Self Attention
→ 기존 Attention과 다르게 Self attention에서는 Q, K, V 값이 모두 동일
Q : 입력 문장의 모든 단어 벡터들
K : 입력 문장의 모든 단어 벡터들
V : 입력 문장의 모든 단어 벡터들
- Attention을 자기 자신에게 수행하며 한 문장 내에서 단어가 어떤 단어와 연관이 높은지 보임
Process
1) Q, K, V 벡터 얻기
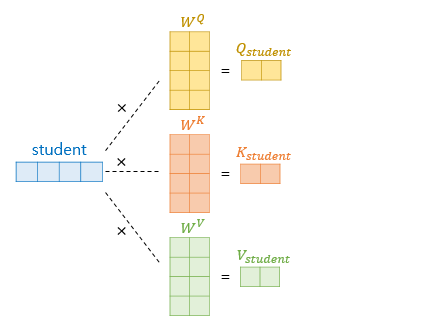
- 초기 input의 단어 차원은 =512이며, 논문에서는 Q, K, V 벡터의 차원을 / h(num_heads) = 512 / 8 = 64 차원으로 지정했다.
- 각 가중치 행렬 , , 의 크기는 (, / (num_heads) = (512, 64) 이다.
- Q, K, V 벡터는 기존 벡터로부터 가중치 행렬을 곱해 나온 벡터이다.
- 위 그림은 student라는 단어의 Q, K, V 벡터를 구하는 과정으로, 그림에선 4차원이지만 실제로는 512차원이다.
- Q, K, V의 크기는 (512, ) · (512, 64) = (64, )이다.
모든 단어 벡터에 위 연산을 적용하면 I, am, a, student 각각에 대해 Q, K, V 벡터 총 3개를 얻는다.
2) Scaled dot-product Attention
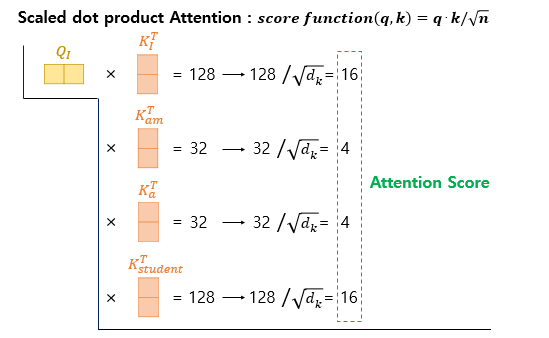
단어 I에 대한 Q벡터에 대한 설명이며, am, a, student 단어 벡터 모두 동일한 process
- K 벡터는 과정 1을 거쳐 단어 벡터에 가중치 행렬을 곱해 만들어진 벡터
- 단어 I (Q)와 나머지 모든 단어(K)를 내적해 그 값을 계산
- 128, 32는 임의의 숫자
- 그 후 로 나눠 scaling해 Attention Score를 계산
- = = =
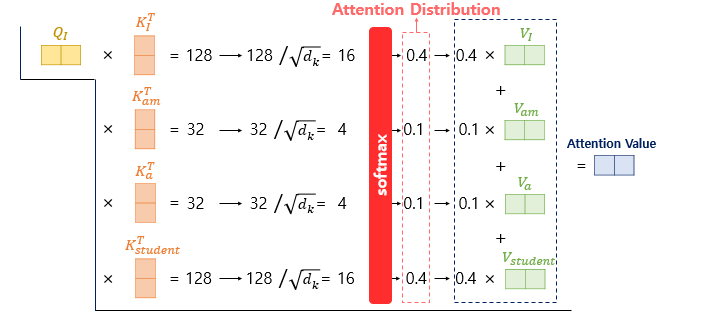
- Attention Score에 softmax 함수를 적용해 Attention Distribution을 계산
- V 벡터와 가중합을 통해 Attention Value 벡터 도출
- V 벡터는 실제로 64차원이므로, Attention Value도 64차원이다.
해당 과정은 I 단어에 대한 Q벡터로, 나머지 단어에도 같은 연산을 적용하면
Attention Value는 (4, 64), 즉 (sequence_length, dmodel/num_heads) 차원을 갖게 된다.
3) 행렬 연산으로 일괄 처리
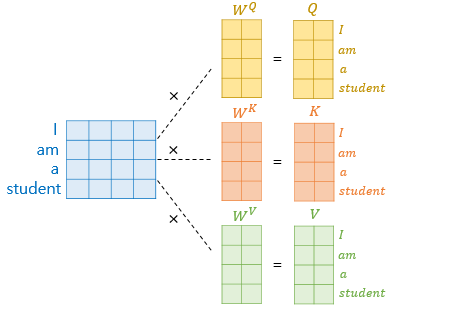
Attention Value를 계산하는데 각 단어를 나눈 후 다시 합치는 과정이 아닌,
행렬 연산을 사용해 일괄적으로 계산
- 입력 문장의 차원은 (sequencelength, $d{model}$) = (4, 512)
- 모든 가중치 행렬(W)의 차원은 (, /num_heads) = (512, 64)
- Q, K, V 행렬의 차원은 (sequencelength, $d{model}$/num_heads) = (4, 64)
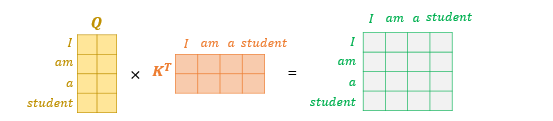
Attention Score 계산을 위해 를 계산하면 오른쪽과 같은 행렬이 나온다.
- 행렬의 1행(I) 4열(student)은 I의 Q벡터와 student의 K벡터의 score를 의미
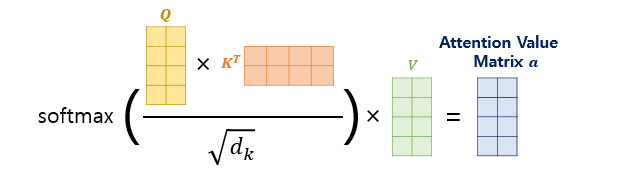
Attention Score Matrix를 구했으면, Attention Value Matrix를 계산할 수 있다.
논문에서는 위 수식을 이용한다.
Q, K, V Matrix의 크기는 (sequence_length, )이므로
Attention Value Matrix의 크기도 마찬가지로 (sequence_length, )
Multi-head Attention
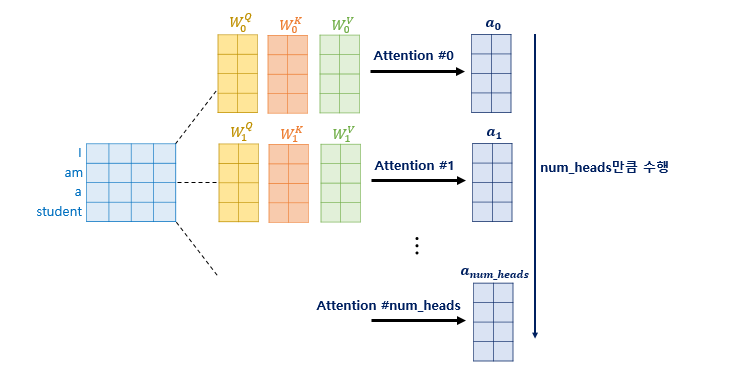
- 한 번의 Attention을 진행하는 것보다, 여러 Attention을 동시 진행하는 것이 효율적
- Attention 개수 hyperparameter가 num_heads
- 각 attention value matrix를 Attention head라고 함
- 가중치 행렬 , , 은 Attention head마다 모두 다름
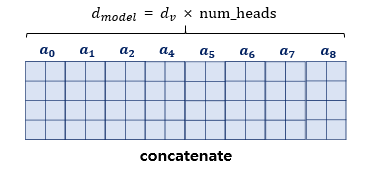
병렬 Attention을 모두 수행했다면, concatenate
따라서 출력 차원은 (sequencelength, $d{V} × num_heads$ = ) = (4, 512)
만약 입력 문장이 “The animal didn’t cross the street because it was too tired.” 이고 Query=it 일 때,
어떤 Attention head에서는 it을 animal로, 다른 attention에서는 street으로 볼 수 있다.
→ 병렬로 수행해 다른 시각의 정보를 수집
이미지 출처: wikidocs
