Improving Faithfulness in Abstractive Summarization with Contrast Candidate Generation and Selection (NACCL, 2022)
paper review
0 Background
Improving Faithfulness in Abstractive Summarization with Contrast Candidate Generation and Selection
1) Faithfulness
<-> Hallucination
summarization model의 환각을 만들어 낼 때 시점, 즉, unfaithful한 연속에도 높은확률을 두기 시작할 때는 언제일까?
2) Abstractive Summarization
<-> extract Summarization
제목의 뜻은, Abstractive Summarization에서 hallucination을 없애기 위해 Contrast Candidate Generation and Selection 을 이용할 것!
1 Introduction
Abstractive Summarization은 간결하고 유창한 요약을 생성하는 작업으로, 원문에 faithful한 요약을 만들어내는 것
그러나 생성된 요약의 faithfulness, 즉 원문에 제시된 정보와 일치하는 요약을 생성하는 것을개선하는 데는 그렇게 많은 진전이 이루어지지 않음
ROUGE 또는 BERTSCORE metric에서의 성능이 향상되었음에도 불구하고, SOTA 모델은 intrinsic, extrinsic hallucination을 만듬
intrinsic hallucination
원문에 있는 정보를 사용하여 내용을 합성하는 과정에서 발생
원문에서 사용된 용어나 개념을 사용하는데, 원문의 정보를 잘못 표현하여 문서에 충실하지 않은 요약을 생성
extrinsic hallucination
원문에서 등장하지 않은 단어를 사용하여 요약에 생성

[Table 1]
BART가 생성한 요약
- 원문: 반기문이 2011년에 재선되었다는 내용
- 요약: 반기문이 2007년에 재선됨
-> 따라서, 본 연구에서는 hallucination을 post processing step으로 수정하는 문제에 초점을 맞춤 (후처리)
post processing step: Contrast Candidate Generation & Selection
1) Generation: 정답 요약에서 named entity를 원문에 있는 의미 유형과 비슷한 것으로 대체하여 후보 요약을 생성
2) Selection : 원문을 기반으로 생성된 후보와 faithful 요약을 구별하기 위해 discriminate 모델을 사용하여 생성된 후보를 순위화 함
RNN, tranasformer 기반의 다양한 추상적 요약 모델에서 실험을 진행함
Contributions
1) extrinsic hallucination이 발생하는 경우에 대해 Contrast Candidate Generation and Selection을 조사한 첫번째 연구
2) XSum에서 훈련된 model에서 발생하는 일반적인 유형의 hallucination에 대해 자세한 분석을 제공
2 Contrast Candidate Generation & Selection
본 연구에서는 extrinsic hallucination의 대부분의 named entitiy와 수의 entitiy에서 발생한다는 개념에 기반함
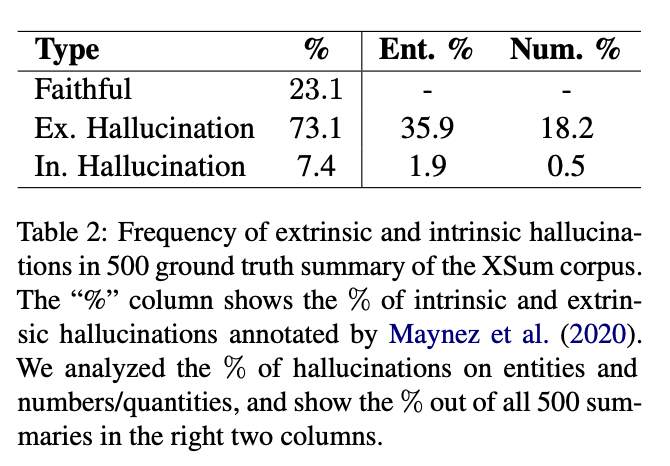
[Table 2]
XSum 코퍼스에서 임의로 추출한 500개의 gold 요약(정답 요약)에 대한 인간 분석 결과

-> train data의 hallucination이 다양한 요약 모델에서 생성된 출력에 유사한 문제를 초래한다는것 때문에, entity/숫자 hallucination을 수정할 수 있는 post processing step을 연구함
-> 이 문제를, correction으로 정의하였고, 이것은 더 summarization보다 더욱 적은 훈련 데이터가 필요함
2.1 Contrast Candidate Generation
1 step) 모델이 생성한 요약에서, 원문과 유사한 형태인 entity들을 확인함으로써 hallucination(entity/number)을 확인함
-> OntoNotes corpus에서 훈련된 Stanza NLP의 nerual NER 시스템을 사용하여 원문과 요약에서 다른 의미를 가지는 named entity를 추출함
ex)
Source : Samsung Electronics is planning to launch a new smartphone next month...어쩌구저쩌구 기사내용
Summary: A tech giant is set to release its latest smartphone soon.
원문과 요약에서 다른 의미를 가지는 named entity : Samsung Electronics, tech giant
2 step) 요약에 있는 named entity는 동일한 NER 레이블이 있는 원문의 다른 entity로 대체됨
ex)
Source : Samsung Electronics is planning to launch a new smartphone next month...어쩌구저쩌구 기사내용
Summary: A tech giant is set to release its latest smartphone soon.
원문의 다른 entity(NER label: 조직) : Samsung Electronics, Apple Inc, NVIDIA ...
3 step) 이를 통해, 원문과 비슷한 다양한 변형 요약을 얻을 수 있지만, faithful하지는 않을 수 있음
ex)
1. A Samsung Electronics is set to release its latest smartphone soon.
2. An Apple Inc is set to release its latest smartphone soon.
3. A NVIDIA is set to release its latest smartphone soon
4. ...
2.2 Contrast Candidate Selection
후보 선택 단계에서는, 이전 단계에서 생성된 변형 요약 중에서 최종 출력 요약으로 가장 적합한 후보를 식별
Contrast 후보는 요약에서 몇 가지 토큰만 다르기 때문에, 올바른 후보를 선택하려면 더 섬세한 boundary를 잘 알아차리는 섬세한 모델이 필요함!
따라서, 그런 모델을 만들기 위해서는 traning data가 필요함
-> training 데이터를 생성하기 위해, XSum data에서, ground-truth 요약의 모든 entity가 원문에 나타나는 데이터들만 샘플링
그런 다음, generation 단계에서와 동일한 절차를 따름
1)
Source : Samsung Electronics is planning to launch a new smartphone next month...어쩌구저쩌구 기사내용
Ground-truth Summary: A Samsung Electronics is set to release its latest smartphone soon.
2)
Samsung Electronics, smartphone -> Apple Inc, device..
3)
An Apple Inc. is set to release its latest device soon.
A Samsung Electronics is set to release its latest smartphone soon.
...
-> ground truth 요약 + syntheiszed 요약으로 점수를 매기고 순위를 매겨, discriminate한 Object로 text classifier을 학습시킴
이때 text classifier는 BART에 linear layer(classifier)을 추가한 모델을 사용
L_xe-> crossentropyloss, L_RANK-> pos/neg margin(pos에 더 많은 가중치를 주기 위해)
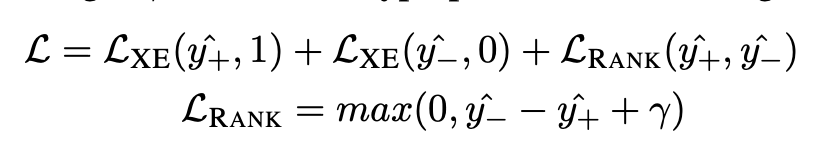
data로 train한 모델의 test 단계에서는, score를 매기도록 output이 나옴 -> 최종 요약으로 높은 점수를 받은 후보를 사용!
3 Experiments
XSum 코퍼스로 훈련된 BART 모델이 생성한 요약을 사용
- 후처리(Generation & Selection)를 사용하여, 모델이 생성한 요약 중 13.3%를 변경함
- 38.4%는 모델의 요약에 환각적인 개체가 없음 / 원문에서 대체될만한 NER 없음
- 48.3%는 모델의 요약을 유지하기로 결정
3.1 ROUGE and BERTSCORE Evaluation
본 논문에서 제시된 후처리 방법이, fluency와 salience에 영향을 미치지 않는지 확인: ROUGE, BERTSCORE가 적합한 지표라고 가정하여 점수를 매김
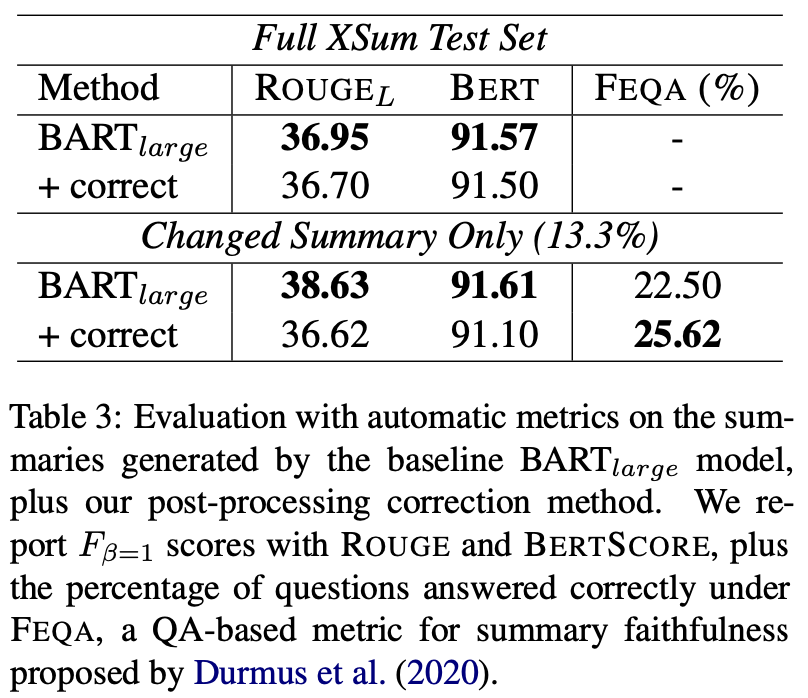
[Table 3]
ROUGE와 BERTSCORE 모두에서 잘 수행됨
그러나, 약간 뒤쳐지는 수치
-> 이는 ground-truth 요약에 extrinsic hallucination이 존재하기 때문!
3.2 Faithfulness Evaluation
본 논문에서 제시된 후처리 방법이, 요약의 Faithfulness를 향상시킬 수 있는지 테스트하기 위해, FEQA를 사용하여 요약을 평가함
FEQA는 요약의 Faithfulness를 평가하기 위한 QA 기반 지표
:주어진 요약에 대해, 요약에서 명사와 named entity에 대한 질문을 자동으로 생성하고, pre-trained QA 모델을 사용해서 원문에서 유도된 답변이 요약에서 정확히 일치하는지 확인하는 작업
원문: The company announced a partnership with Apple to develop a new line of smartwatches.
요약: The company partnered with Apple to create smartwatches.
FEQA 질문: 어떤 회사와 협력하여 스마트워치를 개발하였나요?
FEQA 답변: Apple
FEQA는 요약에서 추출된 명사나 named entity에 대한 질문을 생성하고, 원문에서 추출된 답변과 요약에서 추출된 답변을 비교하여 일치 여부를 판단합니다. 위의 예시에서는 FEQA가 "어떤 회사와 협력하여 스마트워치를 개발하였나요?"라는 질문을 생성하고, 원문에서 추출된 답변 "Apple"과 요약에서 추출된 답변 "Apple"이 일치하는지를 확인합니다. 이를 통해 요약의 충실성을 평가할 수 있습니다.
[Table 3]
후처리로 수정한 1510개 요약 각각에 대해 질문에 대한 정확한 답변의 백분율을 계산한 결과
-> 수정된 요약이 원래 요약보다 통계적으로 유의한 개선을 보여줌

[Table 4]
수정된 요약의 무작위로 추출된 95개에 대한 human analysis
-> 두 명의 전문가 주석가가 각 요약을 3가지 범주로 할당
-> 그런 다음 세번째 전문가의 추가 주석을 사용하여 주석가 간 합의를 계산
-> 결과에서 볼 수 있듯이, 후처리 방법은 Faithfulness를 향상시킬 수 있지만, 그 과정에서 intrinsic hallucination을 일으키며 실수를 함!
4 Analysis and Discussion
4.1 Identifying Hallucination Across Systems
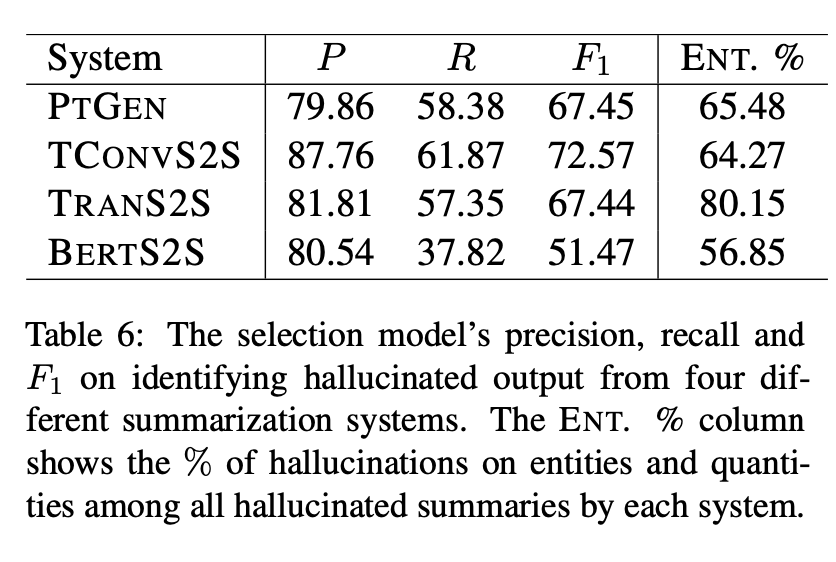
[Table 6]
모델에 따라 생성된 요약문에서 정밀도(Precision), 재현율(Recall), F1 점수(F1 score)를 측정한 결과
이 실험에서는 Maynez 연구(2020)에서 제공한 testset 사용
-> PTGEN, TCONVS2S, BERTS2S, TRANS2S 모델이 생성한 요약문에서 hallucination 카테고리의 주석을 달은 testset
후처리 방법은, 각 모델에 일관된 높은 정밀도를 보임
- 모든 hallucination 중에서 entity/number이 상대적으로 높은 비율이 있었다는 것을 의미
- hallucination은, 주로 entity와 number에 초점을 맞추었기 때문에 각 요약 시스템이 얼마나 많은 entity, number hallucination을 만들어 냈는지에 따라 recall이 달라 질 수 있음
- 또한, 서로 다른 요약 모델들은 서로 다른 종류의 환각을 생성하므로 전체적인 재현율이 다를 수 있음
4.2 Intrinsic vs. Extrinsic Hallucinations Trade-off

[Table 5]
앞서 언급했듯이, extrinsic환각은 낮아지고, intrinsic환각이 높아질 수 있음
예를 들어, 이 시스템은 원문에 해당 entity가 없을 때 환각된 entity에 대한 올바른 대체어를 찾지 못할 수 있음
BERTS2S, BART와 같은 pretraining 모델들이 이 문제에 가장 많이 영향을 받음
-> 이는 pre-training에서 발생하는 artifacts/priors에 영향을 받기 때문
4.3 Entity Faithfulness is not combined with Summary Faithfulness
모델들이 원문에서 올바른 대체어가 없는 entity를 환각하는 것을 관찰한 결과, entity의 faithfulness만 해결한다고 해서 요약문의 충실성이 보장되지 않을 수 있다고 의심함
[Three]CARDINAL → [Two]CARDINAL fugitives have been arrested and charged with attempting to smuggle drugs into the country.
이 예시에서, BERTS2S는 "three"라는 숫자가 원문에서 명시적으로 언급되지 않았음에도 불구하고 원문에서 설명하는 이벤트에 3명의 도망자가 관련되어 있음을 정확하게 식별함
이것은 Abstractive summarization 모델이 실제 세계에서 확인 가능한 사실적인 문장을 생성하므로, 진짜 hallucination을 식별하기 위해서는 상식적 추론과 지식 검색과 같은 더 복잡한 목표가 필요하다는 것을 시사함
따라서 이 후처리 시스템은, entity/number에만 초점을 맞췄으므로 전체 문제를 해결하기에는 충분하지 않음
5 Conclusion
- summarization이 instrinsic, extrinsic hallucination으로 고통받는다는 전재하에서, entity/number에 관한 hallucination에 post-processing 을 적용하는 방법으로 Candidate generation & selecdtion을 제시함
6 느낀점
- post-processing 만으로도 hallucination의 비율이 적어진다는것에 대해 아주 큰 감명을 받음.. 간단한 방법으로 가정, 실험, 결과가 일치하면 이렇게 좋은 논문이 나올 수 있구나..
- 이 논문을 잘 이해하려면 On Faithfulness and Factuality in Abstractive Summarization 이 논문을 우선 이해하는게 필요함! Related work에 자세히 설명해주었으면 좋았을 것 같다..
- Summarization Task인데, 다른 논문에 비해 예시가 적은것 같음!!
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("CogComp/bart-faithful-summary-detector")
model = AutoModelForSequenceClassification.from_pretrained("CogComp/bart-faithful-summary-detector")
article = "Ban-Ki Moon was re-elected for a second term by the UN General Assembly, unopposed and unanimously, on 21 June 2011"
bad_summary = "Ban Ki-moon was elected for a second term in 2007"
good_summary = "Ban Ki-moon was elected for a second term in 2011"
bad_pair = tokenizer(text=bad_summary, text_pair=article, return_tensors='pt')
good_pair = tokenizer(text=good_summary, text_pair=article, return_tensors='pt')
bad_score = model(**bad_pair)
good_score = model(**good_pair)
print(good_score[0][:, 1] > bad_score[0][:, 1]) # True, label mapping: "0" -> "Hallucinated" "1" -> "Faithful"
감사합니당 🙇🏻♀️

2개의 댓글

간단한 post processing을 진행하여 entity와 숫자에 대한 extrinsic hallucination을 해결하는 재미있는 논문이었습니다. 재미있게 잘 들었습니다.
오늘도 재밌는 논문 설명 잘 들었습니다 ㅎㅎ
사실 모델을 개선하는 방식의 논문들을 많이 접했었는데 이렇게 후처리를 통해서 접근한 게 재밌네요! 또한 실험에 대한 적절한 분석으로 이 논문에서 하고 싶었던 내용을 뒷받침을 잘 해서 간단한 방법임에도 충분히 설득력 있었던 논문 같아요!
한 학기동안 summarization task의 가장 큰 문제인 헐루시네이션에 대해서 다뤄주셨는데 넘 재밌었고 좋았습니다 고생하셨습니다 🍀🧚♂️