Multi-Head Attention

- head의 개수만큼 , , 각각 존재
- 각 head의 Attention output을 모두 concat
각각의 head는 서로 다른 정보를 추출해 상호보완적으로 작용
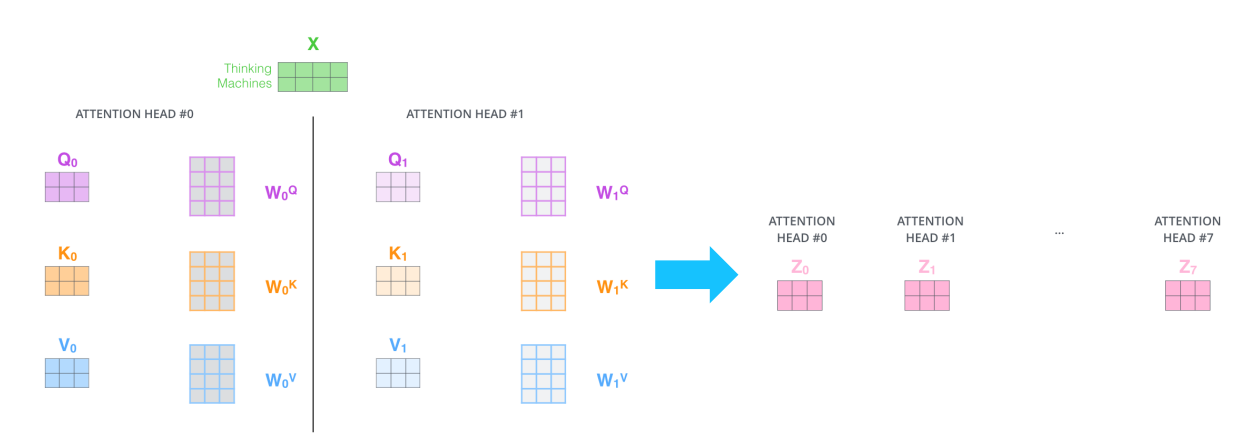
- input X인 ‘Thinking Machines’에 대해 8번 Head-Attention 적용
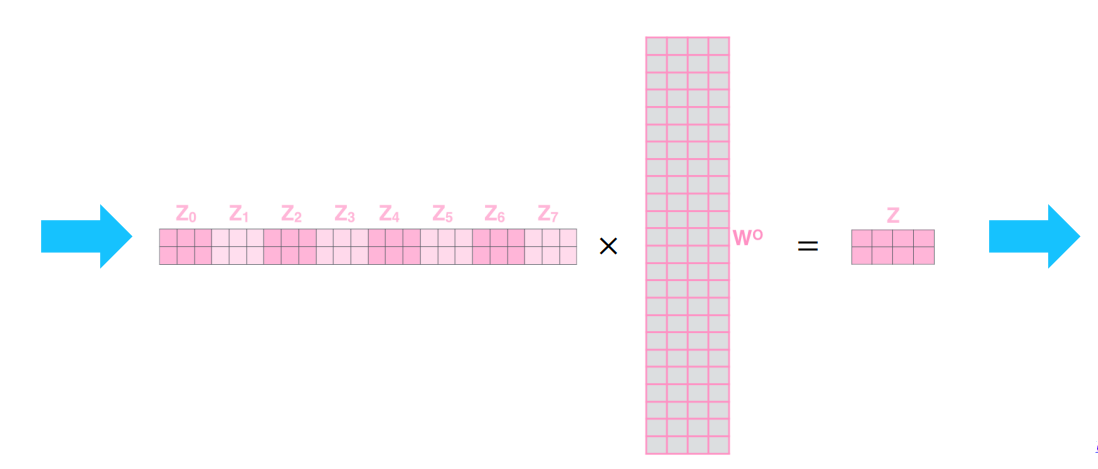
- 각 결과 8개를 모두 concat 후, 와의 선형결합을 통해 최종 output 계산
복잡도 및 계산량

Complexity per Layer
-
vs
- 메모리 효율의 경우 RNN이 n, Self-Attention이 으로 더 복잡
Sequential Operations (병렬화)
- Self-Attention은 한 번에 수행 가능, RNN은 재귀적으로 진행되므로 n번 수행
→ Self-Attention이 메모리 요구량은 더 높으나, 학습 속도가 더 빠름
Matimum Path Length
-
RNN -
- 가장 끝에 있는 단어가 가장 앞의 단어를 참조하기 위해서 n번의 layer을 통과
-
Self-Attention -
-
어떤 단어든 정보를 직접적으로 한 번에 가져올 수 있음
-
long term dependency 문제 해결
-
Block-Based Module
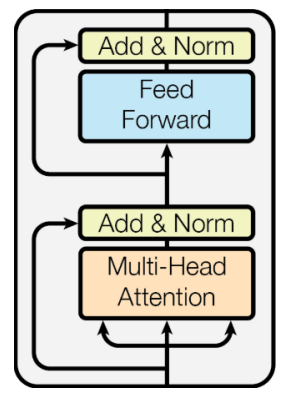
Add
- Residual connection
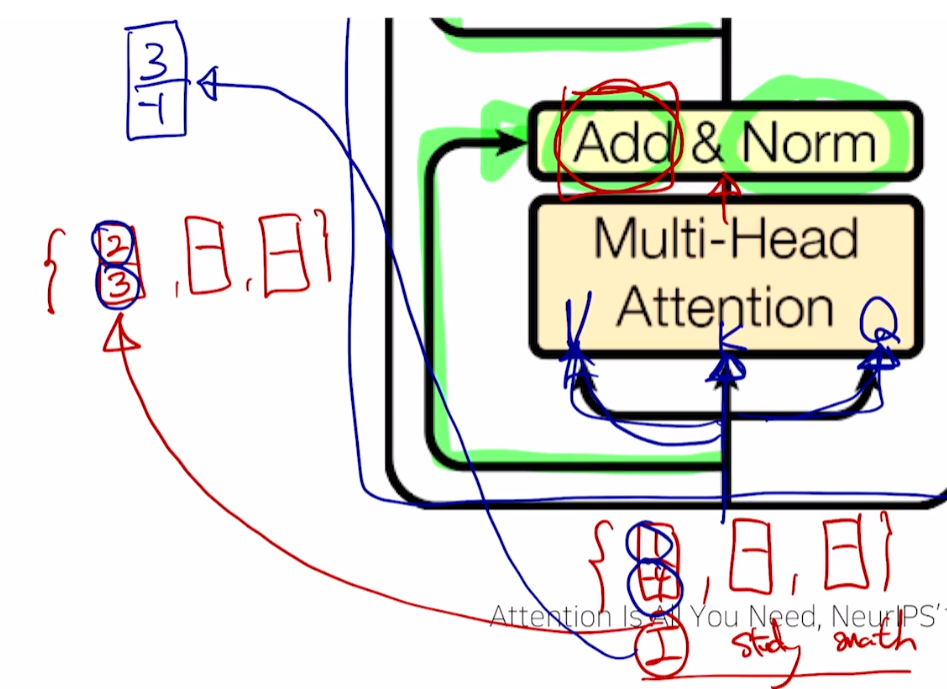
-
단어 I에 대한 벡터가 [1, -4], 단어 I의 encoding output이 [2, 3]일 때,
두 벡터를 add해 [3, -1] 벡터를 도출 -
입력 벡터와 encoding output 벡터의 차원이 동일해야 함
Layer Normalization
주어진 sample들의 평균을 0, 분산을 1로 만들어 준 후 원하는 평균, 분산을 주입할 수 있도록 하는 선형 변환으로 이루어짐
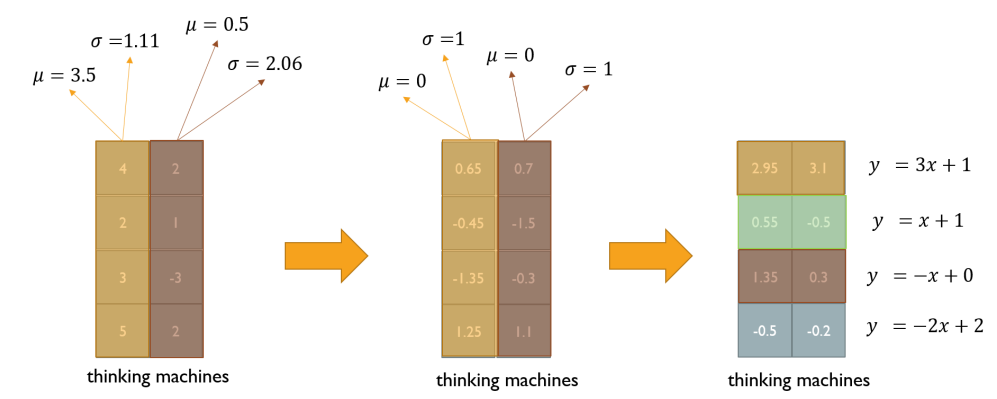
-
thinking, machines의 단어 벡터를 각각 평균 0, 분산 1이 되도록 정규화
-
맨 왼쪽의 W=[3 1 -1 -2], b=[1 1 0 2]는 학습 가능한 parameter
-
정규화된 값을 이용해 최적의 W, b를 찾도록 학습
-
[2.95, 3.1]은 [0.65, 0.7]이 을 거쳐 나온 값
-
-
가변 길이를 갖는 RNN에서는 Layer Normalization이 효과적
-
만약에 [0.65 0.7][-0.45 -1.5] 단위로 수행하면 batch normalization?
- 두 정규화 기법의 파라미터 개수는 똑같고, 정규화를 진행하는 방향만 다른 것인가?
Positional Encoding
‘I go home’, ‘Home go I’ 라는 두 문장이 있을 때, Self-Attention에선 위치 정보를 따로 고려하지 않기 때문에 문장 구조가 다름에도 각 단어들의 output이 동일하다.
이를 해결하기 위해 각 단어의 위치 정보를 부여
순서를 규명할 수 있는 벡터를 word vector에 더해줌
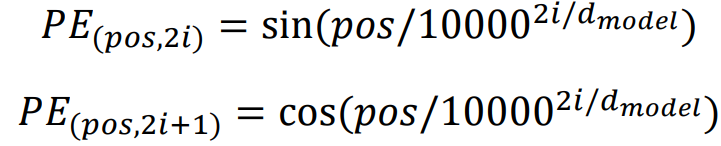
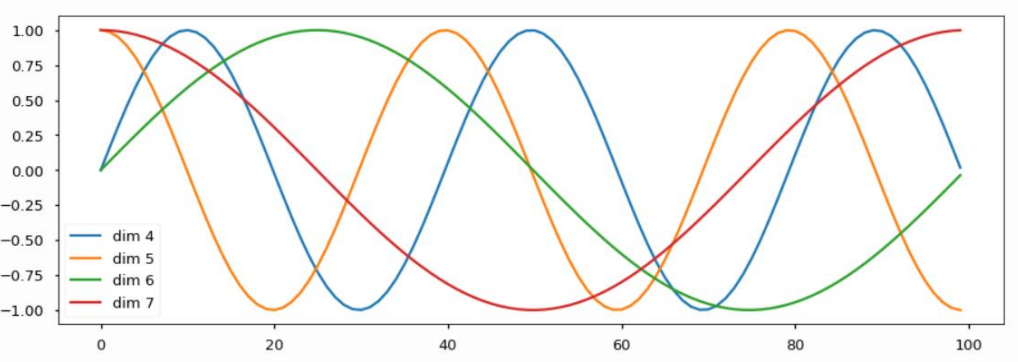
- dimension 개수만큼 그래프가 존재
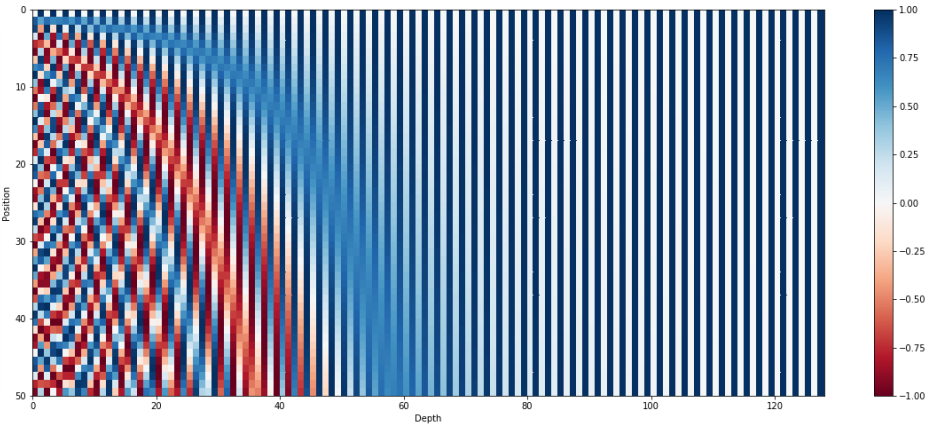
- 128차원의 positional encoding
- 그래프에선 50개의 position이 존재하며, 해당 position의 row vector를 position 정보로 사용
Warm-up Learning Rate Scheduler
learning rate 값도 학습 중 적절히 변경하며 사용
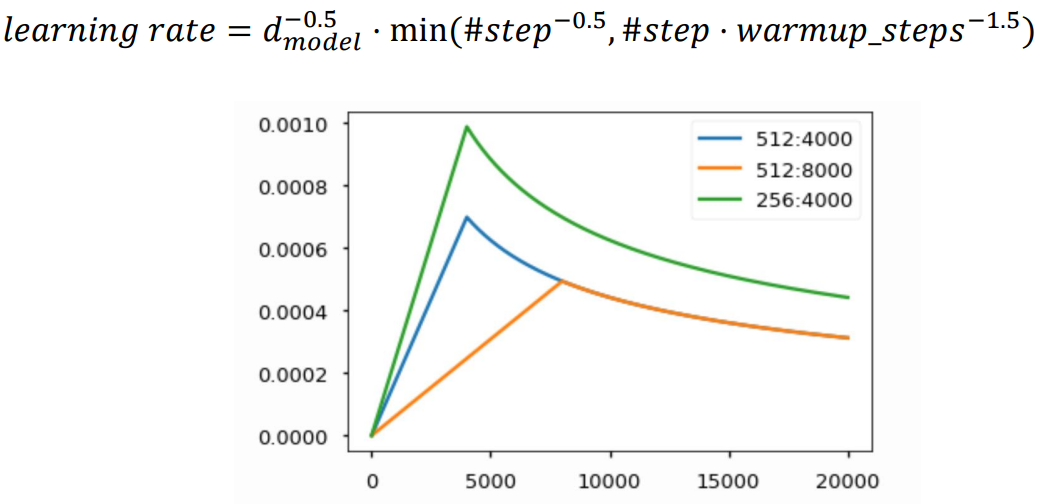
- y축은 learning rate, x축은 iteration
- 학습 초반엔 learning rate를 크게 해 최적점 부근으로 도달하게 만들고, 그 후 learning rate을 점차 낮춰가며 최적점에 수렴할 수 있도록 함
Transformer High-level View
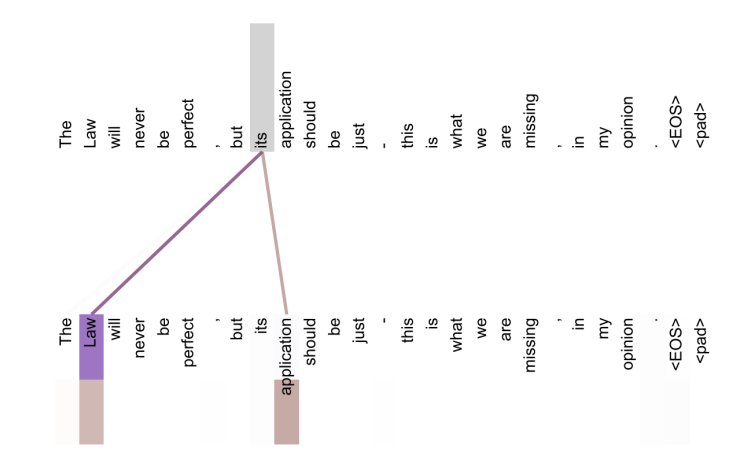
- output에서 2개의 head를 발견할 수 있음
- 첫 번째 head는 it이 지칭하는 것에 대한 정보를 저장하고, 두 번째 head는 its가 한정하는 명사에 대한 정보를 저장
Decoder
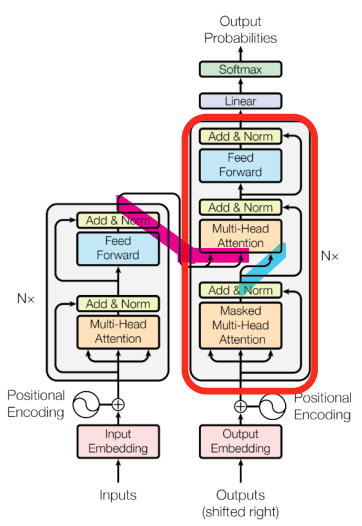
- Query는 Decoder의 self-attention에서, Key-Value는 Encoder의 output을 사용
Masked Self-Attention
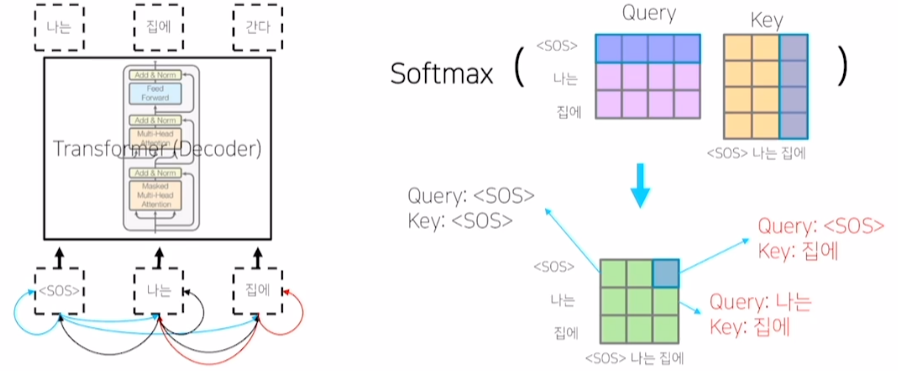
- 학습 과정에선
<SOS>token에 대한 예측을 수행할 때, ‘나는’과 ‘집에’ 단어가 고려되어선 안 됨
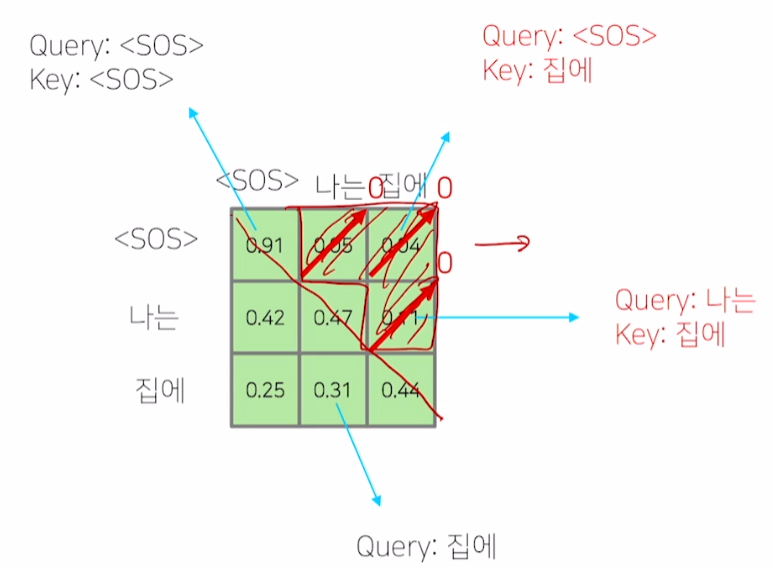
- 0으로 만들고 나머지 vector를 합이 1이 되도록 후처리
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
