-
Supervised Learning(지도 학습)
: 정답(Label)이 존재. 수치를 예측하는 것이면 Regression, 분류의 문제는 Classification
참고
Classification -> https://scikit-learn.org/stable/supervised_learning.html#supervised-learning
Regression -> https://scikit-learn.org/stable/supervised_learning.html#supervised-learning -
Unsupervised Learning(비지도 학습)
: 정답(Label)이 없음. 비슷한 것들끼리 그룹화(Clustering)하거나 차원 축소(Dimension Reduction)을 주로 함.
참고
Clustering -> https://scikit-learn.org/stable/modules/clustering.html#clustering
DR -> https://scikit-learn.org/stable/modules/decomposition.html#decompositions
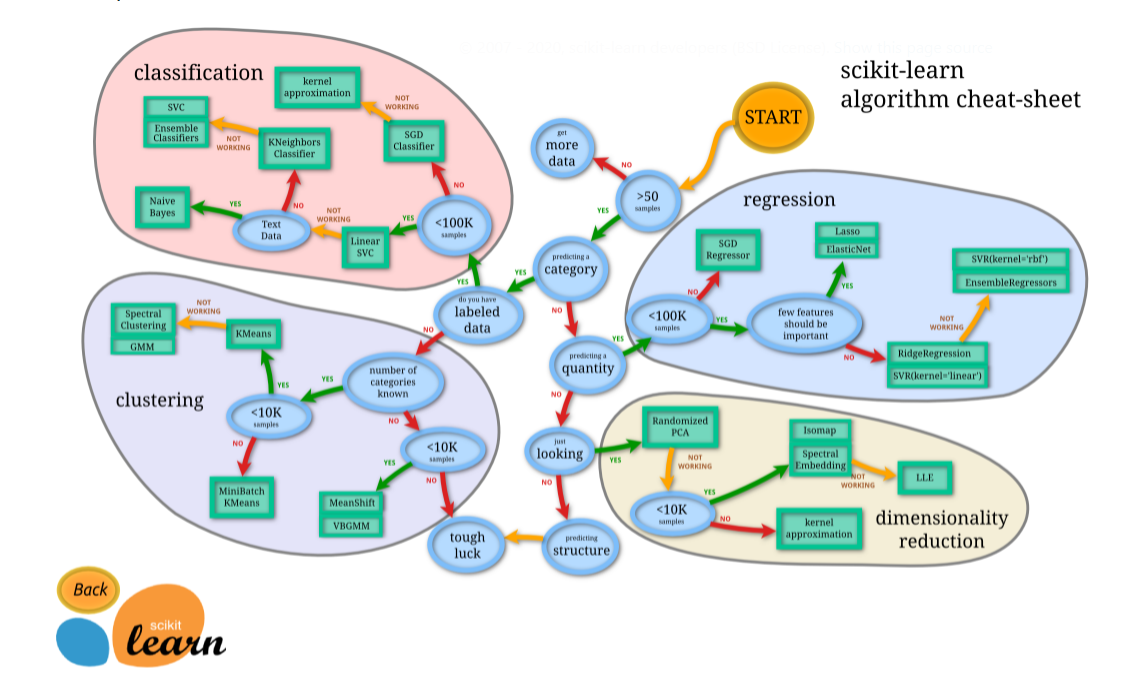
사이킷런 알고리즘 치트시트
사이킷런 개발자 Github. 컨퍼런스 자료도 있음.
https://github.com/amueller/odscon-2015
사이킷런을 이용해 할 수 있는 것들

사이킷런 만으로도 머신러닝의 대부분이 가능
Basic API: Fit, Predict, Transform
- Estimator는 생성한 모델! ex) SVM, DecisionTree ....
- Estimator.fit(X, [y]) -> y는 필수가 아닌 이유는 비지도학습도 포함하기 때문
- Estimator.predict: Classification, Regression, Clustering
- Estimator.transform: Preprocessing, Dimensionality reduction, Feature selection, Feature extraction
기본적인 머신러닝의 로직1
- 전체 데이터 셋을 Train / Test로 분할(비율은 분석자 재량)
- Train set을 Train / Valid로 분할(Train은 학습에만, Valid는 파라미터 튜닝에)
- 사용 가능한 모델들을 최대한 많이 생성(모든 경우에 최적인 모델은 없으므로)
- Train으로 학습시키고 Test로 검증해 성능을 비교
기본적인 머신러닝의 로직2
- 최적의 모델을 선정하기 위해 K-fold CV와 같은 교차검증을 통해 모델의 성능을 비교 -> Train set으로만 교차검증 실시
- 하나의 모델을 정하고 GridSearch CV, Randomized Search와 같은 파라미터 튜닝까지 해주는 알고리즘을 사용해 파라미터 튜닝까지 끝낸 최적의 모델을 도출 -> 파라미터 튜닝은 모델의 성능 향상을 위해 하는 방법 중 하나.
Test set은 Unseen data로 모델의 일반화 성능을 평가하기 위해 따로 떼어두는 Dataset이라 생각
Overfitting vs Underfitting
- Overfitting: train set에 대해서만 잘 맞춤 => 일반화가 어려움
- Underfitting: train set, test set에 대해 성능이 좋지 않음 -> 학습 자체가 제대로 안됨
이 둘 사이의 트레이드 오프를 고려해 최적의 지점을 찾아야 함
Scikit-learn의 모델들
- Linear Models: Logistic Regression, Ridge, RidgeClassifier, Lars, ElasticNet...
- Feature Selection: RFECV
- Tree-Based Models: Decesion Tree, RandomForest, GradientBoosting...
트리 기반 모델들은 회귀, 분류 모두 가능. 선형 모델도 일부 가능한 것도 있음
의사결정나무
- 사이킷런으로 의사결정나무 모델을 만드는 방법 이해
- 지도학습의 분류 기법을 통해 새로 들어온 고객의 물건 구매 여부 분류
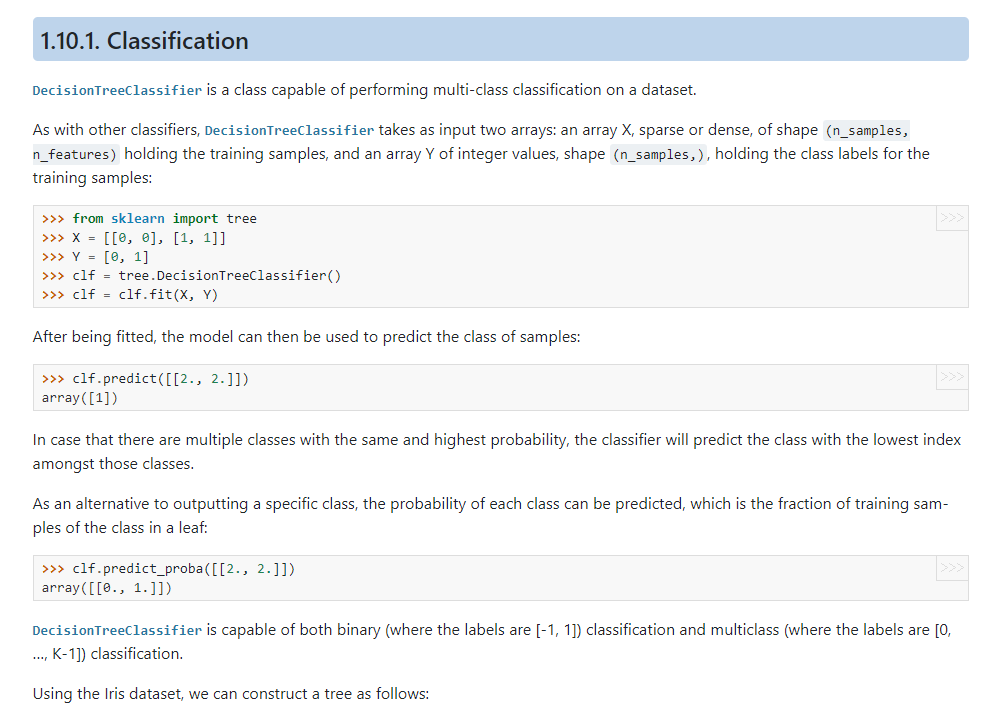
- 위 예제를 풀어보며 학습!
from sklearn import tree
X = [[0, 0], [1, 1]]
Y = [0, 1]- tree 패키지 안에 DecisionTreeClassifier(분류), DecisionTreeRegressor(회귀) 모듈이 존재
clf = tree.DecisionTreeClassifier()
clf
- Default로 생성되는 모델의 하이퍼 파라미터들. 의사결정나무는 depth가 깊어질수록 과적합이 발생하므로 모델의 일반화를 위해서 alpha값 조절을 통해 Prunning(가지치기)을 하거나 max_depth를 조절해서 깊이 자체를 얕게 해줌.
### 모델의 학습
clf = clf.fit(X,Y)
clf- fit을 통해 모델을 학습시키고 학습된 트리가 저장되어 clf에 저장
- clf = clf.fit(X, Y)대신 clf.fit(X,Y)만 입력해줘도 무방
clf.predict([[2., 2.]])- predict를 이용해 인풋의 클래스를 예측! Y의 클래스가 0, 1 이었으므로 둘 중 하나의 값으로 분류!
clf.predict_proba([[2., 2.]])- predict_proba를 이용하면 클래스가 아닌 클래스에 해당될 확률을 반환
- 원래 확률 값을 계산해서 정해준 Threshold(임계값)보다 크면 1 작으면 0 이런식으로 분류하는 것. predict 매서드엔 이 과정이 포함되어 있는 것. predict_proba는 확률 값만 출력
- 내가 관심 있는 것을 1로 뒀고 이 1을 많이 맞혀야 한다면 C값을 0에 좀 더 가까운 쪽으로 해서 1이라고 분류하는 경우를 많게 해 줌. 보통 0.5를 기준으로 함.

- predict_proba를 보면 클래스 별로 속할 확률을 반환하므로 클래스의 개수만큼 return! 0일 확률이0, 1일 확률이 1.
from sklearn.datasets import load_iris
from sklearn import tree
X, y = load_iris(return_X_y = True)- 사이킷런에는 머신러닝의 대표적인 데이터 셋들도 제공해 줌.
- 원래 데이터셋 안에 Feature와 Target 뿐만 아니라 Feature의 변수명, Target의 클래스 명까지 같이 제공. return_X_y를 True로 주면 X와 y만 가져오게 됨.
clf = tree.DecisionTreeClassifier()
### IRIS Dataset 학습!
clf.fit(X, y)import matplotlib.pyplot as plt
plt.figure(figsize = (20, 10))
t = tree.plot_tree(clf.fit(X, y))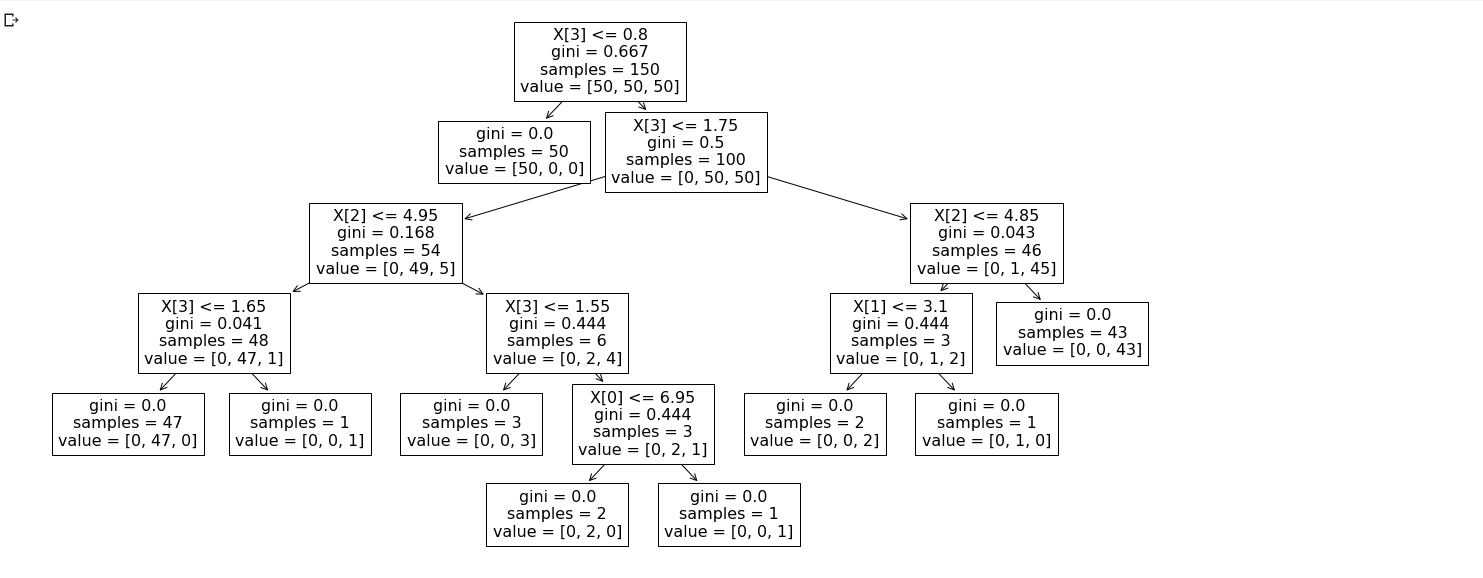
- tree plot을 이용해 트리가 어떻게 생겼는지 시각화가 가능하다. 사각박스가 노드에 해당되고 회귀의 경우는 분산이 작은 쪽, 분류의 경우는 불순도가 적은 쪽으로 노드들이 생성된다. 즉, 성능이 좋은 쪽으로 트리의 노드가 결정되는 것.
- X와 y에 클래스명과 컬럼명을 지정하지 않았기 때문에 노드에 X[3] 이런식으로 써짐. X의 3번재 컬럼이라는 뜻.
- 새로운 데이터를 넣어 예측이 되는 과정은 맨 꼭대기 노드부터 시작해서 순서도(flowchart)를 따라 결과를 내는 과정과 같다고 생각하면 된다.
- 조건에 맞으면 오른쪽, 아니라면 왼쪽 이런식으로 이동하며 leaf-node에 다다른 순간 마지막 조건을 통해 클래스를 결정. leaf-node는 더 이상 자식 노드가 없는 노드를 뜻함!

Data science