LSTM
Vanilla RNN에서 Long-term dependency 문제 개선
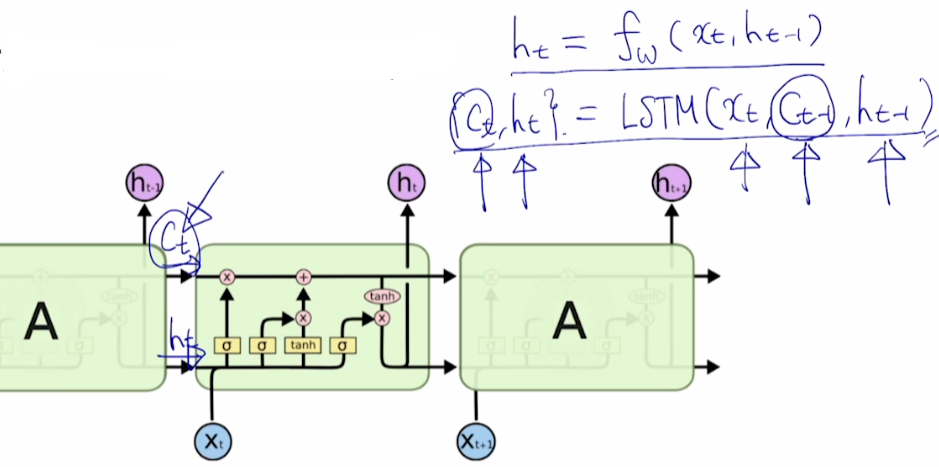
- 는 에 , 에 를 적용시키는 fully connected layer를 거치게 하는 함수
- LSTM에서는 input으로 Cell state 를 사용하며, output도 , 두 개이다.
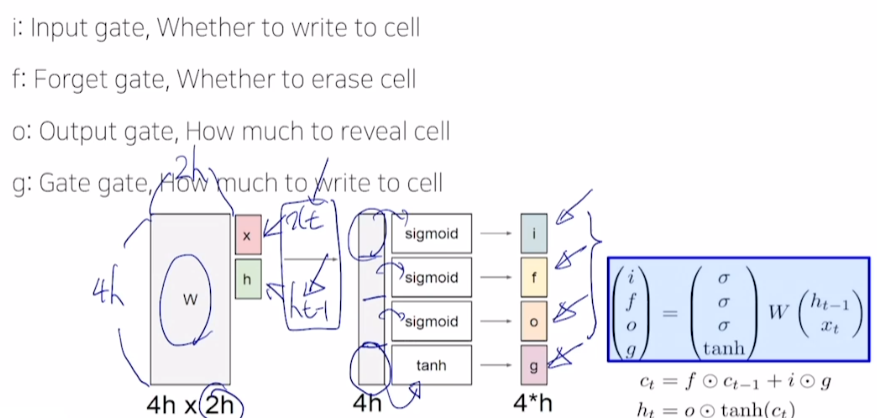
- 와 을 concat
- i, f, o는 sigmoid 함수를 거친 값으로 0~1 사이 값을 갖는다.
- g는 tanh 함수를 거쳐 유의미한 정보를 담음
Forget gate
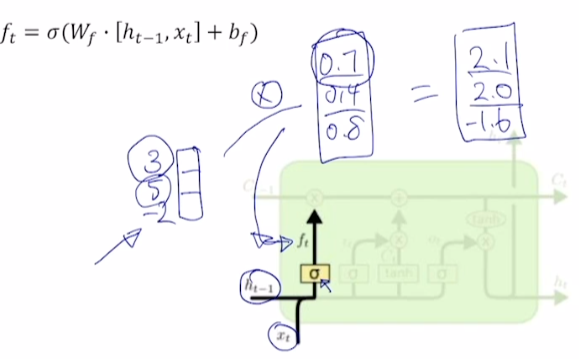
-
는 과 element-wise multiplication
- = [3, 5, -2], = [0.7, 0.4, 0.8] 이라고 한다면, 3의 70%, 5의 40%, -2의 80%만 기억하겠다는 의미
- = [3, 5, -2], = [0.7, 0.4, 0.8] 이라고 한다면, 3의 70%, 5의 40%, -2의 80%만 기억하겠다는 의미
Gate gate & Input gate
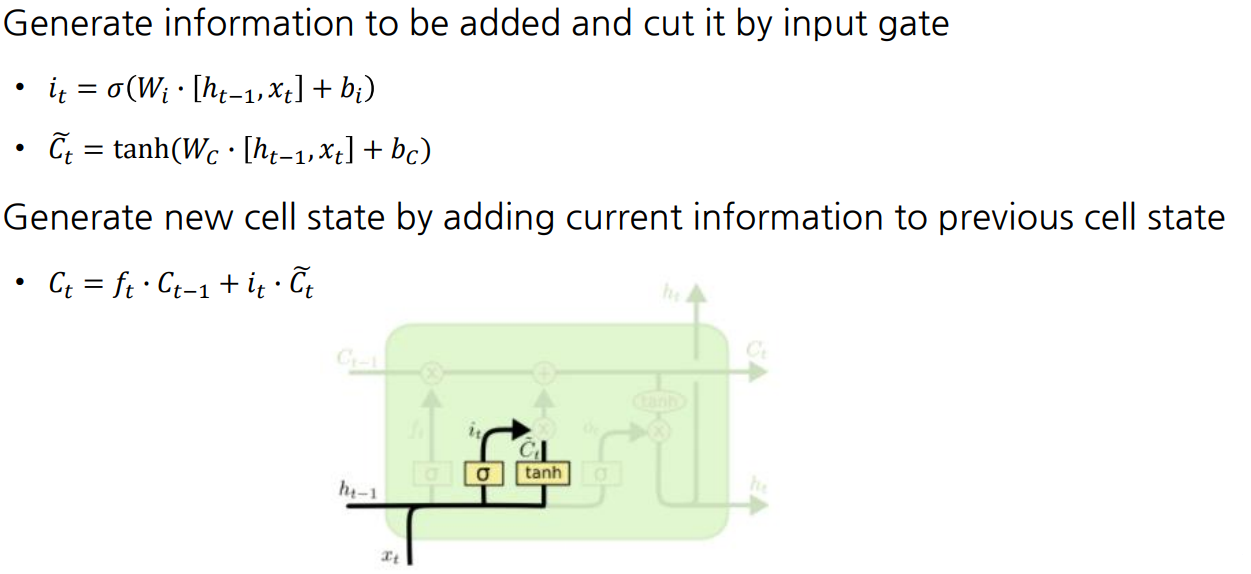
- (Gate gate)는 과 를 로 선형변환 후 tanh 함수를 적용시켜 구함
- 구한 에 input gate 를 성분곱한 값과 앞서 구한 ·과 더해 도출
Output gate
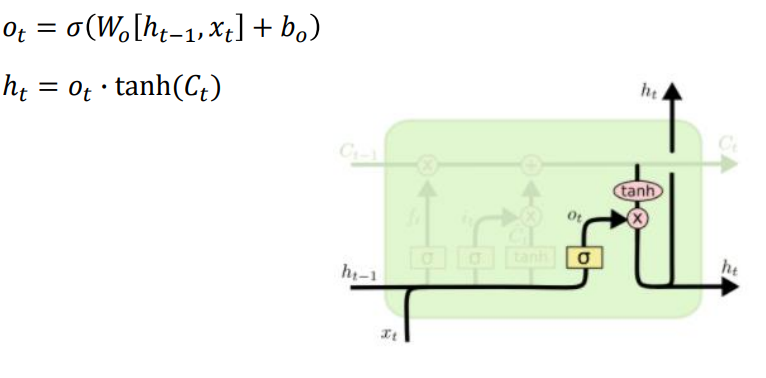
- 앞서 구한 에 tanh 를 적용하고, output gate를 통과시켜 도출
: 기억해야 할 필요가 있는 모든 정보를 기억하는 벡터
: 현재 time step에서 예측값을 내는 output layer의 입력으로 사용되는 벡터
ex) “Hello” 단어 내에서 다음 character를 예측한다고 하자.
만일 e step에서 다음 단어 l을 예측해야 할 때, 는 l에 대한 정보만을 갖고 있고,
는 맨 마지막에 따옴표를 닫아야 한다는 정보까지 기억하고 있다.
GRU
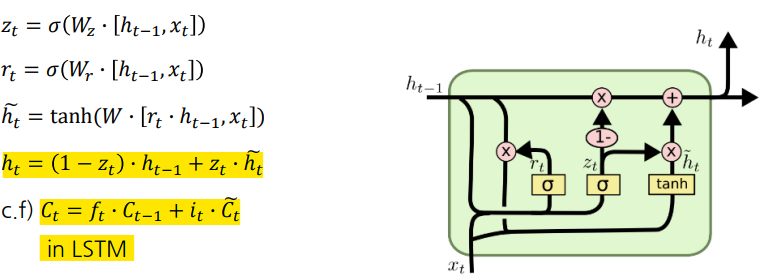
-
Cell state 개념은 사용하지 않고 hidden state만 사용
- 는 LSTM의 Cell state와 유사
-
GRU에서 는 **LSTM에서의 $\tilde{C_{t}}**$ 역할
-
는 forget gate와 input gate 모두 연산해서 값을 구함
-
GRU에서 는 gate를 에 곱하고, 에는 를 곱함
-
독립적인 gate를 곱하는 것이 아님
-
현재 정보를 많이 남기면 이전 정보를 조금만 기억하거나, 이전 정보를 많이 남기면 현재 정보를 조금만 기억하는 구조
-
-
-
LSTM보다 연산량을 줄임
Backpropagation in LSTM & GRU
gate값은 서로 다름
필요로 하는 정보를 곱셈이 아닌 덧셈으로 연산
-
gradient vanish, explode 문제 해결
-
덧셈 연산은 역전파 과정에서 gradient를 복사하는 연산
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid