긴 문서에 대한 Robust abstractive summarization을 구축하는 것에는, 얼마나 멀리왔는가?
0 Review
지난 발표에서, Mutual Information Alleviates Hallucinations in Abstractive Summarization에 대해 발표함!
Abstractive Summarization
Text Summarization
- extractive summarization - 추출적 요약
- abstractive summarization - 추상적 요약
- 원문에서 핵심 문맥을 반영해 새로운 문장을 생성해 원문을 요약하는 방식
-> 사람이 요약한 것 처럼 보이고, 추출적 요약보다 난이도가 높음 (NLG영역)
Evaluation
ROUGE라는 automatic metrics를 이용
Hallucinations
-
특정 training corpora에서의 문제를 말함 : ground-truth 요약은 (human summarization) 원문에서 추론할 수 없는 outside information을 포함함
-
model architecture
1 Introduction
pre-trained Transformers는 텍스트를 추상적인 방식으로 요약하는 데 엄청난 진전을 가져옴
extractive summarization과는 달리, abstractive summarization은,
단순히 원문에서 복사하는 것이 아니라, 주요 내용을 지능적으로 바꾸어 원문과 관련된 요약을 생성
하지만, 짧은 문서에서도 abstractive 모델은 반복적이며, 문법적이지 않은 원문과 일치하지 않는 요약을 생성(Hallucination)
또한, 모델 input의 입력 길이 제한으로 인해 긴 문서의 요약에 직접 적용하기에는 어려움이 있음 (token 제한: 1024)
-> How Far are We from Robust Long Abstractive Summarization?
긴 문서, 짧은 문서 상관없이, Robust abstractive summarization system의 조건은,
(i) 고품질 요약을 생성
(ii) 요약의 relevance 와, factual을 비판적으로 평가하는 Metric
-> 하지만, (1), (2)에 대한 연구는 대부분 짧은 문서에 초점을 맞추고 있음
-> 따라서, 본 연구는 긴 문서에서의 abstractive 모델을 분석(1)하고, 평가 척도를 체계적으로 분석(2)
(1) 긴 문서에서의 abstractive summarization model을 분석
하지만, 긴 문서에 대한 모델이 생성한 다양한 요약문이 없는 문제점이 있음
-> 이 논문에서는, BART와 PEGASUS 모델을 arXiv와 GovReport 데이터셋에 구현하여 다양한 요약문을 생성
(대규모 요약 모델에서 가장 효과적인 모델로 밝혀졌기 때문!)
그러나, 이 모델들은 1024개의 token 입력 제한이 있어, 정보손실의 가능성이 생김
-> 이 논문에서는, sparse attention 및 reduce-then-summarize 메커니즘을 활용하여 Longformer 기반 BART와 PEGASUS의 여러 가지 변형을 구현하여 다양한 요약문을 얻음
(2) 모델의 출력물을 3명의 사람이 질적으로(qualitatively)분석하여 relevance와 factual 평가
-> 평가 지표는 모델 성능을 사용자에게 공개하기 전에 비판적으로 평가할 수 있기 때문에 가장 중요함
-> 이 논문에서는, 메트릭을 긴 문서에 맞게 적용함
Contribution
abstractive summarization model과 evaluation metric을 긴 문서(long doc)에서 평가한 첫번째 연구!
2 Related Work
2.1 Long Abstractive Models
긴 문서의 summarization task를 위해 pre-trained Transformers를 사용하려면, 모델의 효율성을 개선하고 입력 제한을 확장하여 긴 문서에 알맞게 변형해야함
Sparse Attention
Transformer의 특정 sequence(token)에 대한 self attention만 계산하게 하여 downstream task에서 긴 입력에 대해서도 사용할 수 있음
Reduce-then-Summarize
원문을 더 짧은 부분으로 줄여서 Transformer의 입력 제한 내에 맞출 수 있도록 하는 것 (주요 문장을 추출하거나 원본의 일부를 사용하여 짧은 텍스트를 생성)
2.2 Evaluation Metrics
summarization의 기본적인 평가인, relevance and factual
-
relevance: 요약이 원문의 주요 아이디어를 포함하는지를 측정함
ex) "새로운 신약 개발로 인한 암 치료 방법의 변화"라는 주제에 대한 요약 결과에서 "암 치료 방법이 개선되었다"는 문장은 중요한 내용을 적절하게 요약 -
factual : 요약이 원문과 사실적으로 일치하는지를 평가함
ex) "암 치료 방법이 완전히 발견되었다"는 사실적인 내용이 아님
3 Generation of Model Summary
3.1 Model Variants
Pretraining Task
BART, PEGASUS를 사용: 두 모델 모두 1,024 입력 토큰 제한을 가지고 있음
-> sparse attention, reduce-then-summarize를 사용해서 입력을 확장
Sparse Attention
Longformer의 adaptation을 사용하여 pre-trained Transformer의 입력 제한을 1K, 4K 및 8K 으로 확장
-> sparse attention을 사용하면 token이 작아지니까, 입력을 확장시킬수 있음!
Reduce-then-Summarize
Oracle retriever을 사용: Transformer에서, ROUGE-2를 최대화하는 방식
Oracle retriever는 정답 요약문을 사용하여 중요한 문장을 추출하는 모델입니다. 이 모델은 훈련과정에서 정답 요약문을 사용하여 추출할 문장을 결정하며, 이를 통해 훈련 과정에서 일종의 "상식"을 배울 수 있습니다. 테스트 단계에서는 이러한 모델을 사용하여 입력된 문서에서 중요한 문장을 추출하고, 이를 요약문으로 만듭니다. 이 방식은 테스트 단계에서는 일반적으로 사용되지 않지만, 연구 목적으로 분석하거나, 기존의 요약 방법과 비교할 때 사용될 수 있습니다.
3.2 Long Document Dataset
넓은 범위의 주제를 다루는 ArXiv와 일반 주제를 다루는 GovReport 데이터셋 사용: 모두 평균 source 길이가 6K개의 토큰을 초과
Krysci´nski et al.´ (2019) 연구에서, CNN-DM 기사의 60%의 가장 중요한 문장이 기사의 1/3에 있다는 것을 밝힘
-> 그러나 짧은 문서의 언어 스타일과 구조는 긴 문서와 다름
-> 따라서, 전체 글에서 가장 앞부분의 텍스트만 처리할 때 모델의 information loss에 관한 실험을 진행
arXiv(700)와 GovReport(100) 테스트 세트에서 무작위로 선택한 10%의 source-summarization pair에 대해 human annotation을 진행
-> 각각의 요약문을 생성하는 데 필요한 개념을 포함하는 곳을 원래 문서에서 leading source 위치를 추적
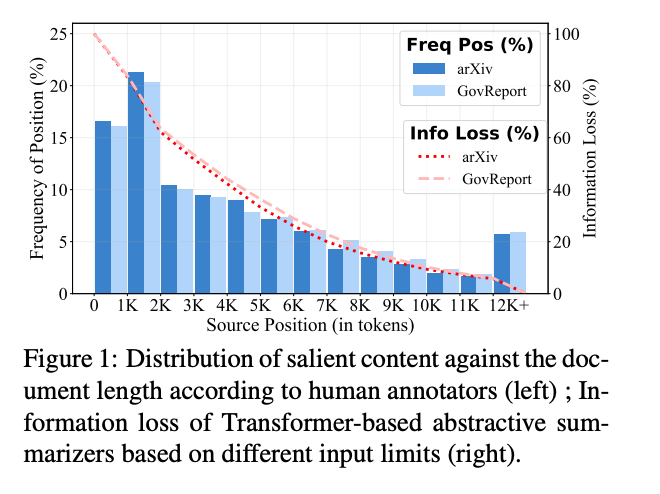 [Figure1]
[Figure1]
-> plot: 전체 출현 percentage에 따른 원본문서에서의 source의 위치
-> 선: 입력 제한이 1K, 4K 및 8K 토큰일 때 각각 약 80%, 40%, 20%의 평균 정보 손실
-> 1K에서 2K 토큰으로 더 많은 중요한 정보가 분포되어 있으며, 0에서 1K 토큰보다 더 많음
-> 하지만, 정보 손실이 많아, 모델이 1K 입력 제한을 처리하는 전략이 최적이 아님!
3.3 Training Details
총 12개의 model per dataset(ArXiv, GovReport)
- 1K, 4K, 8K로 data (3개) x (BART, PEGASUS) (2개) x (Sparse Attention, Reduce-) (2개)
모든 24개의 모델은 512 token output length를 가짐
데이터셋의 train/validation/test 분할은 ArXiv 및 GovReport은 원래의 구성을 따름
3.4 ROUGE Validation
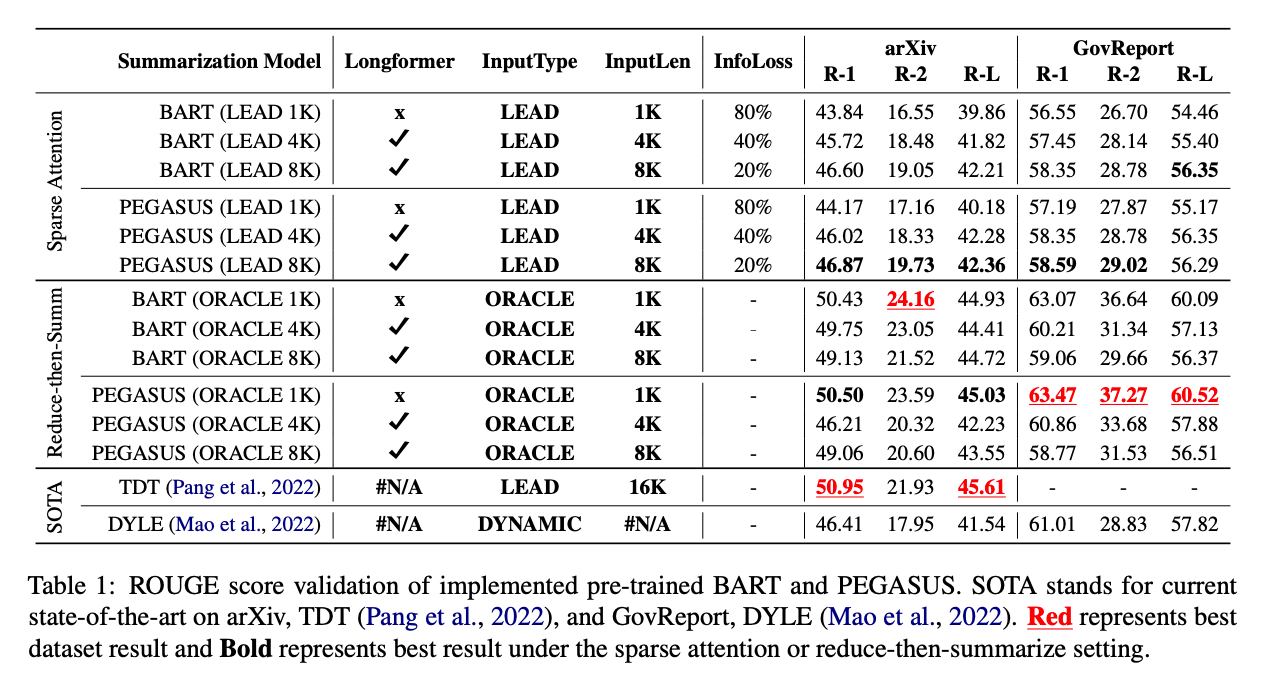
[Table 1]
Sparse Attention 모델은 BART/PEGASUS (LEAD #K)로 참조
Reduce-then-summarize 모델은 BART/PEGASUS (ORACLE #K)로 참조
sparse attention은 주어진 input에서 일부 단어에만 집중하여 계산하는데, 이는 일반적으로 문장의 앞부분에 있는 정보를 더 많이 활용하기 때문입니다. 따라서 sparse attention 모델에서는 일반적으로 주어진 input의 앞부분에 있는 정보만을 요약하는 것이 더 효과적일 수 있습니다. 이에 반해 reduce-then-summarize는 입력된 문서에서 중요한 정보를 추출하기 위해 질문을 하거나 검색을 수행하는 oracle retriever를 사용하여 핵심 단어나 문장을 찾아낸 후, 그것들을 바탕으로 요약을 생성합니다. 이는 입력된 문서의 전체 정보를 고려하여 요약을 생성하기 때문에 보다 전체적인 요약을 생성할 수 있습니다.
- Sparse attention 모델이 state-of-the-art 모델인 arXiv-TDT과 GovReport-DYLE 경쟁력 있는 ROUGE를 달성하지만 더 낮음
- 1K에서 4K 및 8K로 입력 제한이 증가함에 infoloss가 감소하여 성능이 향상
- reduce-then-summarize 모델은 arXiv 및 GovReport의 state-of-the-art와 일치하거나 초과하는 ROUGE를 달성
- 그러나 입력 길이가 증가하면 reduce-then-summarize 모델이 ROUGE를 최대화하기 위해 긴 시퀀스에서 토큰을 식별하는 데 더 많은 부담을 느끼므로 ROUGE가 약간 감소함
-> 위 결과는 sparse attention 모델이 현재의 긴 요약을 잘 반영할 수 있다는 것을 보여주며,
reduce-then-summarize 모델은 arXiv 및 GovReport의 SOTA의 요약 결과를 대략적으로 나타낼 수 있다는 것을 보여줌
4 Human Evaluation of Models
요약문의 전반적인 품질을 평가하기 위해, 우리는 무작위로 각 데이터셋에서 204개의 모델 생성 요약문을 랜덤으로 추출하여 3명의 어노테이터들이 relevance and factual 측면에서 평가하도록 함
-> 하나의 원문에 해당하는 12개의 모델 요약문을 모두 annotation
4.1 Annotation Procedures
Relevance
요약에 원문의 주요 아이디어가 포함되어 있는지 여부를 측정
-> 3명의 평균의 값
Factual Consistency
요약이, 원문과 사실적으로 일치하는지 여부를 측정
Pagnoni et al. (2021)
i) PredE - predicate in summary inconsistent with source
ii) EntityE - primary arguments or its attributes are wrong
iii) CircE - predicate’s circumstantial information is wrong
iv) CorefE - co-reference error
v) LinkE - multiple sentences linked incorrectly
vi) OutE - out of article error
vii) GramE -unreadable sentence(s) due to grammatical errors
-> 3명의 평균의 값
Inter-Annotator Agreement
세 주석자 사이의 관련성 점수의 주석자 간 간격 kappa는 0.5874이며, 각 점수가 분기 간격의 배수에 할당된 Krippendorff의 알파 계수를 기반으로 계산됨
Factual Consistency의 주석자 간 합의를 계산하기 위해, 우리는 다수 클래스에 동의하는 주석자의 Fleiss Kappa, κ, p,를 사용 -> κ = 0.52와 p = 84%
-> human annotator의 일반적인 값보다 살짝 높음!
4.2 Long Abstractive Model Analysis
Relevance
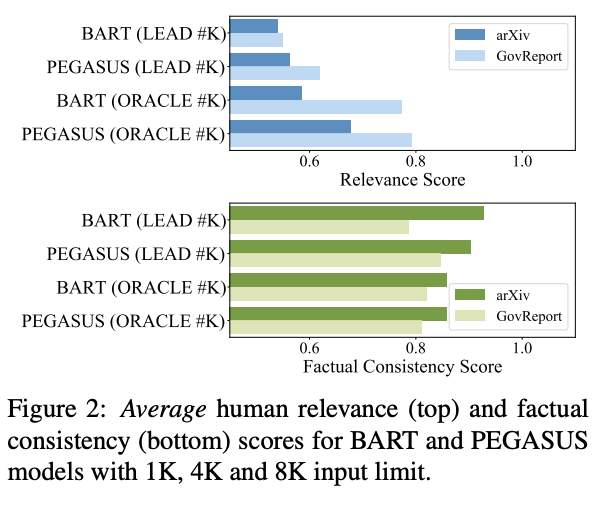
- BART/PEGASUS (ORACLE #K)가 BART/PEGASUS (LEAD #K)보다 높은 점수
- 평균적으로, PEGASUS가 BART보다 성능이 더 좋음
-> BART 모델 + Oracle: 문장 간의 즉각적인 연결이 덜 명확해져 토큰 간의 문맥적 의존성을 이해하는 데 어려움이 있을 수 있다고 추론함
-> PEGASUS 모델: 텍스트의 문맥적 의존성을 추론하는 데 도움을 줌
Factual Consistency
- 평균적으로, PEGASUS가 BART보다 더 적은 factual consistency를 발생시킴
- 또한, BART/PEGASUS (ORACLE #K)는 BART/PEGASUS (LEAD #K)보다 낮음
-> 모델이 관련된 텍스트를 더 쉽게 파악할 수 있지만, 불일치하는 텍스트는 더 많은 사실 오류를 발생시킬 수 있기 때문임
-> 이는 ROUGE를 최대화하는 것이 더 relavance가 높은 요약 모델을 제공하지만, 반드시 사실적이지는 않다는 것을 나타냄!
Summary Quality v.s. Input Limit
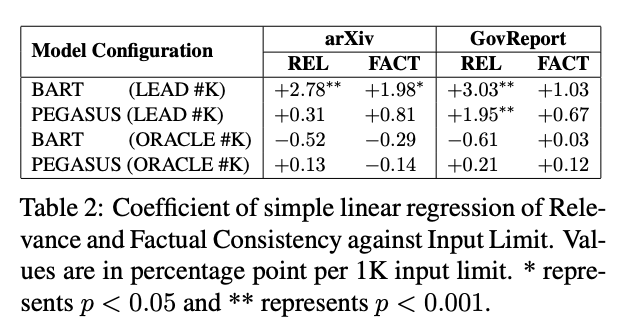
- BART/PEGASUS (LEAD #K) 모델의 입력이 확장되면 relavance가 증가하지만 BART/PEGASUS (ORACLE #K) 모델의 오라클 입력 길이가 조정되어도 의미 있는 차이가 나타나지 않음
-> 긴 오라클 입력 길이는 BART/PEGASUS (ORACLE #K) 모델이 중요한 내용을 식별하는 데 어려움을 겪게 만드는 것임
4.3 Fine-grained Analysis of Factual Errors
가장 적은 오류는 arXiv에서 PEGASUS (LEAD 8K) (21%) 및 GovReport에서 PEGASUS (ORACLE 1K) (60%)에서 발생함
factual의 오류의 수가 너무 많아서, 모델이 만든 오류 유형과 그 성능을 향상시키는 방법을 분석하는 것이 더 중요함

i) PredE - 요약문에 있는 동사와 원문에 있는 동사가 일치하지 않음
ii) EntityE - 주요 인자 또는 해당 속성이 잘못됨
iii) CircE - 동사의 상황 정보가 잘못됨
iv) CorefE - 참조 오류
v) LinkE - 여러 문장이 잘못 연결됨
vi) OutE - 글 밖 오류
vii) GramE - 문법 오류로 인해 읽을 수 없는 문장들
-
arXiv 기사는 데이터셋 도입시 전처리되어있으며, GovReport 기사는 원래 문서와 유사함
-> 따라서 CorefE, EntE 및 CircE와 관련된 오류는 크게 줄어듬 -
BART/PEGASUS (ORACLE #K)가 대개 주요 입력 텍스트보다 덜 일관성 있는 텍스트를 사용하므로 LinkE 오류가 더 많이 발생한다는 것
-
또한 다시 한번, PEGASUS가 BART보다 더 나은 성능을 보이는 것 확인함
-> PEGASUS의 더 나은 성능은 대개 CorefE, EntE, GramE, PredE 오류가 더 적게 발생하기 때문
ROUGE 점수는 BART와 PEGASUS 사이에 미미한 차이를 보이지만, human evaluation 결과 PEGASUS가 BART보다 훨씬 우수한 것으로 나타남
-> 긴 문서에서는, ROUGE 지표에만 의존하지 않고 요약 사용자가 판단에 기반하여 요약 평가를 수행해야 한다는 필요성을 강조
5 Human Evaluation of Metrics
inconsistency 비율이 높은 경우, long abstractive summarization model은 실제 세계에서 사용하지 못함
따라서, 평가 메트릭을 긴 문서 환경에 적용하고, 평균 human relavance와 factual점수의 상관관계 평가
General Metric
요약의 전반적인 질을 평가하는 메트릭: relavance, factual 을 평가
-> 이 논문에서는, BLEU, ROUGE, METEOR, BERTScore, BARTScore과 같은 일반적인 메트릭을 사용함
-> 또한, 8K 토큰으로 확장된 Longformer를 사용하여 BARTScore의 zero-shot 버전(BARTS-ZS)과 fine-tuned 버전(BARTSFT)을 사용
Factual Consistency
factual consistency metrics
- OpenIE: source와 summary에서 semantic triples를 추출한 후, embedding matching을 통해 점수를 계산
- FactCC: weakly-supervised model 접근 방식을 채택
- FEQA와 QUAL: question-generation and answering (QGA) 접근 방식을 사용하여 factuality를 평가
- TE-MNLI와 : text entailment 접근 방식을 사용하여 document-level에서 entailment의 확률을 평가
- SummaC: sentence-level에서 entailment를 평가
5.1 Overall Result
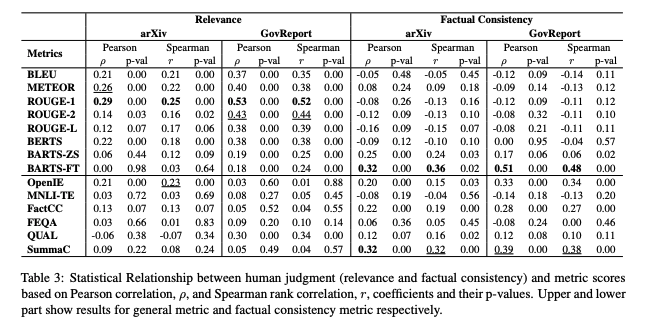
Relavance
사람의 판단과, ROUGE 점수가 가장 높은 상관관계를 갖음
-> 관련성이 높은 요약을 생성하는 긴 문서 추상화 모델의 벤치마킹을 위해 ROUGE 측정 항목에 의존할 수 있도록 안정성을 제공함
요약 작업에서 사람 평가와 메트릭 간의 상관 관계가 0.3 이상이면, 높은 상관 관계를 가진다고 할 수 있습니다. 하지만, 이는 일반적인 지표일 뿐이며, 상황에 따라 달라질 수 있습니다. 따라서, 가능한 한 많은 평가를 수행하여 높은 신뢰도를 보장하는 것이 좋습니다.
Factual Consistency
사람의 판단과 가장 높은 상관 관계를 가지는 측정 항목은 fine-tuned BARTScore, SummaC, FactCC, OpenIE
-> 효율성 측면에서, BARTScore와 FactCC는 RTX 3090 GPU에서 약 4일의 세부 조정을 필요로 하지만, zero-shot SummaC와 OpenIE는 데이터셋 특정 조정 없이 즉시 구현할 수 있음
-> 따라서, 모든 측면을 고려했을때 SummaC와 BARTS-FT가 가장 효과적인 metric
5.2 Identification of Factual Error Types
Factual Consistency의 전반적인 상관 관계는 측정 항목이 다른 유형의 사실적 오류를 식별하는 데 제한이 있음을 나타내지 않는다는 것이 이 연구의 주요 결론 중 하나
사람들이 작성한 요약문의 사실적인 정확성을 판단하는 상관관계에는 위에서 본 것 처럼 여러 metric이 있지만, 하나의 metric만으로는 다양한 종류의 오류를 잘 판단하지 못할 수 있음
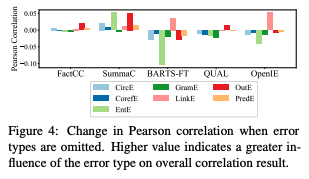 [Figure 4]
[Figure 4]
각 방법이 어떤 종류의 오류를 잘 판단하는지를 나타냄
예를 들어, BARTScore와 OpenIE 방법은 문장 사이의 연결 오류(LinkE)를 잘 판단하지만, 개체 오류(EntE)를 잘 못 판단함
-> 이러한 한계를 극복하기 위해 다양한 방법을 조합하여 사용하는 것이 좋음
-> BARTS-FT와 SummaC 방법의 점수를 평균하여 사용하여 arXiv의 최상의 Pearson 상관 관계 결과를 32%에서 38%로, GovReport의 결과를 51%에서 59%로 향상시킴
6 Conclusion
이 연구에서는 모델과 메트릭의 관점에서 장문 요약 시 문서의 적절성과 사실일치성을 비판적으로 분석하기 위해 모델이 생성한 요약에 대한 인간 평가를 수행함
모델에 대해서는 ROUGE 점수를 높이기 위한 지속적인 노력이 요약의 관련성을 높이지만 반드시 사실일치성을 보장하지는 않는 장문 모델로 이어진다는 것을 강조하며, PEGASUS 사전 학습은 사실적인 오류를 더 적게 만들고 불일치한 텍스트를 더 잘 이해할 수 있기 때문에 장문 요약기에서 보다 유용할 수 있음을 시사함
메트릭에 대해서는 ROUGE가 요약의 관련성을 평가하는 데 가장 우수하다는 것을 관찰하며, 인과관계와 함께 미세 조정된 BARTScore가 장문 요약의 사실성을 평가하는 데 가장 효과적일 수 있다는 것을 보여줌
또한 우리의 일상 생활에서 신뢰할 수 있는 장문 요약화 시스템을 개발하기 위한 미래 연구에 대한 실질적인 통찰력을 제공할 수 있기를 희망함!!
7 느낀점
- summarization에 최근에 관심이 생겼는데, short 와 long에 대해서 자세히 분석해준 논문! 처음부터 끝까지 어렵지 않은 내용으로 long doc summarization에 대해 알 수 있었다
- 왜? 라는걸 생각하지 않고 읽은 논문 -> 최초의 연구라고 강조강조를 해서 배운다는 느낌으로 읽었음
- human evaluation과 machine metric의 상관관계를 비교하는 아주 좋은 논문
- EMNLP에 낼만하다~



Text data를 처리하다 보면 input 문장이 길어지는 경우가 많은데 Sparse Attention과 reduce-then-summarize 방식을 모델에 적용하면 좋을 것 같아요 ~ 그리고 generation task에서 생성한 문장의 사실 여부가 굉장히 중요하다고 느껴지는데 이 논문에서의 factual consistency metrics로 이를 검증할 수 있음을 알아갑니다 !