Mutual Information Alleviates Hallucinations in Abstractive Summarization (EMNLP, 2022)
paper review
Mutual Information Alleviates Hallucinations in Abstractive Summarization
-> 추상적 요약에서 환각을 완화하는 상호 정보
1) Mutual Information Alleviates Hallucinations in Abstractive Summarization
Abstractive Summarization
Text Summarization
- extractive summarization - 추출적 요약
- abstractive summarization - 추상적 요약
-
extractive summarization
추출적 요약: 원문에서 중요한 핵심 문장 또는 단어를 뽑아 구성된 요약문을 만드는 방식 -> 이 방식을 통해 만들어진 문장이나 단어는 모두 원문에 있는 문장 - TextRank
-
abtractive summariaztion
추상적 요약: 원문의 문서에서 핵심 문맥을 반영해 새로운 문장을 생성해 원문을 요약하는 방식 -> 사람이 요약한 것 처럼 보이고, 추출적 요약보다 난이도가 높음 - NLG영역
참고
2) Mutual Information Alleviates Hallucinations in Abstractive Summarization
Hallucinations : 환각
Hallucinations in nlp?
-> generated content that is nonsensical or unfaithful to the provided source content (from wiki)
-> 제공된 소스 콘텐츠에 대해 터무니없거나 불성실한 생성 콘텐츠
ex) ChatGPT
Q: 한국 팀은 2002년 월드컵에서 어땠니?
ChatGPT: 대한민국 대표팀은 한국과 일본이 공동 주최한 2002 피파 월드컵에서 준결승전까지 진출했어. 4위로 마무리되었고, 이게 대한민국 팀이 역대 월드컵에서 이룬 최고의 성과지. 토너먼트에서 이탈리아, 스페인, 포르투갈을 이기다가 준결승전에서 독일에게 졌어.
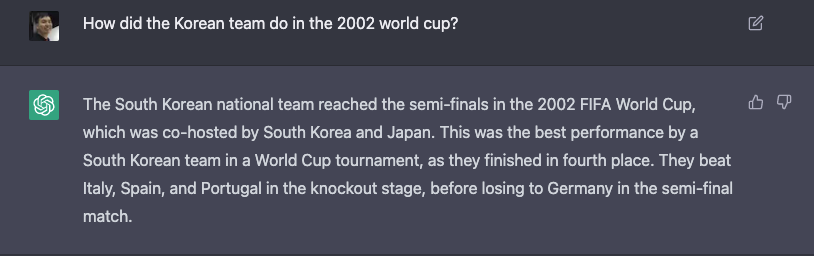
FACT!
벤투 감독이 뛰었던 포르투갈은 조별리그 3차전에서 한국에게 지고 2002년 토너먼트 진출에 실패함
hallucination 참고 링크
즉, 사실 관계와 상관 없이 그럴듯한 문장을 계속해서 지어냄!
== 제공된 소스 콘텐츠에 대해 터무니없거나 불성실한 generated content
3) Mutual Information Alleviates Hallucinations in Abstractive Summarization
-> 추상적인 요약을 생성할때 (NLG) 생기는 환각현상에 대해 완화를 할 수 있는 Mutual Information에 대해 설명하겠구나!
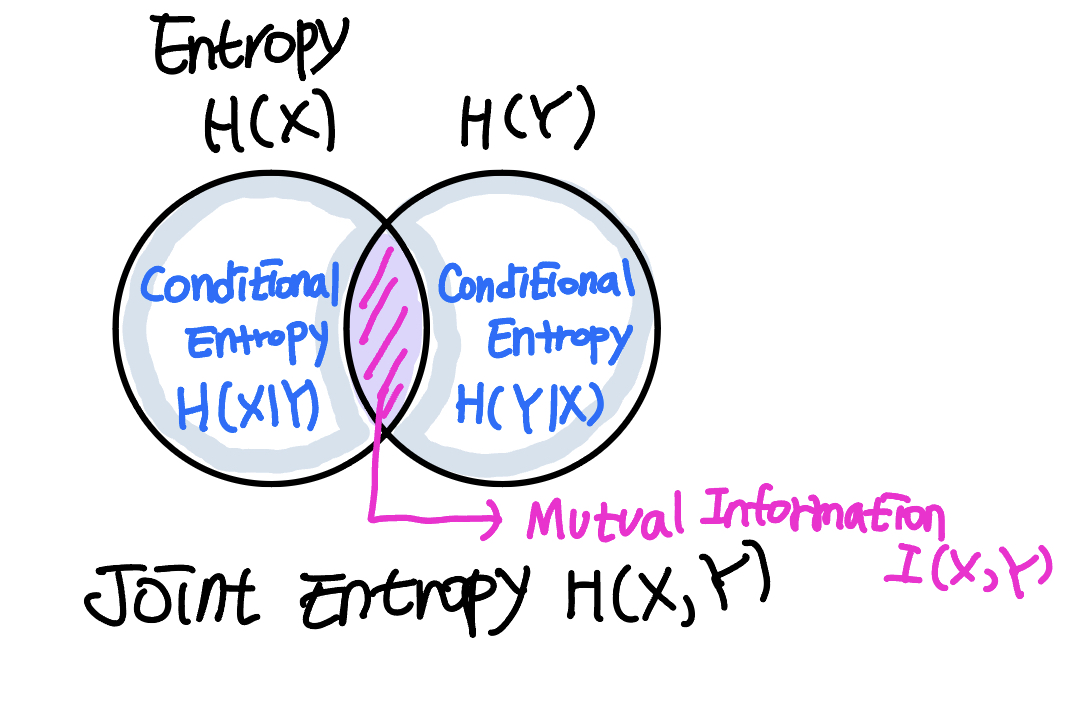
Mutual Information
- Entropy: 정보량을 나타내는 평균 최소 자원량
- 확률이 큰 사건을 효율적으로 표현하기 위해서는 자원을 적게 쓰고,
그에 비해 확률이 작은 사건을 효율적으로 표현하기 위해서는 상대적으로 많은 자원을 사용!
Mutual Information Alleviates Hallucinations in Abstractive Summarization
-> 추상적인 요약을 생성할때 (NLG) 생기는 환각현상에 대해 완화를 할 수 있는 자연어 data(문장,단어등)에 대한 연관성인 Mutual Information에 대해 설명하겠구나!
Index
1 Introduction
2 Preliminaries
3 Finding and Combating Hallucinations
4 Related Work
5 Experiments
6 Conclusion
1 Introduction
긴 문서를 짧게 요약하는 작업인 abstractive summarization은 유창하고 사람같이 text를 생성하는 probabilistic text generation등의 모델이 있음
-> 하지만, 이러한 모델은, 원문에 없는 정보를 output에 추가하는 환각을 발생시킴
왜 환각이 발생할까?
-
특정 training corpora에서의 문제를 말함 : ground-truth 요약은 (human summarization) 원문에서 추론할 수 없는 outside information을 포함함
-
model architecture
-> 이러한 문제점이 있지만, 환각을 식별하고, 자연어 생성 과정에서 환각을 예방하기 위한 기술은 존재하지 않음
-> 따라서 본 논문에서는, 1) 모델이 원문에서 나오지 않은 단어에 (환각에), 높은 확률을 할당할 가능성이 있는 경우를 알아차리는 간단한 기준을 제공
가정 : 생성되는 환각이, training corpus에 자주 나타나는 토큰에 확률 질량을 배치하는 모델의 경향 때문일 수 있음!
2) 또한 자연어 생성 중, 환각이 나오는 시작에 대해, 다음 토큰에 높은 model uncertainity 부여
(조건부 엔트로피로 나타냄)
*model uncertainity: 모델이 데이터의 어떤 특징을 학습하는지에 대해 모르는 정도
*조건부 엔트로피: 주어진 이전문장에 대한 다음 토큰의 probability
-> 아! 그럼 여기서 mutual information이 적용되겠구나!
시작되는 토큰과 다음 토큰에 대한 mutual information을 적용하겠구나!
또한, summarization을 위한 decoding은, 순수하게 generation은 확률에 최적화되기 때문에 환각을 가진 generation 는 여전히 candidate가 됨!
-> 따라서, 대안적인 디코딩 전략을 제안
: 모델이 높은 불확실성을 보일 때, 원문과 target 토큰(환각을 일으키는 token)간의 pointwise mutual information로 decoding objective를 변경해서, 모델이 원문과 관련된 token의 우선순위를 지정하도록 권장함
보통의 LM decoding objective : standard log-probability
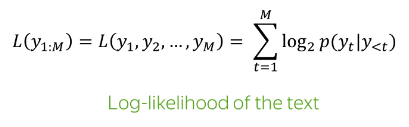
PMI objective로 완전히 변경하면 ROUGE-L 점수가 3.13% 감소하지만, 조건부(모델의 높은 불확실성일때) 변화 는 FACTS 점수 메트릭에 따라 사실성을 증가시키면서 ROUGE-L 점수가 0.977% 감소
2 Preliminaries
abstractive summarization의 Probabilitic model
- distribution : p(y|x)
-x: source document
-y: <y0,y1,....,yT>인 token sequence
y0=BOS
yT=EOS
yt -> 0<t<T인 model의 vocabulary
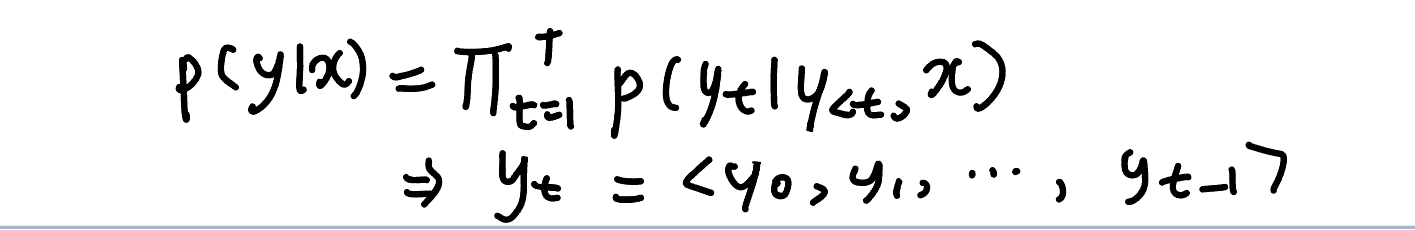
특정 t에 생성된 yt의 token은, 이전까지 생성된 token들과 원문을 고려해서 token-by-token으로 autoregressive하게 생성

token이 sequence로 만들어지는 방식은 beam search를 이용
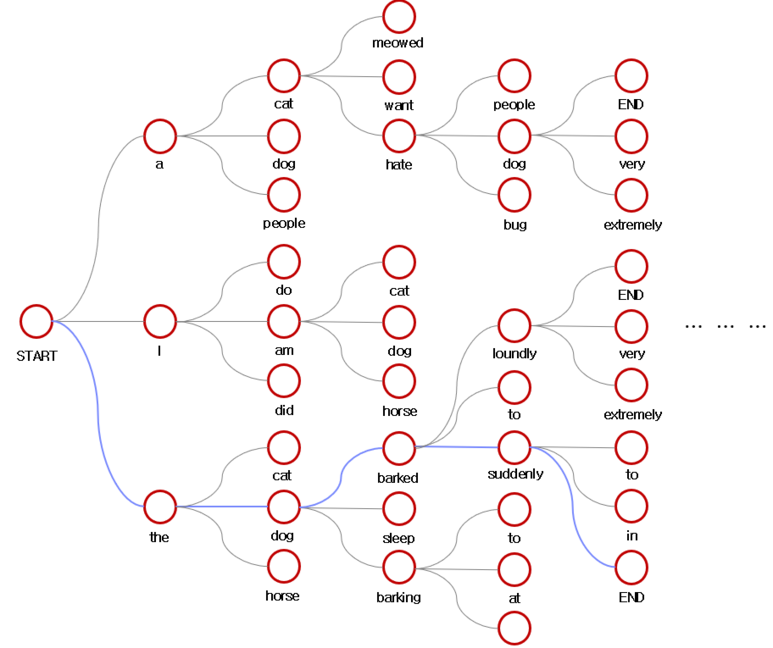

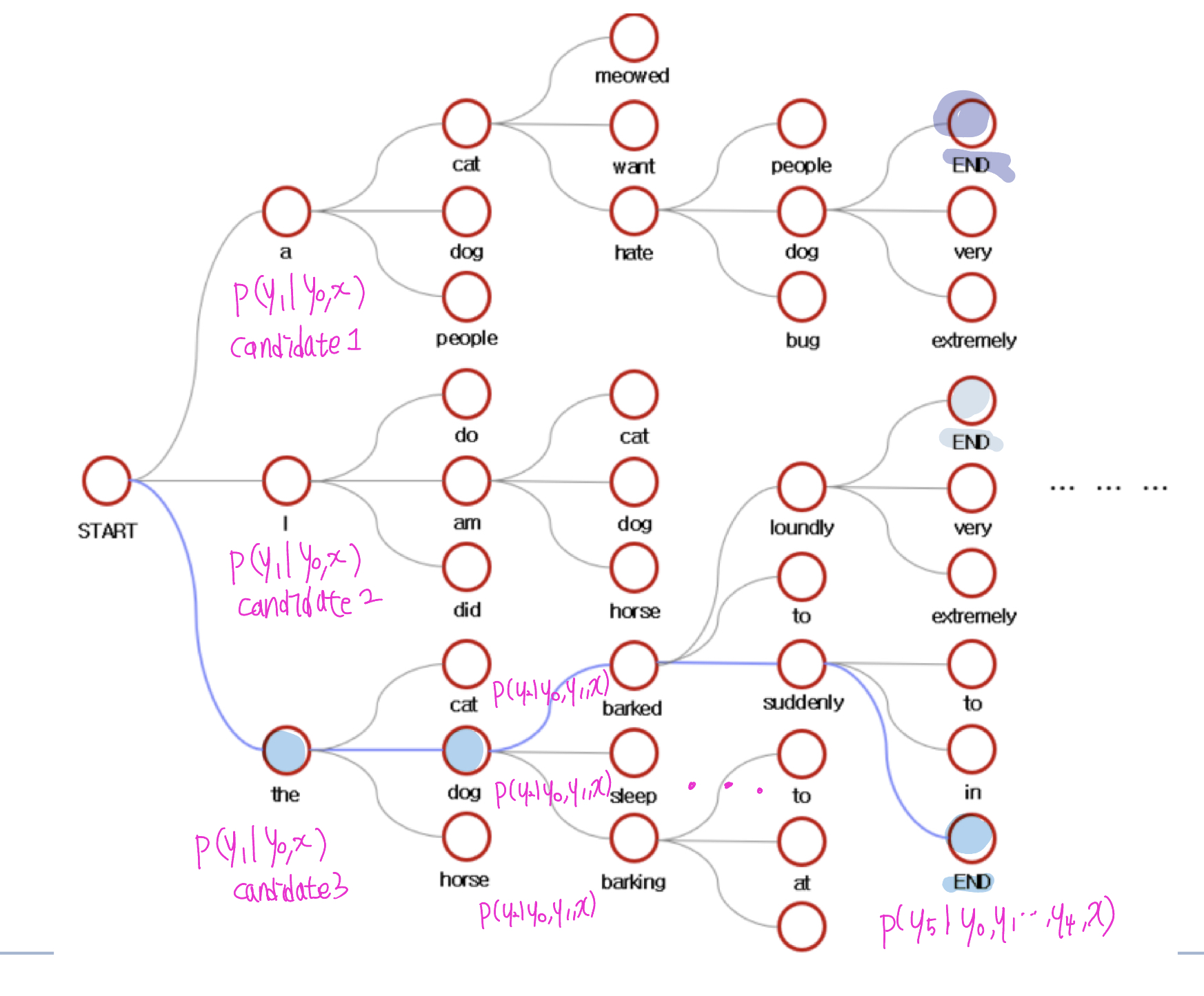
가장 누적확률이 높은것이 문장이 됨!
Evaluation.
Abstractive summarization task는 ROUGE라는 automatic metrics를 이용
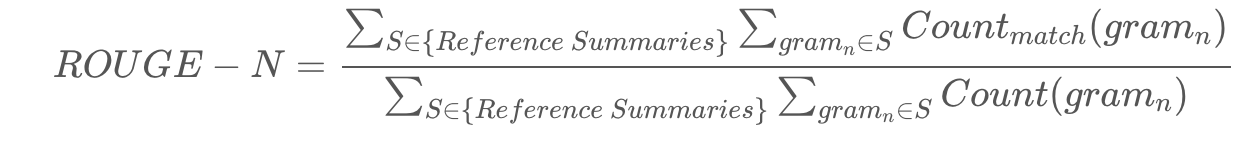

ROUGE-L: LCS 기법을 이용해 최장 길이로 매칭되는 문자열을 측정
ROUGE 참고
PMI objective로 완전히 변경하면 ROUGE-L 점수가 3.13% 감소하지만, 조건부(모델의 높은 불확실성일때) 변화 는 FACTS 점수 메트릭에 따라 사실성을 증가시키면서 ROUGE-L 점수가 0.977% 감소
왜 감소가 될까 ?
-> 환각이 아닌 단어도 환각으로 인식할 수 있음
3 Finding and Combating Hallucinations
summarization model의 환각을 만들어 낼 때 시점, 즉, unfaithful한 연속에도 높은확률을 두기 시작할 때는 언제일까?
NLP 모델은 기본적으로, training 중에 관찰되지 않은 유형의 data를 예측할 때, 확률질량이 큰 = 빈번하게 나오는 토큰에 그 data를 매칭시킴!
또한 이러한 환경에서의 모델은 높은 불확실성을 가짐
-> 따라서 summarization model은, hallucination을 높은 score로 측정할 수 있지만 전혀 관련이 없는 token일 수 있다는 것을 추정함
-> 이 연구에서, 환각을 만들어 내는 시점이 높은 모델 불확실성과 관련이 있다고 가정함
구체적으로 모델 불확실성을 정량화하기 위해 조건부 분포로 특정 time t에 대해, Shannon 엔트로피에 대한 표준 방정식을 사용
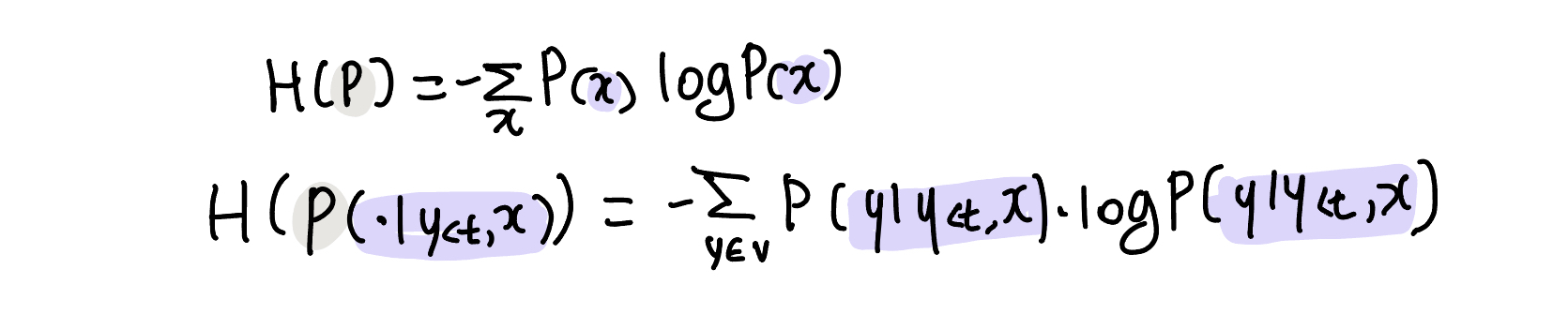
왜 shannon?
-> Entropy는 uncertainity를 측정하기에 가장 알맞은 방법은 아니지만, 이전 summarization연구에서 모델의 uncertainity를 측정하는 지표로 사용해왔음! (+논문참고)
-> 즉, token의 probability를 standard log로 나타내지 말고 shannon entropy를 활용하자!
-> 그러면 모델의 uncertainity를 알 수 있고, 그러면 환각을 만들어 내는 시점을 알 수 있다!
3.1 Pointwise Mutual Information Decoding (==Beamsearch와 같은 역할)
이러한 환각 문제점을 해결하기 위해, decoding 중에 mutual information을 최대화 할 것을 제안하여 그 환각에 penalty를 도입
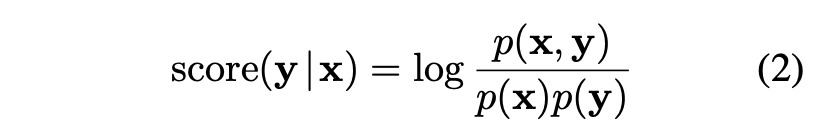
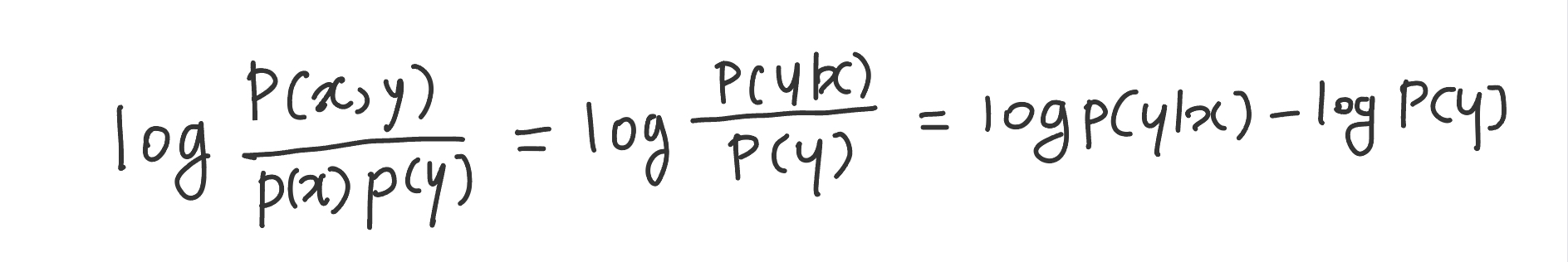
토큰별로 알아야 해서 포인트별로 최적화 시킴! -> PMI(포인트별 상호 정보)에 대해 반복적으로 최적화!
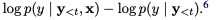
그리고, 이 논문에서 제안하는 조건부(모델의 높은 불확실성일때) PMI 디코딩(CPMI)은 주어진 시간 단계에서 조건부 엔트로피를 사용하여 포인트별 디코딩 목표를 변경해야 하는 시기를 나타냄
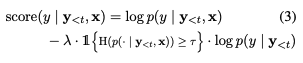


4 Related Work
Decoding to avoid hallucinations.
- keyword-based methods
- focus attention mechanism : token과 source의 단어가 비슷할때 biase를 줌
Mutual information decoding.
- 이 논문이 mutual information을 최초로 활용함: abstractive summarization에!
5 Experiments
Data.
XSUM dataset
Models.
TRANS2S
BARTS2S
Decoding.
CPMI
beamsearch
2개의 hyperparameter 선택 - minmax optimization
(min-probability, max - ROUGE-L) 500 example사용해서 최적 파라미터 선정
Evaluation.
5.1 Preliminary Analysis
생성된 자연어 데이터에 대해 토큰이 환각인지 아닌지의 여부와
환각이 포함되어있는 sequence의 첫번째 토큰을 알아보기 위해,
XSUM에 human summarization이 없는 데이터로 summarization을 만들고, 또한 reference summarization 10832개 수집
평균적으로 summarization의 엔트로피는 첫 번째 환각 토큰의 경우 비환각 토큰에 비해 더 높음
TRANS2S의 경우 4.197±0.065 vs 3.689±0.021
BART2S의 경우 3.115±0.051 vs 2.390±013
-> 환각이 모델의 불확실성과 연관될 수 있다는 것을 시사함
그리고 환각의 시작은 조건부 엔트로피가 특정 임계값 이상일 때 확인할 수 있음
5.2 Results
How are performance and factuality metrics impacted by CPMI?
CPMI를 통해 성능과 메트릭의 변화는?
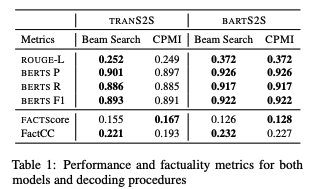

-> BARTS2S : Beam Search와 CPMI 차이가 없음
-> TRANS2S : beam search와 견줄만한 CPMI!
FactScore 점수는 증가하지만, FactCC는 감소
-> FactScore은 XSUM에 대해 특별히 훈련된 모델을 사용
-> FactCC는 CNN/DM에 대해서 훈련된 모델을 사용
따라서, FactScore을 더 나은 지표로 받아들여야함!
What happens to known unfaithful tokens when scored under CPMI?
-> CPMI에서 점수를 매겼을 때 unfaithful token은 어떻게 될까?
모든 objective를 log-probability에서 CPMI로 바꿨을 때의 변화
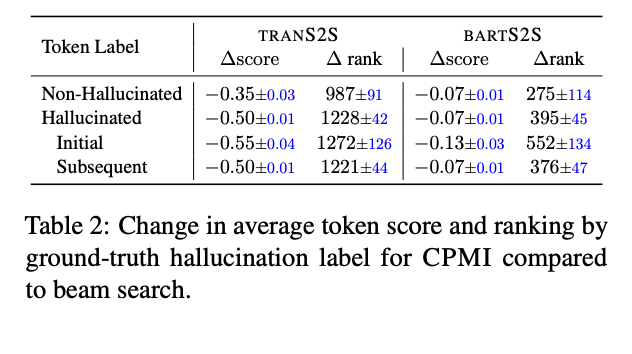
-> 환각 상태의 토큰의 경우 점수가 감소하고 순위가 상승
-> BARTS2S의 Initial vs non-hallucinated 에서 점수가 감소하고 순위가 상승
-> 또한 non-hallucinated 또한 감소됨
하지만 적절한 임계값을 선택했을때, PMI는 환각이 없는 토큰에서는 작동하지 않을 가능성이 크니까, CPMI로 변경하였을 때를 걱정하지 말자!
6 Conclusion
abstractive summarization의 generation에서, 환각의 시작을 높은 조건부 엔트로피로 정량화하여, 모델 불확실성을 측정하고, 다음 토큰과 연결함!
모델 불확실성이 높을 때 환각을 방지하기 위해, 디코딩 objective를 pointwise mutual information으로 전환하는 CPMI 제안!
-> 고품질 요약을 출력하면서 negative 토큰을 생성할 가능성을 줄임
Limitation
영어 dataset에서만 했음
다른 모델과 다른 데이터셋에 대해서도 실험이 필요
After Review
왜 Mutual Information을 선택했는지에 대한 이유가 안나옴
-> 확률 모델에서 가장 많이 쓰이나?
-> 정보이론과 nlp와의 관계에 대한 언급이 있었으면 이해하는데 좋았겠다!
-> 예시만이라도!!
또한 Mutual Information의 개념에 대해서 설명하지 않아서 어려웠다라고 생각했는데, 식만 이해해도 됐었다 !
환각의 예에 대해 설명해줬으면 좋았겠는걸 ..
Code
https://github.com/VanderpoelLiam/CPMI#statistics-for-probability-of-hallucinated-tokens
제가 코드를 못찾는건가요 ??
Shannon Entropy되는 부분 찾고싶었는데요 ..


4개의 댓글

Introduction까지 읽었을 때 논문이 어떤 점을 말하고 있는지 이해하는데 어려움이 있었는데 발표를 통해서 환각에 대해서 어떠한 관점에서 연구를 수행했는지 보다 쉽게 이해할 수 있어서 좋았습니다! 좋은 발표 감사합니다~~

background 설명, 수식 설명 등이 상세하게 잘 되어 있어서 좋았습니다! 논문 설명이 잘 되어서 이게 좋은 논문이라는 점도 잘 들어왔어요!

생소한 분야였는데, 이번 기회에 알게 되어서 너무 뜻깊었습니다. 논문 자체도 구성이 너무 훌륭해서 배울 점이 많았고, 그걸 더 알기쉽게 설명해주셔서 도움이 많이 되었습니다. 감사합니다!
때마침 ChatGPT가 생성하는 가짜 정보들에 대해서 한참 떠들썩했어서, 왜 모델이 그런 정보들을 생성할까 궁금했어요 ! 오늘 발표하신 이 논문이 딱 그 궁금증을 해결해주어서 넘 재밌게 들었습니다. 본격적인 논문 설명 이전에 용어 하나하나 짚어가며 설명해주셔서 좋았습니다 ! 손으로 주석을 달아서 이해 도운 것도 넘 좋았어요 ! 감사합니다 ^ㅁ^