1.2.1 당뇨병 데이터셋 소개
피마 인디언 당뇨 데이터셋을 이용해서 당뇨 여부를 예측
링크: https://www.kaggle.com/uciml/pima-indians-diabetes-database
데이터 구성
- Pregnancies : 임신 횟수
- Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
- BloodPressure : 이완기 혈압 (mm Hg)
- SkinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값
- Insulin : 2시간 혈청 인슐린 (mu U / ml)
- BMI : 체질량 지수 (체중kg / 키(m)^2)
- DiabetesPedigreeFunction : 당뇨병 혈통 기능
- Age : 나이
- Outcome : 768개 중에 268개의 결과 클래스 변수(0 또는 1)는 1이고 나머지는 0입니다.
1.2.2 학습과 예측을 위한 데이터셋 만들기
필요한 모듈 임포트
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt데이터셋 로드
- 드라이브 마운트를 해서 드라이브를 가상 작업환경에 올릴 수 있음
- 코랩은 가상환경에서 작업하는 것이고 런타임이 끊기거나 재시작 한다면 작업했던 모든 내용들과 업로드한 파일들, 생성한 파일들 모두 초기화되니 주의!

- 다운로드 해줬던 파일을 드라이브에 업로드 하고 이를 불러옴. 총 9개 변수에 대해 768개의 관측치가 존재
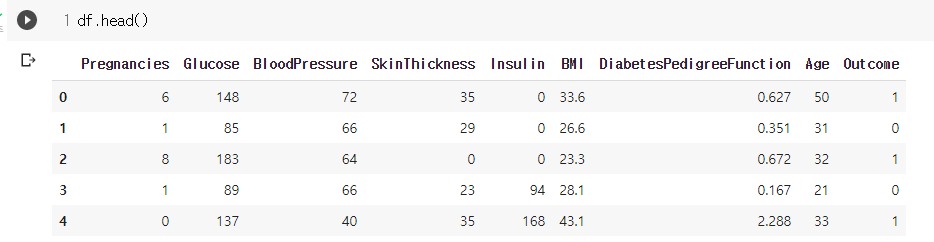
- Feature와 Target이 같이 있음. Outcome이 Target이고 나머지 변수들이 Feature로 활용
Train/Test dataset split
split_count = int(df.shape[0]*0.8)
split_count
- 관측치에 0.8을 곱한 후 int()를 이용해 정수로 떨어지게 변환
train = df[:split_count].copy()
train.shape
- split_count까지의 행을 train set으로 사용하고 원본 유지를 위해 참조만 하는 copy를 통해 데이터 셋을 할당.
- data frame도 리스트 슬라이싱과 같은 슬라이싱이 가능
test = df[split_count:].copy()
test.shape
- split_count 부터 마지막까지 test set으로 사용하고, test의 행의 수 + train 행의 수가 원본 data의 행의 수와 맞는지 확인
학습, 예측에 사용할 컬럼
feature_names = train.columns[:-1].tolist()
feature_names
정답값이자 예측해야 될 컬럼
label_name = train.columns[-1]
label_name
학습/예측 데이터셋 생성
X_train = train[feature_names]
print(X_train.shape)
X_train.head()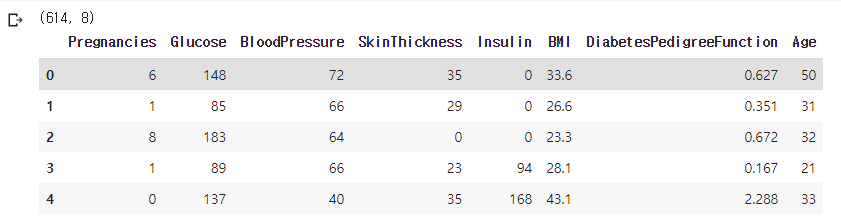
- 0에서 7번째 까지의 컬럼만 가져왔고 80%에 해당되는 관측치를 할당했기 때문에 shape은 (614, 8)
y_train = train[label_name]
print(y_train.shape)
y_train.head()
- 데이터 프레임에 []를 이용해 슬라이싱 했으므로 시리즈로 값 return. 따라서 shape이 (614,). (614,1)과 같은 열벡터라 생각. reshape을 해서 변경해줄 수 있음. 엄밀히 말하면 (614,1)처럼 매트릭스의 형태가 열벡터가 맞음.
X_test = test[feature_names]
print(X_test.shape)
X_test.head()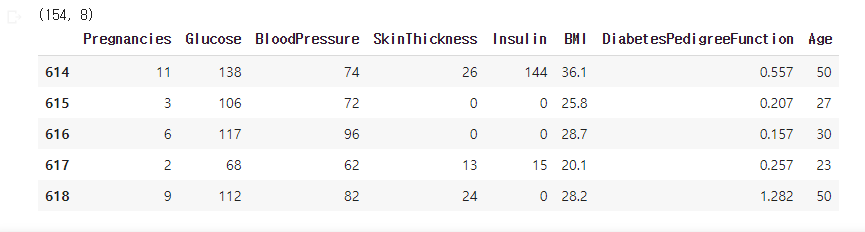
y_test = test[label_name]
print(y_test.shape)
y_test.head()
1.2.3 의사결정나무로 학습과 예측하기
머신러닝 알고리즘 가져오기
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model
- 디폴트 모델 생성
학습(Train)
from time import time
start = time()
model.fit(X_train, y_train)
print('학습에 소요된 시간은 {}'.format(time() - start))
- 데이터 사이즈가 작기도 하지만 트리 모델 자체가 학습에 소요되는 시간이 짧음. 단순한 모델이기 때문에
예측
y_pred = model.predict(X_test)
y_pred[:5]
- predict에는 y_test는 같이 안넣어줘도 됨.
1.2.4 예측한 모델의 성능 측정하기
트리 알고리즘 분석하기
from sklearn.tree import plot_tree
plt.figure(figsize = (20, 10))
plot_tree(model, feature_names = feature_names)
- 트리가 생겨나는 과정을 Text로 반환하고
- 트리의 구조 시각화. 노드에 해당되는 정보들이 보이질 않음
plt.figure(figsize = (20, 20))
tree = plot_tree(model, feature_names = feature_names, filled = True, fonsize = 10)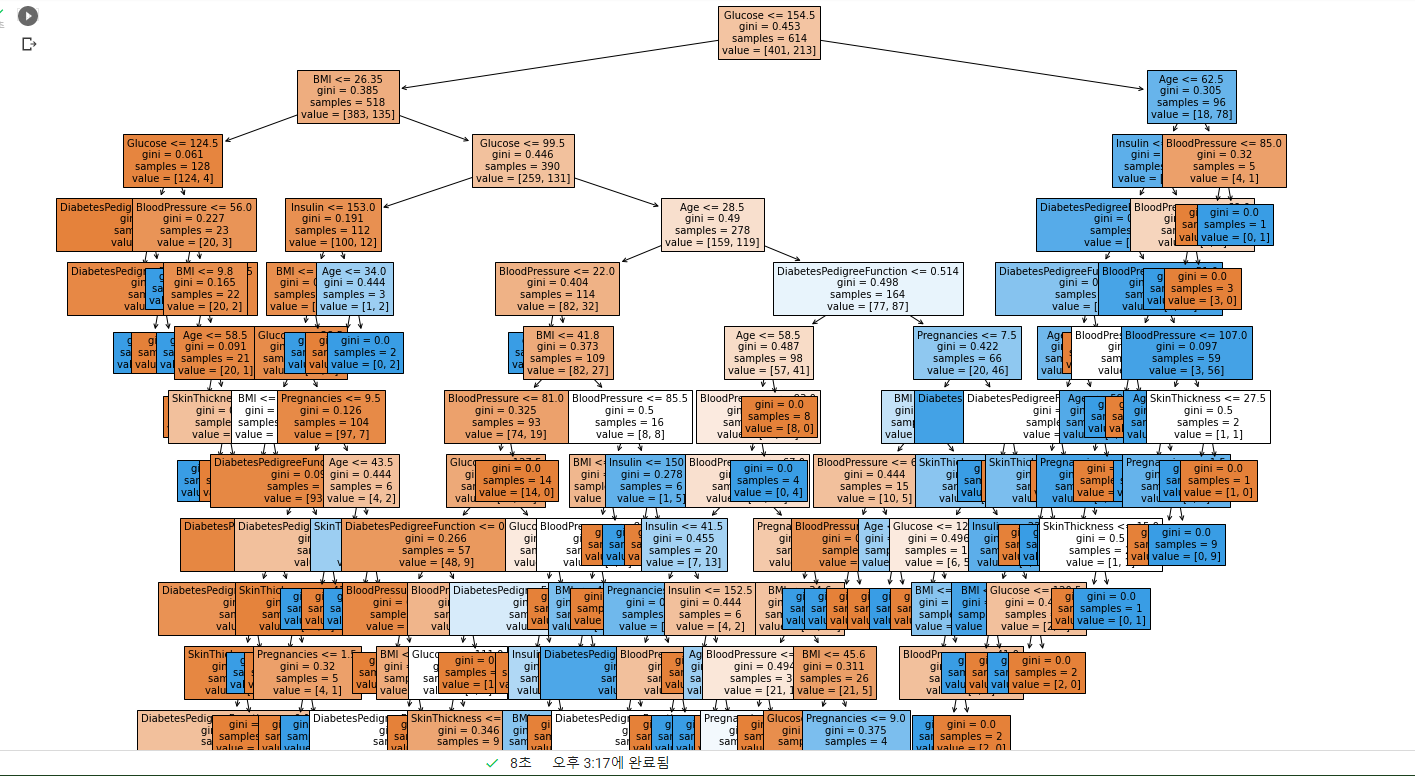
- fontsize를 키워주고 filled를 True로 해서 같은 컬럼은 같은 색으로 노드를 색칠.
- 글루코스, BMI등으로 tree의 가지가 나눠진다. 트리가 형성되는 과정은 분류 문제의 경우엔 불순도가 낮거나 정보획득이 많은 쪽으로 생겨남을 잊지 말기.
- 불순도: 다양한 클래스의 값들이 섞여있는 것
- 정보획득: 분기 이전의 불순도와 분기 이후의 불순도의 차이
- 트리의 기본 아이디어는, Leaf Node가 가장 섞이지 않은 상태로 완전히 분류되는 것, 즉 복잡성(entropy)이 낮도록 만드는 것.
import graphviz
from sklearn.tree import export_graphviz
dot_tree = export_graphviz(model, feature_names = feature_names, filled = True)
graphviz.Source(dot_tree)
- graphviz를 이용해 그래프를 더 크게 볼 수 있음.
- 배율을 0에 가까운 낮은 값으로 해서 저렇게 보이는 거지 100%로 한다면 엄청 크게 보임.

- 각 변수의 중요도는 위와 같고 어떤 변수의 중요도인지 한 눈에 보기 위해 seaborn의 barplot을 이용해 시각화!
plt.figure(figsize = (10, 7))
sns.barplot(x = model.feature_importances_, y = feature_names)
plt.show()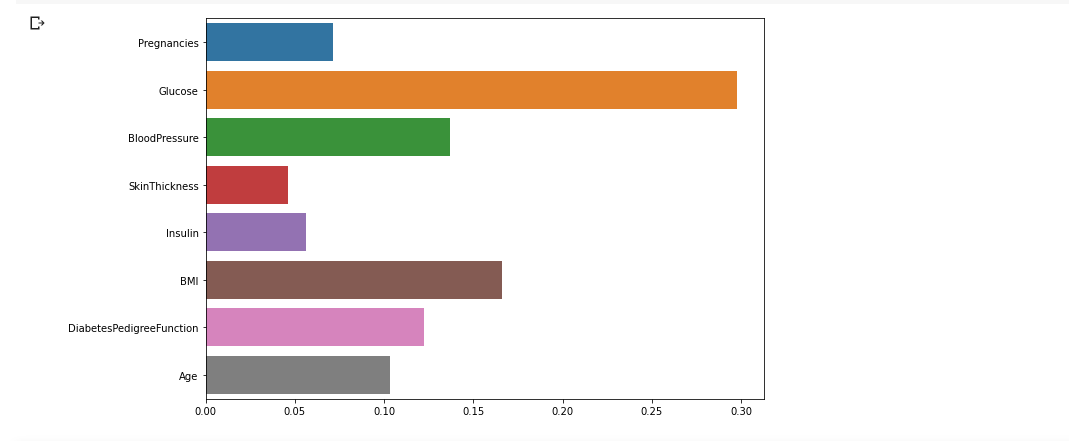
- 변수의 중요도는 글루코스, BMI, 혈압...의 순이고 중요도가 높다는 것은 그만큼 Target에게 영향력이 크다는 것. => Target 예측에 있어 중요한 feature라는 얘기.
정확도 예측하기
diff_count = abs(y_test - y_pred).sum()
diff_count
- y_test에는 0, 1값이 들어있고 마찬가지로 y_pred에도 0, 1 값이 있음. 제대로 예측을 했다면 0의 값이, 제대로 예측을 못했다면 -1의 값이 있을 것. 따라서 abs를 이용해서 0, 1로 만들어주고 sum을 해줘 제대로 분류하지 못한 횟수를 담아줌.

- 오분류율은 27%정도
- 디폴트 모델로 생성했고 random_state는 None이 디폴트라 강사님의 결과와 다름. random_state를 주지 않는다면 모델이 만들어 지는 부분에 random한 부분이 있다면 매 실행마다 모델이 조금씩 달라진다. 매번 같은 결과를 원한다면 random_state를 주길.

- model의 Accuracy(제대로 맞춘 경우)는 72%.
- 사이킷런의 metrics에 탑재된 accuracy를 써도 됨.

Data science