Introduction to Passage Retrieval
Passage Retrieval
- 질문에 맞는 문서를 찾는 것
Open-domain Question Answering
-
대규모 문서 중 질문에 대한 답을 찾는 것
-
Passage Retrieval과 MRC를 이어 2단계로 만들 수 있음
Overview
-
Query와 Passage를 embedding한 뒤 유사도로 랭킹을 매기고, 유사도가 가장 높은 Passage 선택
- Passage는 미리 embedding을 구해 효율성 높임
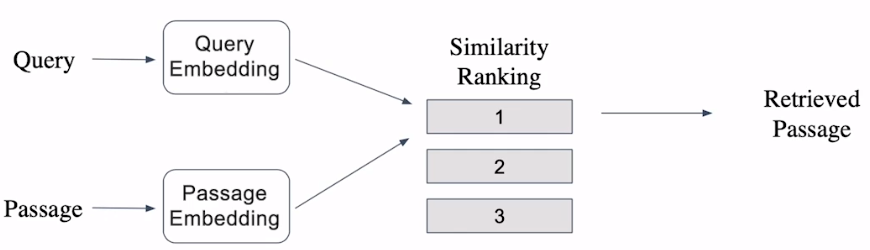
Passage Embedding & Sparse Embedding
Passage Embedding Space
-
Passage Embedding의 벡터 공간
-
벡터화 된 Passage를 이용해 Passage 간 유사도를 계산 가능
Sparse Embedding
-
Bag-of-Words (BoW)
-
단어 개수가 차원의 개수
-
구성 방법으로 n-gram 사용
-
-
특징
-
등장 단어가 많아질수록 차원이 증가
-
n-gram의 n이 커질수록 증가
-
term overlap을 정확하게 잡아내야 할 때 유용
-
의미가 비슷하나 다른 단어인 경우 비교 불가
-
TF-IDF
TF-IDF 소개
-
TF : Term Frequency, 단어 등장 빈도
-
IDF : Inverse Document Frequency, 단어가 제공하는 정보량
- 특정 문서 내에 단어가 많이 등장했지만, 전체 문서에선 등장 횟수가 적음
→ 해당 단어에 가중치
- 특정 문서 내에 단어가 많이 등장했지만, 전체 문서에선 등장 횟수가 적음
TF (Term Frequency)
-
해당 문서 내 단어 등장 빈도
-
특정 단어 등장 횟수 / 전체 단어 개수
IDF (Inverse Document Frequency)
-
단어가 제공하는 정보의 양
-
-
DF (Document Frequency) : Term t가 등장한 document 개수
-
N : 총 document 개수
-
Combine TF & IDF
-
-
a, an, the 같이 다수 document에서 나오는 단어
-
TF는 높을 수 있지만 IDF가 0에 가까움
- 거의 모든 document에 등장 ⇒ N ≒ DF(t) ⇒ ≒ 0
-
-
자주 등장하지 않는 고유명사 (e.g., 사람 이름, 지명)
- IDF 값이 커지며 높은 TF-IDF
TF-IDF를 이용해 유사도 구하기
-
계산한 문서 TF-IDF를 가지고 질의 TF-IDF 계산 후 가장 관련있는 문서 탐색
-
보통 두 TF-IDF 사이의 cosine 유사도로 계산
BM25
- TF-IDF 개념을 바탕으로, 문서 길이를 고려해 scoring
예시
docs = [
'먹고 싶은 사과',
'먹고 싶은 바나나',
'길고 노란 바나나 바나나',
'저는 과일이 좋아요'
]
# 총 문서의 수
N = len(docs)
def tf(t, d):
return d.count(t)
def idf(t):
df = 0
for doc in docs:
df += t in doc
return log(N/(df+1))
def tfidf(t, d):
return tf(t,d)* idf(t)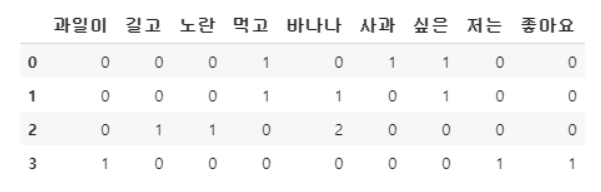
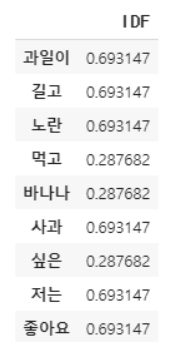
- TF & IDF matrix
- 0, 1, 2, 3은 document 번호
- 둘을 곱하면 각 document의 embedding vector를 구할 수 있음
실습
TF-IDF 계산
from sklearn.feature_extraction.text import TfidfVectorizer
tokenizer_func = lambda x: x.split(' ')
vectorizer = TfidfVectorizer(tokenizer=tokenizer_func, ngram_range=(1,2))ngram_range=(1, 2)uni-gram과 bi-gram 모두 포함
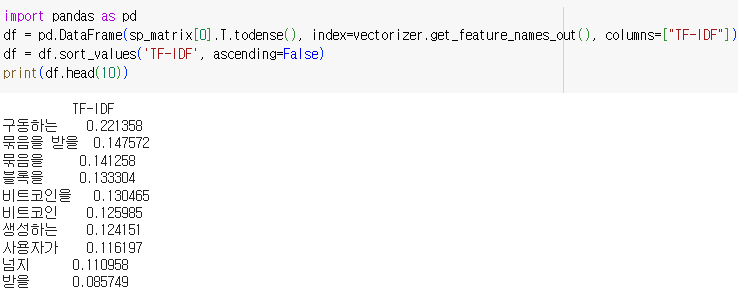
- TF-IDF 결과
Passage Retrieval
-
Query를 TF-IDF 벡터로 변환
query_vec = vectorizer.transform([query]) -
변환된 query vector을 document들의 vector와 dot product 수행
- document들의 similarity ranking을 구함
result = query_vec * sp_matrix.T -
Top-3개 passage retrieve
sorted_result = np.argsort(-result.data) doc_scores = result.data[sorted_result] doc_ids = result.indices[sorted_result] doc_scores[:3], doc_ids[:3]

- 잘 맞힘
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
