Transformer
→ Attention만으로 sequence data를 처리
Bi-Directional RNNs
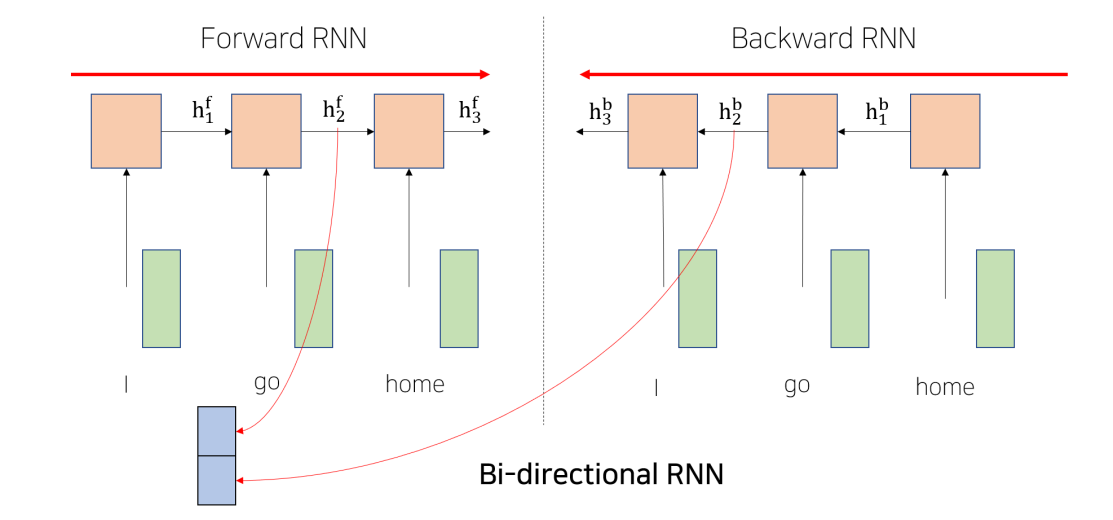
- 의 경우 Forward RNN에서는 I, go 정보를, Backward RNN에서는 home, go의 정보 저장
- 두 RNN의 hidden states를 concatenate
- 크기는 2*hidden dimension
Self-Attention
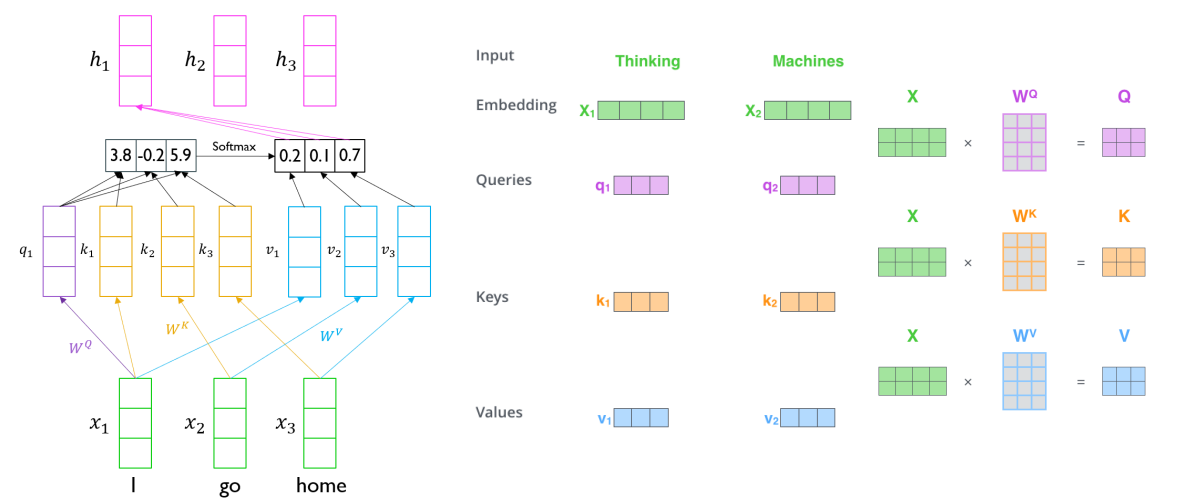
Query: 주어진 벡터들 중 어느 벡터를 가져올지 기준이 되는 벡터
Key: Query 벡터의 내적이 되는 재료 벡터들
Value: 가중 평균이 구해지는 재료 벡터들
단어 I에 대해서 encoding할 때,
- I에 해당하는 입력 벡터가 에 의해 query 벡터로 변환
- sequence의 모든 단어들은 Keys, Values 벡터로 변환
- 은 에 대응 → 1번째 key의 유사도가 적용되는 벡터는 이다.
- query는 하나로 고정되어 있어도, key-value는 분리되어 있지만 개수는 동일해야 함
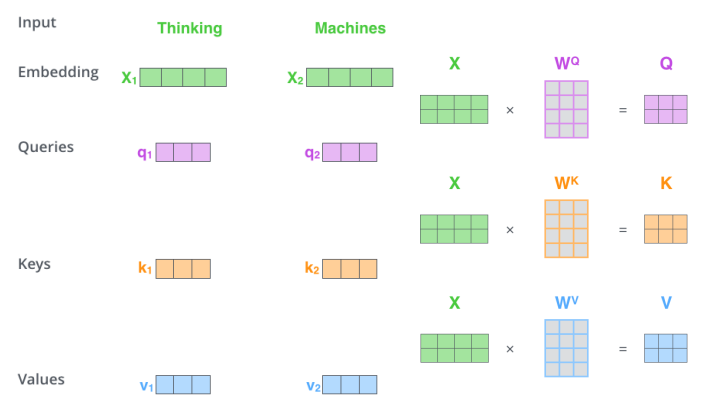
- , 를 concat해 X라는 matrix를 input으로 사용
- Q, K, V matrix 모두 q, k, v벡터 1&2가 concat된 형태
Sequence 길이가 길어져도 long-term dependency 문제가 없을까?
- RNN의 경우 멀리 있는 data에 접근을 위해선 time step만큼 RNN cell을 통과해야 하지만, Self-Attention은 sequence length와 무관하게 Key, Value 벡터는 동일하게 생성
Self-Attention 수식
Query, Key 벡터는 내적 연산을 해야 하므로 차원이 같아야 함 ()
Value 벡터는 꼭 와 같지 않아도 됨 ()
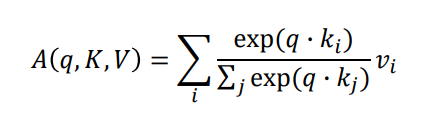
- Attention module의 output은 차원을 가짐

- row-wise softmax를 통해 각 row의 합이 1이 됨
Scaled dot-product
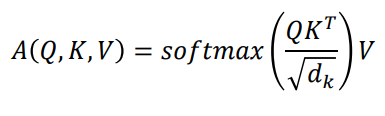
로 나눠주는 이유?
- 의 차원이 커지면 내적값의 분산 및 표준편차도 그만큼 커짐
분산이 큰 분포가 softmax 함수에 적용되면, 큰 쪽으로 쏠리는 경향이 존재
→ 내적값을 로 나눠줌으로써 학습 안정화
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid