각 제안을 수락하거나 거부하도록 요청받음
- 그리고 나서, 검토자들이 번역에 만족할 때까지 텍스트를 수정함
- 그런 다음 버튼을 클릭하여 번역을 확인하고 다음 문장으로 이동함
검토 과정에서 추적하는 부분
- TEC 제안이 제시된 경우 수용 또는 거부 여부
- 각 문장을 검토하는 데 소요된 총 시간
- 사용자가 수행한 편집 작업(삽입 및 삭제) 수
- Levenshtein edit distance (원본 텍스트와 최종 텍스트)
마지막으로, TEC가 품질에 영향을 미치는지 평가하기 위해, 우리는 10번째 번역자에게 9개의 검토된 번역의 순위를 매겨 검토된 문장의 품질을 비교하도록 함
5.2 Results
- User study에서, 79%의 TEC 제안이 수용됨
- TEC 제안이 소요된 시간과 번역 품질에 미치는 영향을 분석하기 위해, TEC 제안이 존재하는 255개 문장(9명의 검토자에 걸쳐)에만 초점을 맞춤
- 모든 통계적 유의성 테스트의 경우 모든 양이 정규 분포를 따르지 않거나 로그 정규 분포를 따르지 않기 때문에 통계적 유의성 테스트에 Mann-Whitney(MW) U-test를 사용
5.2.1 Effects of Suggestions on Time Spent During the Review Process
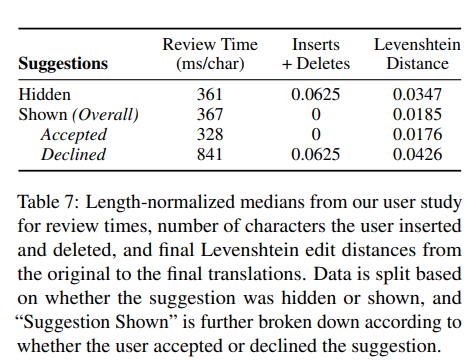
TEC 제안이, 문장을 검토하는 데 소요되는 시간에 어떤 영향을 미치는지 분석
우리는 긴 문장을 읽고 검토하는 데 더 많은 시간이 필요하기 때문에, 정규화된 시간을 비교
제안이 숨겨져 있는 경우와 표시된 경우의 정규화 검토 시간에는 큰 차이는 없음
제안이 제시될 때, 정규화된 검토 시간은 검토자가 제안을 수용한 문장에서 거절한 문장에 비해 현저하게 적음
→ 잘못된 TEC 제안이 표시되면 검토자가 주의가 산만해지고 속도가 느려지기 때문에 TEC의 자동 평가에서 정확성이 실제로 강조되어야 함
5.2.2 Effects of Suggestions on Edits Made During the Review Process
검토자가 삽입하고 삭제해야 하는 문자 수와 최종 검토된 문장이 원본과 얼마나 다른지에 의해, 측정된 제안이 편집 노력에 미치는 영향을 분석
제안이 표시된 경우, 삽입+삭제 횟수가 크게 감소함
제안이 제시될 때, 제안을 수용될 때와 거절할 때에도 유의한 감소가 있음
원래 번역본과 최종 번역본의 Levenshtein distance은 제안이 표시된 경우와 숨겨진 경우, 제안을 수용할때와 거절할때 의미있는 차이가 있지 않았음
→ TEC 시스템 제안은 사용자가 수행해야 하는 수동 타이핑의 양을 크게 줄이는 데 도움이 됨
5.2.3 Effects of Suggestions on Reviewed Sentence Quality
TEC 지원이 품질에 미치는 영향을 평가하기 위해 독립 검토자(10번째)가 작성한 품질 순위를 사용
품질 순위는 정규 분포를 따르지 않았기 때문에 통계적 유의성을 검사하기 위해 Mann-Whitney U-test를 사용

제안이 표시될 때의 median quality ranking은 1, 제안이 숨겨져 있을 때는 2
제안을 표시할 때 품질 순위는 숨겨져 있을때보다 낮음(품질이 더 높음)
→ TEC 제안을 보여주는 것이 검토자들이 달리 알아채지 못했을 수 있는 오류를 수정하거나 원하는 수정을 위해 해당 오류를 유도하는 데 도움이 될 수 있음
5.3 Qualitative Findings
질적 피드백을 보고하기 위해 검토자를 대상으로 연구 후 설문조사를 실시함
5.3.1 The Role of Reliability and Trust
5명의 검토자가 신뢰성이 중요하다고 언급함: 일부 제안이 잘못되었다는 것을 알게 되었을 때 시스템을 신뢰하기 어려웠거나, 시스템이 안정적으로 수정하지 않음
(e.g. always hyphenating when appropriate): “Because I wasn’t sure I can trust the suggestions (because I saw several incorrect ones) so it took me longer to think/check whether the suggestion is right. And I have to read the entire sentence again anyway to check for other errors the sug- gestion didn’t catch...would only work if I knew 100% that the suggestions are always right”
이 의견들은 정량적인 발견과 일치: 높은 정밀도만을 갖는 것으로는 충분하지 않음 → 검토자들이 시스템이 정확한 오류를 감지했다고 믿을 수 없다면, 전체 문장을 주의 깊게 읽어야 하기 때문에 시간을 절약하지 못할것이고, 반대로, 높은 recall, 낮은 precision의 시스템은 주의를 산만하게 할 뿐만 아니라, 전반적으로 제안이 맞는지 의심하게 만듬
→ 미래의 TEC 시스템은 사용자 신뢰를 위해 precision과 recall의 균형을 맞춰야 함
5.3.2 Use Cases for TEC
많은 검토자는, 신뢰할 수 있는 TEC 시스템이 특히 유용할 수 있다는 것도 강조함
- 두 명의 검토자는 TEC가 GEC 사용 사례와 유사하게 수정 및 오타에 도움이 된다고 함 “If the tool would manage to reliably show missing punctuation marks, or numbers, or that the translation contains different numbers than the source, that would be helpful and save time.”;“recurring mistakes”
- 세 명의 검토자는 이 시스템이 시간을 절약하기 위해 더 많은 수정을 하기를 바란다고 언급함 “There were not many suggestions, and they only offered small improvements...Not clear whether I would save time or not.”
- 세 명의 검토자는 TEC 시스템이 translation 생산 과정의 집중적인 부분인 클라이언트 특정 요구 사항을 다시 검색하는 데 memory aid or substitute 가 될 수 있다고 논평함
한 리뷰어는 이것이 처음인 번역가들에게 특히 유용할 수 있다고 언급함 “if I am new to an account and don’t yet know whether this client wants hyphens or not (always an issue with German). So usually I have to re- search... (or guess), but if the QA suggestions knew this client’s preference and would tell me, that would save me time.”
- 마지막으로, 세 명의 검토자는 특히 세부사항을 놓치기 쉬운 반복적인 내용에서 어떤 오류를 발견할 수 있는지를 인식함으로써 attention-directing tool로 유용할 수 있다고 함 “makes you more sensitive for spotting similar errors”; “makes you aware of what kind of errors to look for in upcoming segments”; “maybe it helps with [repetitive sentences] that you would otherwise just quickly glance at.”
6 Conclusion & Future Work
translation error correction(TEC) 작업을 소개하고, 다양한 도메인에 걸쳐 3개의 TEC 데이터 세트로 구성된 human traslations의 자동 수정을 연구하기 위해 ACED corpus를 발표
TEC 데이터에 대한 분석에서, 인간이 만드는 오류가 MT 시스템에 의해 만들어지는 오류와 어떻게 다른지 보여주었고, 이 작업은 이전에 연구된 automatic post-editing task 과는 다른 접근방식임
human translation error의 분포와 더 밀접하게 일치하는 synthetic data generation 절차를 제안하고 이 데이터에 대해 pre-train된 TEC 모델이 APE, MT, GEC으로 개발된 모델보다 로 우수한 성능을 발휘함을 보여줌
마지막으로, TEC 시스템이 실제 인간에게 어떻게 도움이 되는지 보여주었고, 전문적인 검토자를 돕고 그들이 고품질의 검토된 번역을 생산하도록 이끌었음
향후 작업은 최신 MT 시스템의 장점을 활용하는 방법(예: 시스템 초기화 또는 편집 제안)을 조사하거나 보다 정교한 합성 데이터 생성 기술(예: 소스 문장 또는 언어 지식 사용)을 개발하여 TEC 시스템을 개선할 수 있음
Human-AI interaction 관점에서, TEC는 현대 NLP 시스템으로 전문가를 지원하는 방법을 연구하기 위한 실제 사용 사례와 testbed를 제시하여 인간과 기계의 최고를 결합할 수 있는 기회를 암시함
장점
- 처음 보는 분야인데도 translation error 의 종류와 human translation과 machine translation을 계속해서 비교해주며 설명해주어 잘 이해할 수 있게 논문을 썼음
- 인간이 오타에서부터 번역 규칙의 불일치 등 기계가 지원하기에 적합한 뚜렷한 오류를 만들지만 human translation을 자동으로 수정하는 문제에는 거의 관심이 없었지만 본 논문에서 다뤄서 best paper라고 생각함
단점
- 9명의 검토자(10명의 검토자)를 선정할때 전문가라고 설명하였지만, 구체적인 기준이 안나와있고 왜 9명을 선택했는지?
- 9명으로 TEC제안을 수용했다는 것이 일반화가 될 수 있을까?
코드

- TEC모델에 대한 코드가 아니라, evaluation과 dataset에 관한 github -> 논문에서도 그렇게 나와있음
import argparse
error_types = [
"monolingual-typo",
"monolingual-grammar",
"monolingual-fluency",
"bilingual",
"preferential",
]
def eval_sentence_level(orig, hyp, ref, labels):
origf = open(orig)
hypf = open(hyp)
reff = open(ref)
labelsf = open(labels)
# For edited segments:
# correct edit: hyp sentence matches true sent
# incorrect edit: hyp sentence makes a diff edit from true
# no edit: hyp sentence doesn't edit at all
error_counts = {k: {"correct-edit": 0, "incorrect-edit": 0, "no-edit": 0} for k in error_types + ["unedited-example"]}
total_correct = 0
total_num = 0
num_unedited_examples = 0
for orig_line, hyp_line, ref_line, labels_line in zip(origf, hypf, reff, labelsf):
total_num += 1
if len(labels_line.strip()) == 0:
num_unedited_examples += 1
types = ["unedited-example"]
else:
types = labels_line.strip().split(",")
# True pos
if hyp_line == ref_line:
total_correct += 1
for t in types:
error_counts[t]["correct-edit"] += 1
# False pos
elif hyp_line != ref_line and hyp_line != orig_line:
for t in types:
error_counts[t]["incorrect-edit"] += 1
# False neg
elif hyp_line != ref_line and hyp_line == orig_line:
for t in types:
error_counts[t]["no-edit"] += 1
else:
assert False, "unknown error type"
print("Num unedited examples: ", num_unedited_examples)
print("Error counts", error_counts)
print("Total correct: ", total_correct)
print("Total num: ", total_num)
error_counts["All"] = total_correct / total_num
return error_counts
def print_sentence_level_acc(error_counts):
print("{:=^66}".format(" Sentence-level statistics "))
print("Category".ljust(48), "Acc".ljust(8))
for cat, cnts in sorted(error_counts.items()):
if cat == "All":
accuracy = cnts
print(f"{cat}".ljust(48), str(accuracy).ljust(8))
else:
accuracy = cnts["correct-edit"] / (cnts["correct-edit"] + cnts["incorrect-edit"] + cnts["no-edit"])
print(
f"{cat} (total num {sum(cnts.values())})".ljust(48),
str(accuracy).ljust(8)
)
print("="*66)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-orig", help="Confirmed target file", required=True)
parser.add_argument("-hyp", help="A hypothesis file", required=True)
parser.add_argument("-ref", help="A reference file", required=True)
parser.add_argument("-sent_labels", help="Sentence-level error type labels", required=True)
args = parser.parse_args()
error_counts = eval_sentence_level(args.orig, args.hyp, args.ref, args.sent_labels)
print_sentence_level_acc(error_counts)
- 마지막 파라미터에 Output파일 만들어질 PATH만 지정하면 되는거 아닌가 ,,,
-> sh파일 뜯어봐야하는데 뭔소린지 모르겠어요 ,,,
-> 단점: 코드가 나와있진않다,,

3개의 댓글

꼼꼼한 논문 리뷰 잘 보았습니다 ( _ _ ) 사람의 번역에도 오류가 있을 수 있는데 이를 해결하고자 하는 시도들을 처음 알게 되어서 좋았습니다 !

NLP 스터디 처음 발표하시는데도 불구하고 정말 꼼꼼하게 준비해오셔서 감동먹었습니다!!!! best paper에 연구분야도 새로워서 꼭 정독해보고 싶었는데 덕분에 쉽게 이해했습니다. 감사합니다