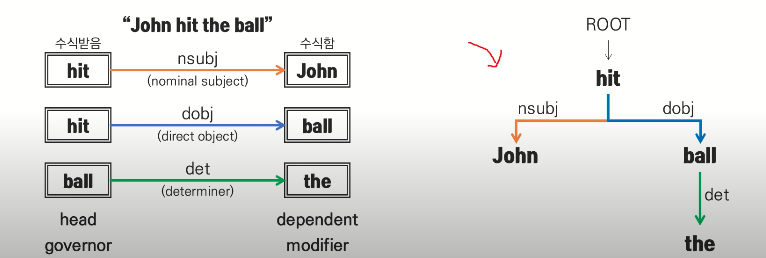
What is Parsing?
각 문장의 문법적인 구성 또는 구문을 분석하는 과정 (구문분석 트리를 구성하는것
- constituency parsing: 문장의 구조를 파악하는것이 주 목적
- dependency parsing: 단어간 관계를 파악하는것이 주 목적
dependency parsing
각 단어간 의존 또는 수식 관계를 파악 -> 한국어와 같이 자유어순을 가지거나 문장성분이 생략가능한 언어에서 선호됨
- Transition-based : 두 단어의 의존 여부를 순서대로 결정하며 점진적으로 구문트리 구성
- Graph-based :가능한 의존관계를 모두 고려한 뒤 가장 확률이 높은 구문분석 트리 선택 (candidate trees 존재)
transition-based parsing
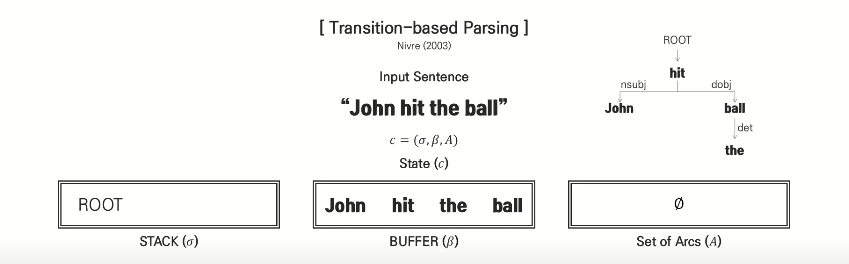
모든 decision은 State c를 input으로 하는 함수 f(c)를 통해 이루어짐
f: SVM, NN..
decision: shift / Right-Arc / Left-Arc
shift: buffer에서 stack으로 이동하는 과정
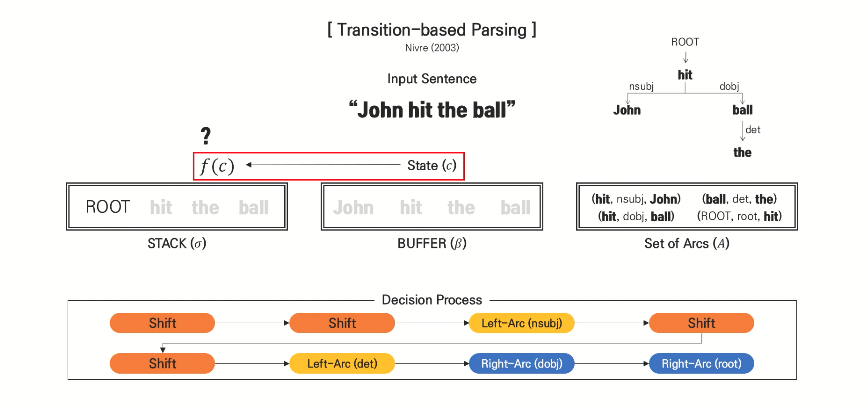
제목의 뜻은?
parsing을 위해 점진적인 표현을 배운다!
목차
1 Introduction
2 Related Work(생략)
3 Approach
4 Results
5 Discussion
6 Concolusion
1 Introduction
사람이 언어를 이해하는 것은 점진적인 과정임
-> 사람은 한 단어씩 들을 수 있고, listener은 말이 시작함과 동시에 언어를 이해함
하지만, 구문분석의 최고성능을 내는 machine model은 전체 문장을 필요로 하고 bidirectional deep model로 좋은 성능을 냄
따라서, 인간과 같은 점진적으로 작동하는 정확한 parser을 만들어야 함
NLP의 incrementality(점진성)은 왼쪽에서 오른쪽으로 처리하는 것
예를 들어, incremental transition-based parser는 한 번에 한 단어씩 입력을 받고, 각 단어 뒤에 shift-reduce와 같은 동작을 출력
그러나, 이 논문에서 non-speculative incrementality에 관심을 둠
(추측적이지 않은 incrementality)
representation의 기호가, 특정 구문 decision 대한 commitment를 encoding하지만 decision에 대한 증거가 입력의 해당 접두사에 없을때 "추측적"이라고 함
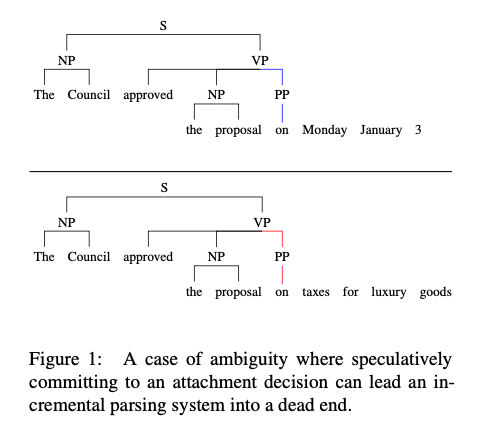
Transition-based system은 추측적
예를들어, 위 그림에서 전치사 "on"이 명사 "proposal"에 붙는지 동사 "approved"에 붙는지에 대한 결정을 내려야 함
Transition-based system은 왼쪽-> 오른쪽으로 진행하는 처리패턴에서 올바른 분석을 나타내는 명확한 단어("Monday" or "taxes")보다 먼저 전치사의 첨부를 결정하는 작업을 배치
-> 이러한 추측성은 정확한 구문분석을 만드는것을 비현실적으로 만듬
따라서 이 논문의 목표는, 최대한 추측이 없는 구문 분석 representation을 만드는 것
transition based system과 유사한 방식으로 구성됨
또한 representation이 discrete symbol로 나타나게 만듬
end-to-end 학습으로 진행 (2개의 단계)
-
각 단어를 syntatic decision으로 mapping함 -> 이것은 discrete token으로 표현됨
-
read-out network -> discrete token을 입력으로 하고구문 분석 tree를 출력으로 생성
2 Related Work
3 Approach
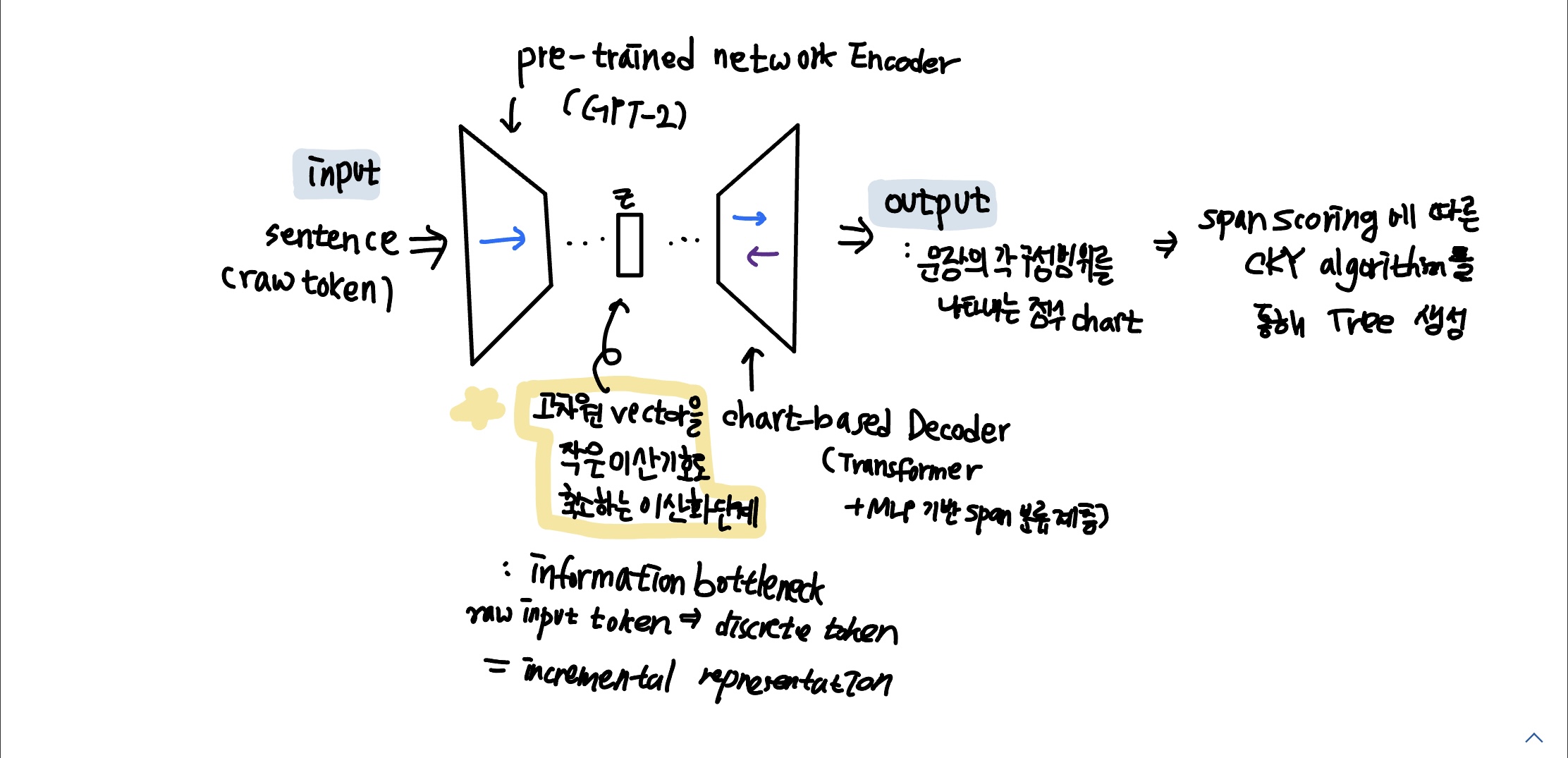
model = pretrained network를 사용하는 encoder 계층 + chart-based decoder 계층
incrementality를 보장하기 위해 encoder는 GPT-2를 기본으로 하고, backwards flow를 허용하지 않음
사전 훈련된 encoder와 모델의 후속 부분(read-out network) 사이의 interface에서 encoder 네트워크의 고차원 벡터를 작은 이산 기호로 축소하는 이산화 단계를 도입함
또한 read-out network (decoder)는 입력의 원래 텍스트가 아닌 이러한 이산 기호에만 access 가능
따라서, 이산 기호의 시퀀스는 문장의 동기식 구조를 나타내는 데 필요한 모든 정보를 인코딩해야 함
그래서, information bottleneck 도입: discrete token의 크기를 raw input token 각각의 32개의 고유한 symbol로 제한함
이산화 후, 학습된 임베딩 층을 거쳐 벡터들은 양방향 read-out 네트워크에 입력으로 공급됨 (트랜스포머 계층과 MLP 기반 스팬 분류 계층으로 구성됨)
네트워크의 출력은 문장의 가능한 각 구성 범위를 나타내는 점수 차트-> 그 후 span scoring에 따라 CKY 알고리즘을 통해 트리가 효율적으로 생성됨
인코더는 단방향이지만 read-out 네트워크는 양방향임
또한, 이 논문의 분석 대상은 네트워크 자체가 아니라 미래 context에 대한 지식을 인코딩하지 않는 distcrete symbol
representation을 어떻게 만드는지?
(Neural Discrete Representation Learning 논문)

오른쪽 그림에서, encoder에서 나온 output과 가장 가까운 포인트인 e2로 매핑됨

즉, 위의 식의 embedding space로 매핑되어 가장 가까운 포인트와 매핑되고 그 결과값으로 discrete symbol 생성됨
4 Results
English Penn Treebank의 레이블이 지정된 구성트리에 적용함


->Penn Treebank WSJ 테스트 세트에서 94.97 F1의 점수를 달성(unibidirectional pretrained model사용)
동일한 사전 훈련된 인코더와 deep bidirectional processing은 95.10 F1을 달성함
-> 이는 incremental representation이 경쟁력 있는 정확도로 구문 분석 트리를 유도할 수 있음을 보여줌
또한, 생성된 표현의 간결성 측면을 추가로 평가 -> symbol 세트의 크기를 다양화 하면서 진행
bidrectional - BERT
clustered Lexicon - k-means clustering of single word embeddings
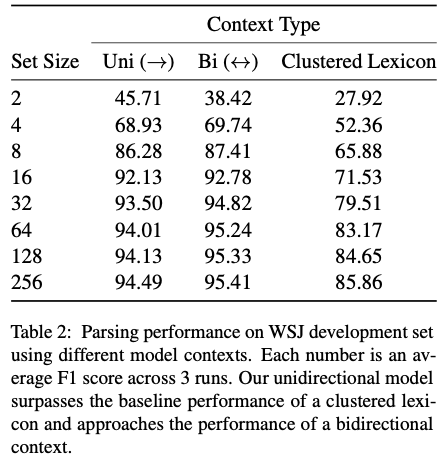
lexicon을 뛰어넘었고, unidirectional model로 BERT의 성능에 도달했음
set size가 커질수록 성능이 좋아짐
5 Discussion
5.1 Incremental Behavior
높은 F1 점수를 달성한 후, 실제로 representation이 incremental하는것을 증명
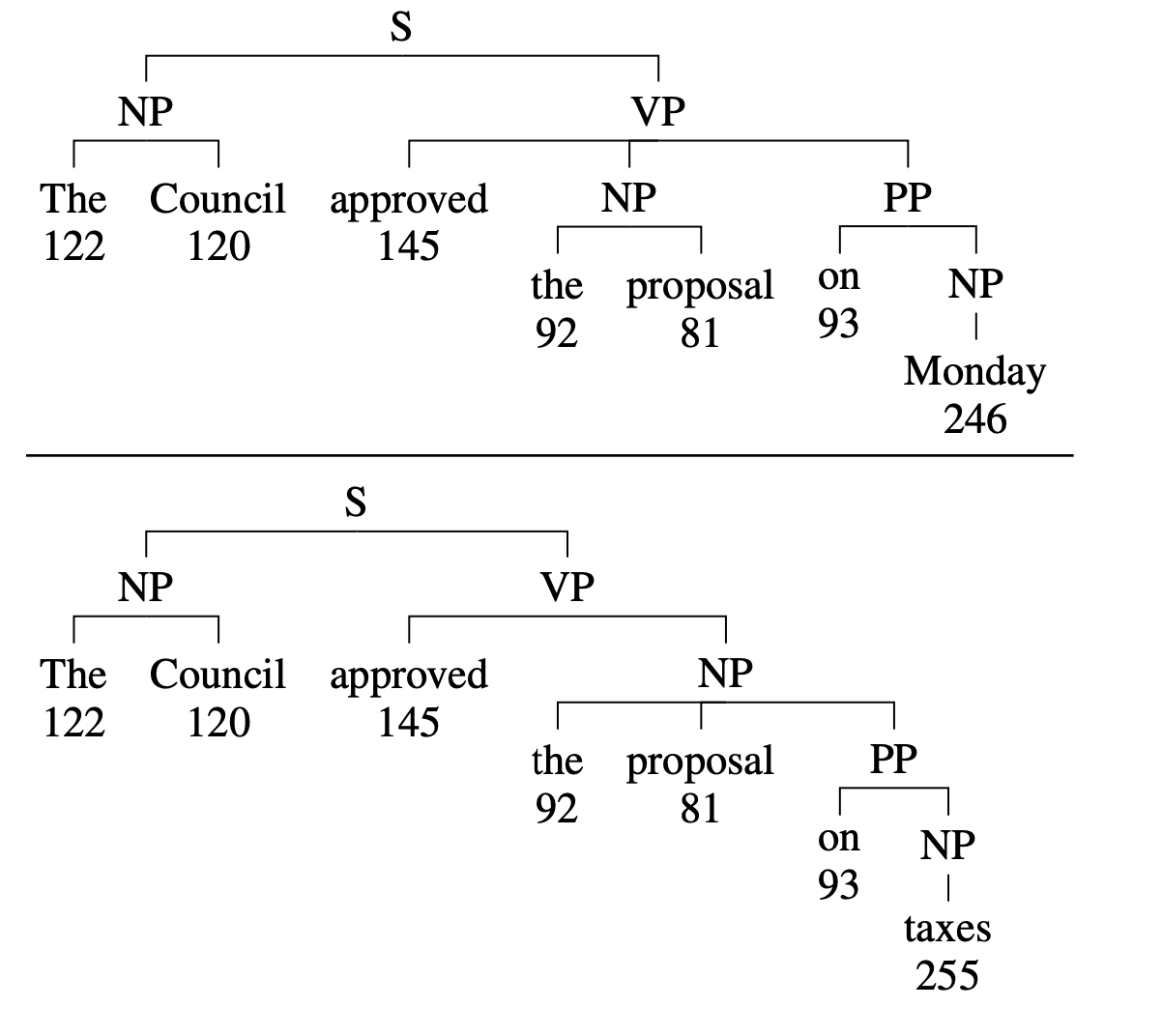
미래의 단어에 따라 다른 트리구성을 가짐 -> 점진적인 표현의 인코딩을 통해 트리를 구성함
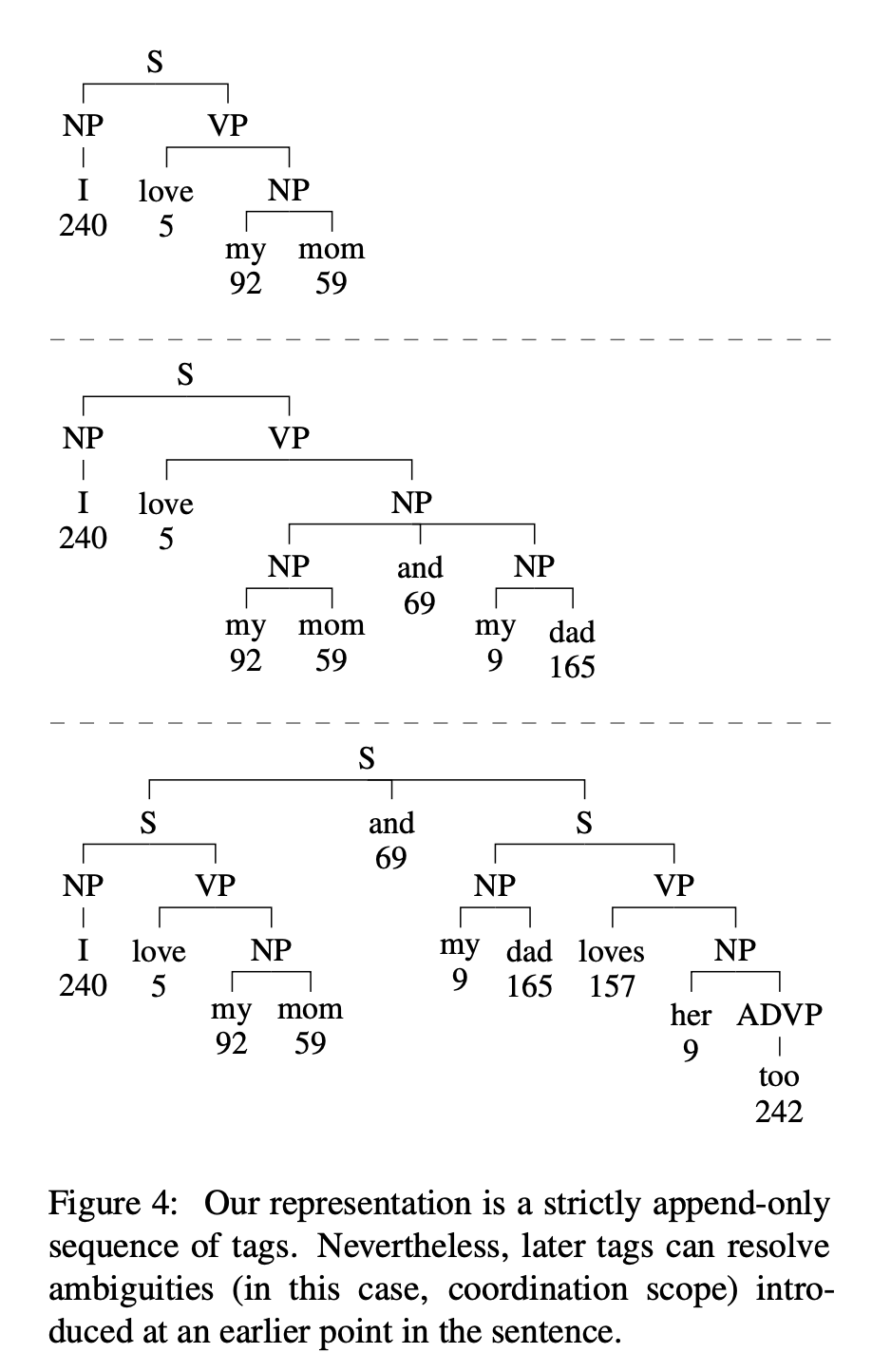
incremental representation은 여러 후보 레이블링을 고려하지 않고 이 상황을 처리할 수 있는 방법에 주목하는 반면, speculative transition-based system은 그렇지 않음
5.2 Entropy of Symbol Distribution (이해못함)
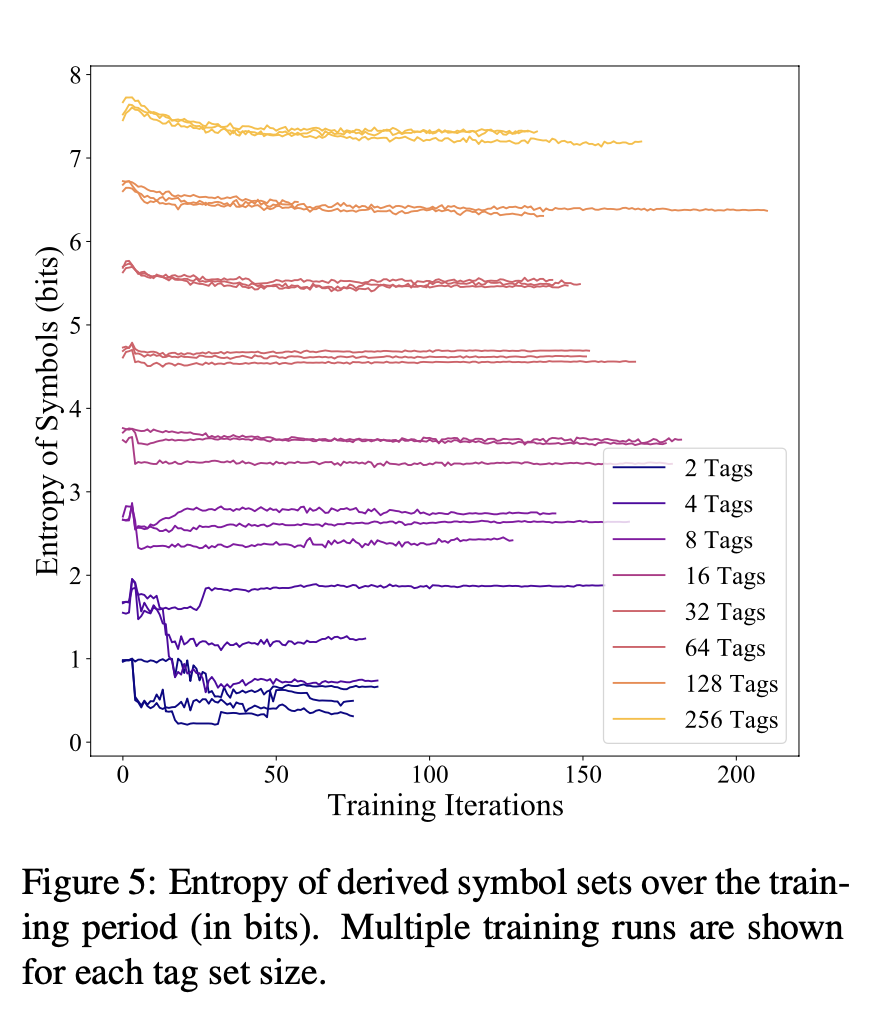
동일한 set size를 가지며 random initialization의 경우, 일반적으로 유사한 featrue이 시스템에 의해 캡처됨
작은 set size를 사용하는 모형은 feature distribution에서 변동성이 가장 큼
엔트로피는 적은 수의 훈련 반복 후에 대략적으로 안정화되는 것으 보임
5.3 Learned Token-Level Features
Information bottleneck에서 서로 다른 크기의 symbol set(2,4,8..256) 세트에 의해 캡처된 특징을 분석함으로써 incremental parsing task와 관련된 고유한 특징을 찾을 수 있음
대략적인 순서
- 명사구와 동사구의 구분
- 새로운 결정자 또는 명사구를 나타내는 기호, 진행 중인 명사구를 끝내는 기호
- 그 밖의 단순한 품사(부사, 부사, 질문, 발음 등)에 대한 특수 기호
- 토큰이 종속절 또는 관계절에 있다는 표시
- 서로 다른 애착을 나타내는 품사(종종 명사, 동사, 전치사)당 여러 개의 기호
- 동사구의 목적어인 절, 또는 관련절 내 명사 등 그 밖의 구체적이고 전문화된 구조의 표시
- 소유 표시, 동명사, 새로운 절을 소개하는 토큰 또는 동사가 아닌 형용사를 수식하는 부사와 같은 기타 특정한 공통 언어 특징
5.4 Clause Separation
이러한 태그에 의해 학습된 모델을 시연하기 위해 32개의 symbol만 사용하는 모델을 고려해 봄
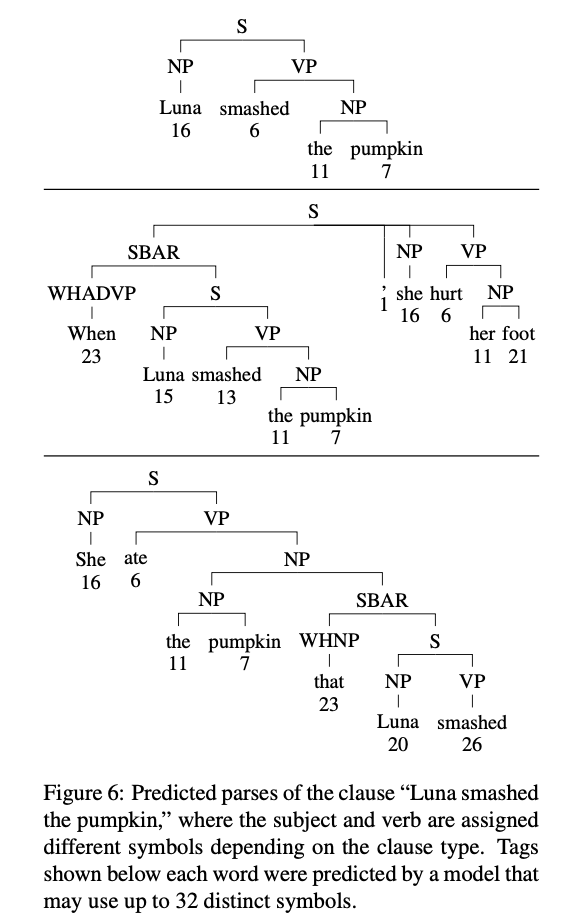
위 그림에서 동일한 단어가 많이 포함되지만 절 유형은 다름
-> symbol set의 이러한 특징은 현재 단어를 넘어서는 구조적 맥락을 포착한다는 것을 시사하며, 이러한 태그에 의해 학습된 특징은 분석 시 인간이 해석할 수 있는 의미를 가짐
5.5 Ambiguity Resolution
우리의 표현이 광범위한 구문 구조를 표현할 수 있는 메커니즘을 더 잘 이해하기 위해, 모호성이 있는 경우에 초점을 맞춰봄
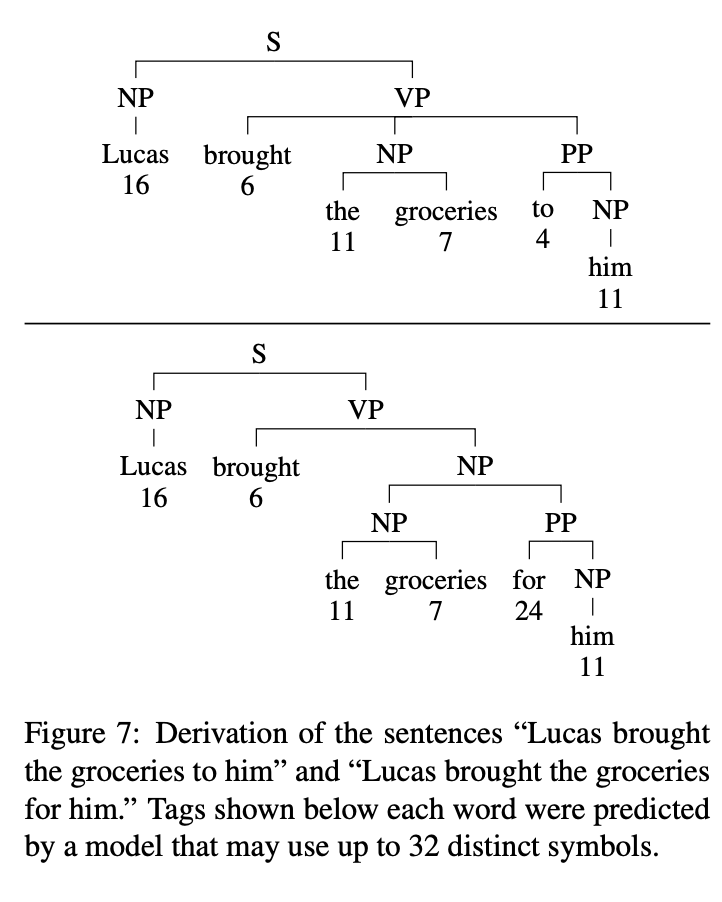
여기서 예측된 구문 구조는 단 하나의 전치사 부착에 의해서만 다르고, 전치사에 할당된 기호가 다르기 때문에 read-out network는 전치사 구문을 다른 높이에 부착함
"추측"을 피하기 위해 태그 시퀀스는 모호성의 인스턴스를 기록한 다음 문자열의 더 아래에 있는 토큰을 기반으로 다시 해결하기 위한 메커니즘을 포함해야 함
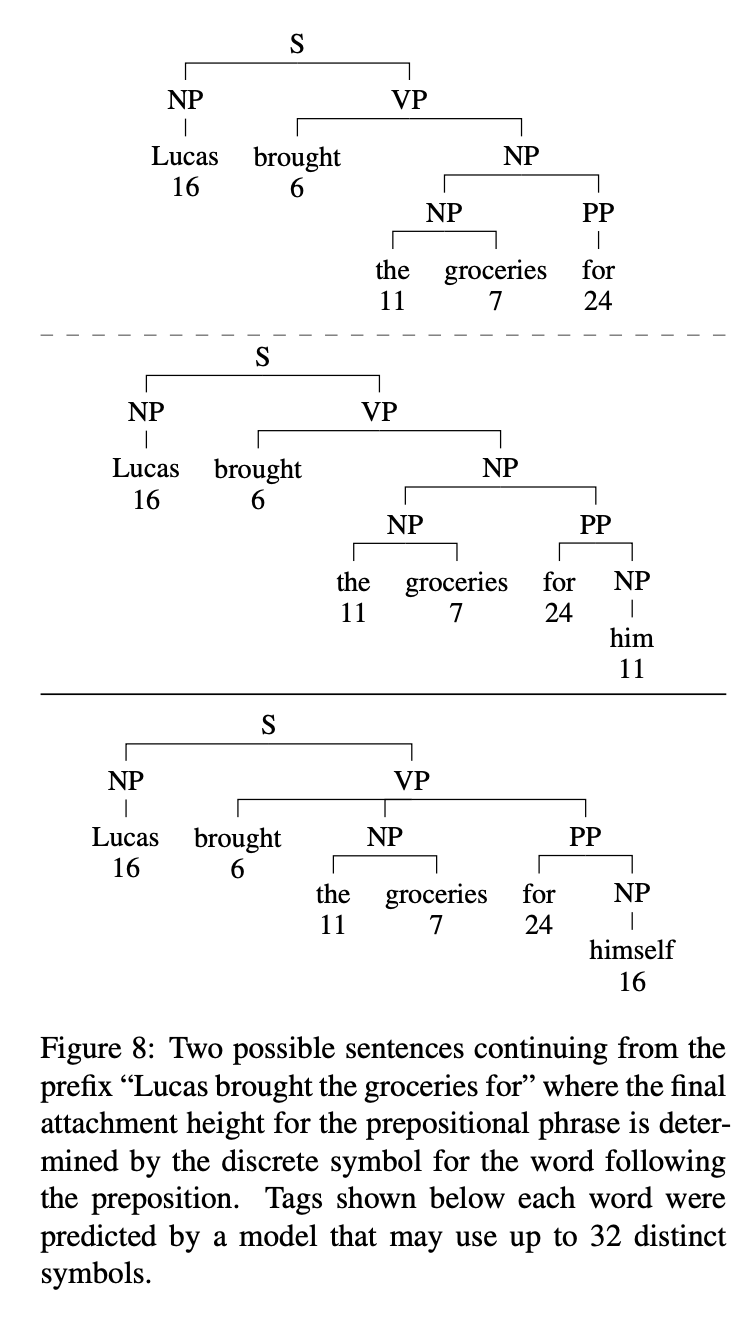
6 Concolusion
본 논문에서는, 입력의 각 토큰을 임의 크기의 어휘에서 discrete symbol과 연결하는 syntatic representation을 유도하는 접근 방식을 제시하며, 여기서 representation은 엄격하게 append-only 방식으로 점진적으로 예측할 수 있음
또한 모델은 각 토큰과 연관될 수 있는 정보를 제한하는 bottleneck에도 불구하고 WSJ 테스트 세트에서 높은 F1을 달성함
이러한 시스템은 incremental parsing과 sequential decision making에 대한 이해를 향상시키는데 도움을 줌
느낀점
- parsing에 대한 모든 개념이 포함되어 있다,, 그래서 배경지식을 알아야 논문을 잘 이해할 수 있다 . . 배경지식이 0이라 정말 이해하느라 힘들었고 이게맞는지 아닌지도 모르겠지만
논문의 모든 섹션에서 incremental representation에 대해 언급하고 방향성을 잃지않게 해줘서 best paper 인듯 하다 .. - unidirectional로 나온 값만으로도 좋은 성능을 달성하고 모델이 복잡하지 않고 간결하다
code
모델에 build에 대한 코드는 x
-main 코드 중 일부-
 bert를 사용
bert를 사용
-모델 불러오고 iparser 사용
iparse.tree_from_cats : cats? 가 뭔지 모르겠슴. .

5개의 댓글

parsing에 대해서 배우고, parsing이 이루어진 데이터셋이 어떠한 형태로 구성되어있는지 배울 수있는 알찬 발표 감사합니다!! 목차가 간결하고 깔끔해서 더더 좋은 것 같아요 !!

parsing에 대해서 예전에 리뷰를 했는데도, 제대로 체화하지 못했었는데 이번 기회에 또 꼼꼼하게 알려주셔서 확실히 알게 됐습니다!!! 그리고 기존 연구와의 차이점, 실험 셋팅마다 해석이 달린 점 등이 참 좋았습니다.

논문의 장점과 단점 : 단점은 왜? 를 붙여서 보자!!
부족하거나 안맞는것 -> 나를 납득시키지 못한 부분을 단점으로 생각하고 뽑아내기