Introduction to Dense Embedding
Sparse Embedding
-
TF-IDF는 Sparse 함
-
BoW 방법론을 택하기 때문에 90% 이상 dimension은 0
-
차원의 수가 매우 큼 → compressed format으로 극복 가능
- 그러나 유사성을 고려하지 못함
-
Dense Embedding
-
더 작은 차원의 고밀도 벡터
-
Bag of Words처럼 각 차원이 특정 term에 대응되지 않음
Sparse vs Dense
- Sparse는 중요한 term들이 정확히 일치해야 하는 경우에 성능 뛰어남
- 임베딩 구축 후 추가적인 학습 불가능
- Dense는 단어의 유사성 또는 맥락을 파악하는 경우 성능 뛰어남
- 추가적인 학습 가능
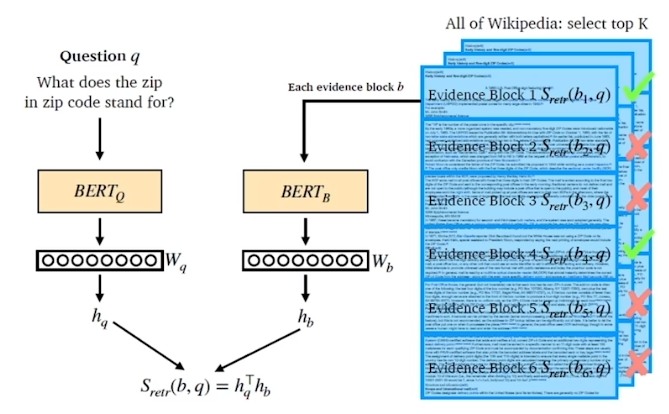
Overview
-
BERT를 이용해 question과 document를 embedding
-
dot product similarity를 이용해 유사도 계산
-
passage와 question은 다른 encoder를 쓰기도 하고 같은 encoder를 쓰기도 함
Training Dense Encoder
Dense Encoder
-
BERT와 같은 PLM(Pre-trained language model)이 자주 사용
-
[CLS] token의 output을 사용
학습 목표와 학습 데이터
-
학습 목표
-
연관된 question과 passage dense embedding 간 거리를 좁히는 것
또는 inner product 값을 높이는 것 ⇒ Positive -
연관되지 않은 question과 passage 간의 embedding 거리는 멀어야 함 ⇒ Negative
-
-
Challenge
- 연관된 question / passage를 어떻게 찾을 것인가? → 기존 MRC dataset 활용
Negative Sampling
-
좀 더 헷갈리는 negative sample을 추출
- 높은 TF-IDF score를 가지지만 답을 포함하지 않는 sample
Objective Function
- Positive passage에 대한 Negative Log Likelihood(NLL) 사용
Passage Retrieval with Dense Encoder
From dense encoding to retrieval
-
Inference
- Passage와 query를 각각 embedding 한 후, query로부터 가까운 순서대로 passage ranking
From retrieval to open-domain question answering
-
Retriever를 통해 찾아 낸 passage 활용
-
MRC 모델로 답을 찾음
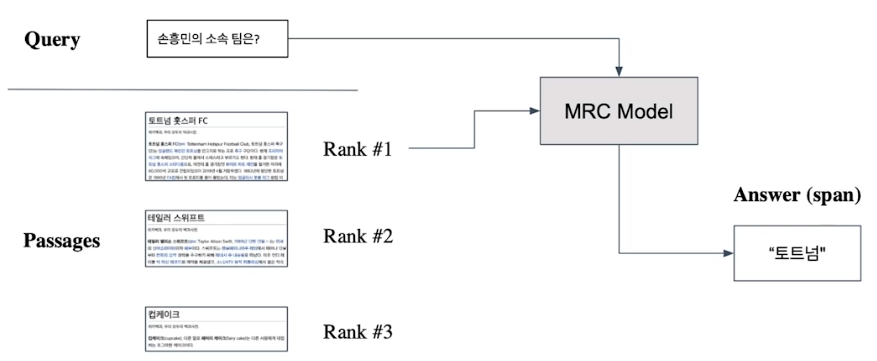
💡 MRC model 향상도 중요하나, 올바른 문서를 찾아올 수 있는가에 대한 개선도 매우 중요
실습
Question Encooder & Passage Encoder 학습

-
p_embs는 11개의 random passages embedding vector
-
q_emb는 1개의 question embedding vector
→ 두 vector을 dot product를 통해 passage의 similarity ranking을 구함

※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
