
기초부터 쌓아가는 머신러닝 #1
1주차 : pandas 라이브러리 기초 실습
- google colab(코랩) 환경구성 및 기본 사용법
- google colab(코랩)이란 무엇인가?
- google colab(코랩)은 구글 클라우드 기반의 무료 혹은 유료 Jupyter 노트북 개발 환경이다.
- 내부적으로 colab + google drive + docker + linux + google cloud로 이루어졌다.
- google colab의 장점이 무엇인가?
- 무료로 사용가능하다.
- 환경 설정 구축이 간단하다.
- 동시에 여러명이 수정 가능하다.
- 인터넷을 통해 사용가능하여, 따로 프로그램 설치가 필요없다.
- 성능이 좋다.
- 특정 오류 발생에 대한 디버깅이 쉽다.(stack overflow)
- google colab의 단점은 무엇인가?
- 최대 세션 유지시간은 12시간으로, 반응이 없으면 자동으로 세션 끊긴다.
- 세션이 만료되면 학습중이거나, 저장되어있는 데이터는 소멸된다.
- 하지만, 2가지 방법을 통해서 세션 만료의 걱정을 덜 수 있다.
1. google colab pro 사용
- 더 좋은 GPU 할당
- 고용량 RAM 사용 가능
- 더 긴 런타임
2. 크롬 브라우저 창 => F12(개발자 도구) => console
function ClickConnect() {
var buttons = document.querySelectorAll("colab-dialog.yes-no-dialog paper-button#cancel");
buttons.forEach(function(btn) {
btn.click();
});
console.log("1분마다 자동 재연결");
document.querySelector("#top-toolbar > colab-connect-button").click();
}
setInterval(ClickConnect,1000*60);- Google Colab 환경 구성
- 구글 계정 가입
- https://drive.google.com 접속 및 왼쪽 상단(내 드라이브) 폴더 만들기
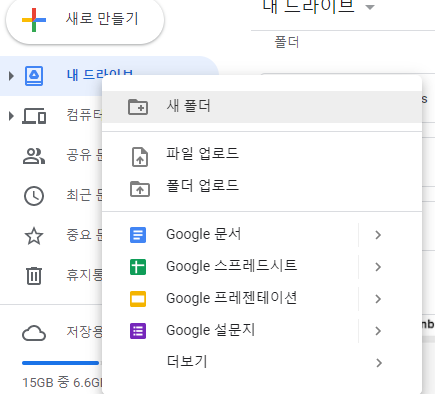
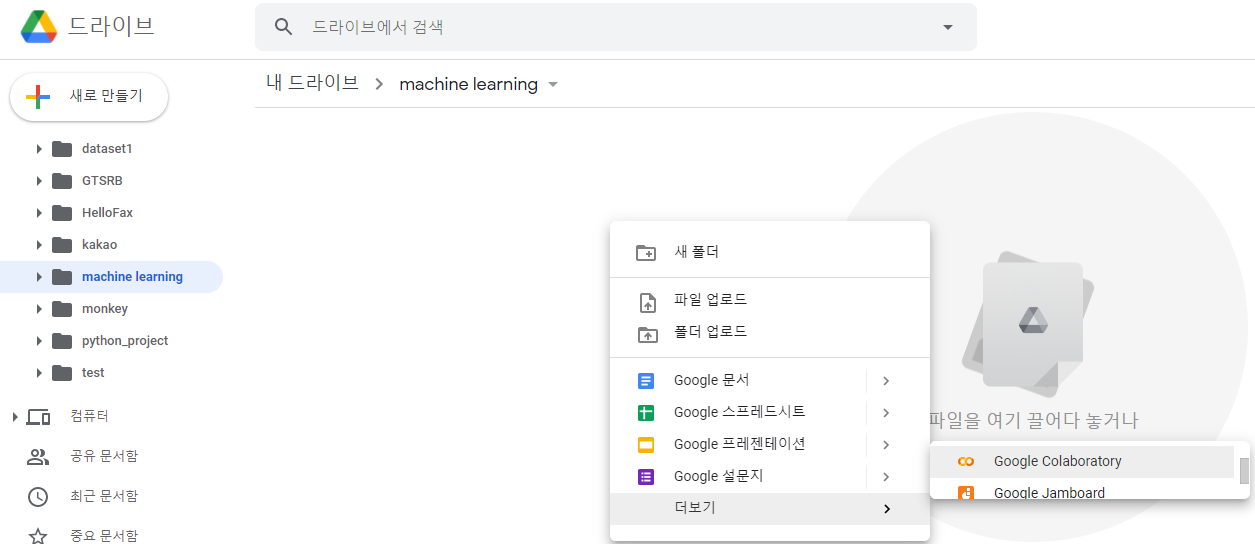
- 왼쪽 상단 +새로만들기 => 더보기 => 연결할 앱 더보기
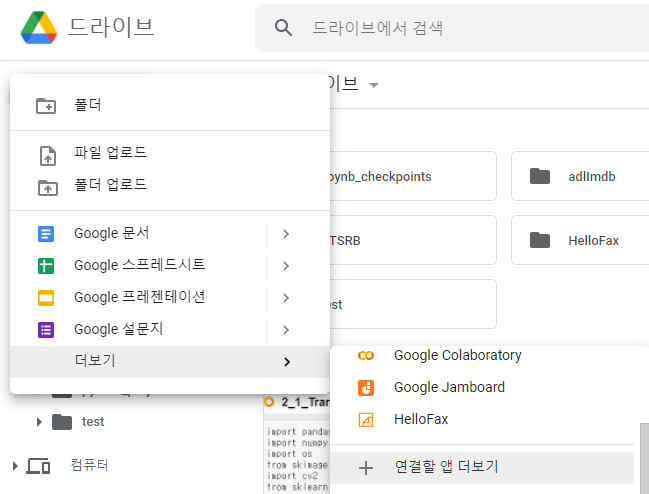
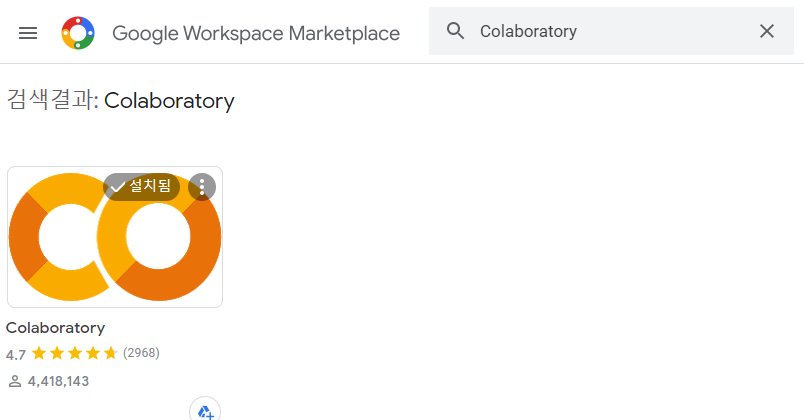
- colaboratory 검색 => 연결하기 혹은 설치
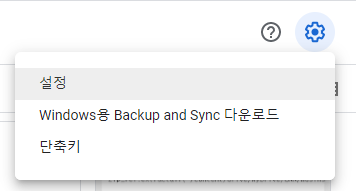
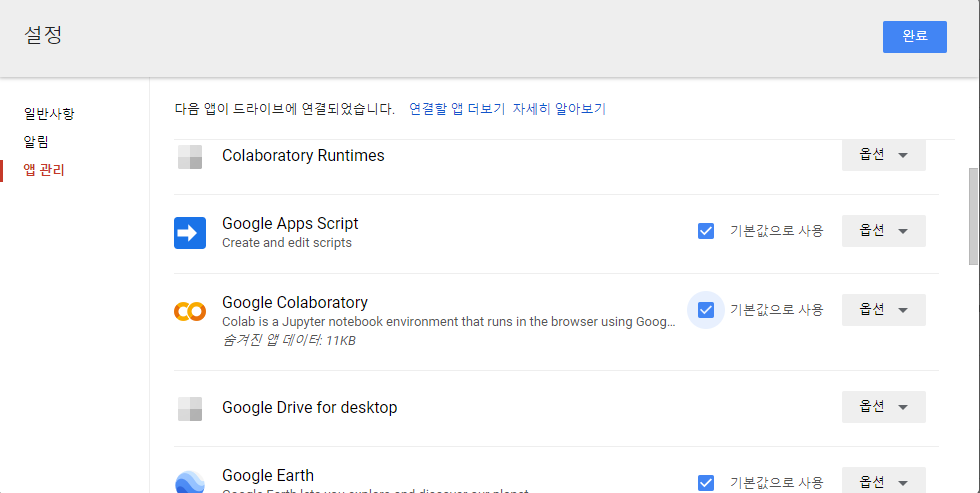
- 메인화면 => 톱니바퀴 모양 => 설정
- 앱관리 => Google Colaboratory 기본값으로 사용 체크 => 완료
- 내가 만든 폴더 선택 => 오른쪽 마우스 클릭 => 더보기 => Google Colaboratory 선택
- 최상단 '노트설정' 클릭 => 코드줄 생략 취소 및 확인 => 메인페이지 연결 클릭 => 제목 변경
- 판다스(pandas)란 무엇인가?
- 판다스는 데이터 분석을 위한 핵심라이브러리로써 고유한 자료구조인 Series와 DataFrame을 활용하여 빅데이터 분석에 엄청난 수준의 퍼포먼스를 발휘한다.
- Series와 DataFrame는 numpy(선형대수)의 1차원 2차원 array와 유사하다.
- 간단한 차이점이라고 하면, array에 index가 있는 형태라고 볼 수 있다.
- 데이터 불러오기 및 저장
- 드라이브 마운트
- 좌측 폴더 모양 클릭 => 드라이브 마운트 폴더 클릭 => 구글 드라이브에 연결 => 계정 선택 => 완료 - 연습 데이터 url : https://drive.google.com/drive/folders/149jcCyJFKKG5MFaPNWnYYqM2EkzgRz2P?usp=sharing
- 새로운 데이터 폴더 생성(machine_learning_data) 및 파일 업로드
# python 빌트인 os 라이브러리 import 및 파일 위치 확인 # 1주차 실습을 위한 pandas 라이브러리 import 및 pd로 alias 지정 import os import pandas as pd os.listdir('./drive/MyDrive/machine_learning_data') > ['friend.csv'] # 데이터 폴더 src 변수 할당 base_src = './drive/MyDrive/machine_learning_data' # friend.csv 파일 src 변수 할당 friend_src = base_src+"/friend.csv" # pandas의 read_csv => 데이터 불러오기 ## encoding= 데이터 인코딩 방식 설정 df = pd.read_csv(friend_src,encoding='utf-8') # 상위 5개 파일 읽기 df.head() > name age job 0 John 20 student 1 Jenny 30 developer 2 Nate 30 teacher 3 Julia 40 dentist 4 Brian 45 manager # new_friend.csv 파일 src 변수 할당 new_friend_src = base_src + "/new_friend.csv" # pandas의 to_csv => 데이터 프레임 저장 ## index = True or False =>데이터 저장시 새로운 인덱스를 생성할지 말지 ## encoding => 데이터 인코딩 방식 설정 df.to_csv(new_friend_src,index=False,encoding='utf-8')
- Series 실습
# series type을 만드는 2가지 방법 ## DataFrame에서 특정 컬럼을 선택해서 만든다. series = df[column name] series > 0 John 1 Jenny 2 Nate 3 Julia 4 Brian 5 Chris Name: name, dtype: object # pd.Series 함수를 통해서 만드는 것도 가능 series = pd.Series([1,2,3,4] series 0 1 1 2 2 3 3 4 dtype: int64 # pd.Series의 parameter(인자) 확인 ## index => 할당값의 지정 이름, 중복 가능['a','a','b','c'] ## dtype => 대표적: int, float, string, boolean 등 series = pd.Series([1,2,3,4],index=['a','b','c','d'],dtype=float) series > a 1.0 b 2.0 c 3.0 d 4.0 dtype: float64 # Series Ordering ## sort_values => values값 정렬 ## sort_values의 ascending=True or False series = pd.Series([10,2,5,4],index=['a','b','c','d'],dtype=float) series.sort_values(ascending=True) # 오름차순 > a 2.0 d 4.0 c 5.0 a 10.0 dtype: float64 ## sort_index => index값 정렬 series = pd.Series([10,2,5,4],index=['z','f','c','d'],dtype=float) series.sort_index() > c 5.0 d 4.0 f 2.0 z 10.0 dtype: float64
- DataFrame 실습
# DataFrame을 만드는 방법 df = pd.DataFrame({'a':[2,3],'b':[5,10]}) df > a b 0 2 5 1 3 10 df = pd.DataFrame([[2,5],[3,10],[10,20]],columns=['a','b']) df > a b 0 2 5 1 3 10 2 10 20 ## columns를 통해서 columns 이름 지정 가능 ## index를 통해서 index 이름 지정 가능 ## dtype를 통해서 data type 지정 가능 df = pd.DataFrame([[2,5],[3,10],[10,20]],columns=['a','b'],index=['가','나','다'],dtype=float) df > a b 가 2.0 5.0 나 3.0 10.0 다 10.0 20.0 ---
- DataFrame 행,열 선택 및 필터링
# friend.csv 불러오기 df = pd.read_csv(friend_src,encoding='utf-8') df > name age job 0 John 20 student 1 Jenny 30 developer 2 Nate 30 teacher 3 Julia 40 dentist 4 Brian 45 manager 5 Chris 25 intern # index 2번에 해당하는 row 가져오기 df.iloc[2] # Series 형태로 가져옴 >name Nate age 30 job teacher Name: 2, dtype: object df.iloc[[2]] # DataFrame 형태로 가져옴 > name age job 2 Nate 30 teacher # column job에 해당되는 데이터 가져오기(1) df['job'] > 0 student 1 developer 2 teacher 3 dentist 4 manager 5 intern Name: job, dtype: object # column job에 해당되는 데이터 가져오기(2) df.loc[:,'job'] > 0 student 1 developer 2 teacher 3 dentist 4 manager 5 intern Name: job, dtype: object # 슬라이싱 기능을 통해 여러 행 가져오기 df.iloc[[2,3]] # 슬라이싱 기능 사용(x) > name age job 2 Nate 30 teacher 3 Julia 40 dentist df.iloc[2:4] # 슬라이싱 기능 사용(ㅇ) > name age job 2 Nate 30 teacher 3 Julia 40 dentist # 슬라이싱을 사용하면 일일히 다 입력하지 안아도 여러값 추출 가능 (중요!) # 슬라이싱 기능을 통해 여러 열 가져오기 df.iloc[:,[1,2]] # 슬라이싱 기능 사용(x) > age job 0 20 student 1 30 developer 2 30 teacher 3 40 dentist 4 45 manager 5 25 intern # 슬라이싱 기능을 통해 여러 열 가져오기 df.iloc[:,1:3] # 슬라이싱 기능 사용(ㅇ) > age job 0 20 student 1 30 developer 2 30 teacher 3 40 dentist 4 45 manager 5 25 intern # "많이 하는 질문!" ```iloc VS loc 뭐가 다른거죠 ?????``` - iloc는 인덱스와 컬럼을 리스트 배열로 선택하는 것! - loc는 인덱스와 컬럼을 문자로 선택하는 것! - 따라서 상황에 맞게 선택하는 것이 중요!
- DataFrame 행, 열 삭제
import numpy as np df = pd.DataFrame(np.arange(12).reshape(3, 4), columns=['A', 'B', 'C', 'D']) > A B C D 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 ## ['B','C'] 컬럼을 삭제하겠다. axis=0 or 1 => 0:row 방향 , 1:col 방향 df.drop(['B', 'C'], axis=1) > A D 0 0 3 1 4 7 2 8 11 ## ['B','C'] 컬럼을 삭제하겠다 df.drop(columns=['B', 'C']) ## index 0과 1을 삭제하겠다. df.drop([0, 1]) > A B C D 2 8 9 10 11 # 각자 df를 찍어보아라. 바뀐게 있는가? 그대로 일 것이다. # 이유는 df = df.drop(~~) => 변수 할당을 안해주었기 때문이다. # 만약 변수할당이 귀찮다면 parameter로 inplace=True를 주어라. df.drop(~~~,inplace=True)
- DataFrame 행, 열 수정
# friend.csv 불러오기 df = pd.read_csv(friend_src,encoding='utf-8') df > name age job 0 John 20 student 1 Jenny 30 developer 2 Nate 30 teacher 3 Julia 40 dentist 4 Brian 45 manager 5 Chris 25 intern # df를 하나 복사하기(원본 데이터 유지를 위해서) temp = df.copy() # age 컬럼 모든 값 변경 temp['age'] = 20 temp > name age job 0 John 20 student 1 Jenny 20 developer 2 Nate 20 teacher 3 Julia 20 dentist 4 Brian 20 manager 5 Chris 20 intern # 인덱스 2번, 컬럼 age => 15로 바꾸기 temp.loc[2,'age'] = 15 temp > name age job 0 John 20 student 1 Jenny 20 developer 2 Nate 15 teacher 3 Julia 20 dentist 4 Brian 20 manager 5 Chris 20 intern # 슬라이싱을 기능을 활용하면 내가 원하는 범위까지 잘 바꿀 수 있겠지??
결론
저자는 실무에서 데이터 분석을 하기 위해서 전처리를 해야하는데, 위에 소개한 방법들을 많이 사용하곤 한다. 하지만 전처리를 할 때 정말 다양한 예외 상황들이 발생을 하는데, 처음에는 어떻게 접근해야할지 막막한 감정을 느꼈었다. 하지만 놀랍게도 다시 기초를 탄탄다지고 다시 전처리 업무를 했을 때, 예전보다 훨씬 퍼포먼스가 향상됨을 느꼈다. 그렇다고 너무 기초만 해서는 안되고, 위 방식들을 응용해서 다양한 방법으로 데이터 전처리 접근을 하길 권장한다.

데이터 분석 유튜버 "거친코딩"입니다.
안녕하세요. 글 잘보았습니다. 첫번째 기본 사용법에 clolab이라 오타가 나서 알려드립니다.