DIFIX3D+: Improving 3D Reconstructions with Single-Step Diffusion Models

DIFIX3D+: 2D single step diffusion 모델로 NeRF와 3DGS의 artifact를 보정하는 파이프라인
Abstract
NeRF, 3DGS 같은 3D reconstruction 기법으로 novel view synthesis를 하고 있다. 하지만 아직 시점이 극단적으로 변하면 artifact가 생기고 recon 품질이 떨어진다.
DIFIX3D+는 single step image diffusion 모델인 DIFIX를 사용해서 novel view를 렌더링할 때 생기는 artifact를 제거한다.
DIFIX의 역할은 두 단계에서 이루어진다.
- Reconstruction
초기 3D reconstructino에서 얻은 pseudo training view를 정제하고 다시 3D에 반영한다.
- Inference
최종 렌더링된 시점의 이미지에서 남아있는 artifact를 제거한다.
NeRF와 3DGS 모두에 적용 가능하다.
1. Introduction
현재 3D recon 할 때 많이 사용되는 NeRF나 3DGS는 시점이 극단적으로 바뀔 때 또는 적게 관찰된 장면들을 렌더링할 때 artifact가 존재한다는 한계가 있다.
NeRF와 3DGS의 대표적인 한계점은 per-scene optimization인데, 장면마다 따로 학습해야해서 데이터 준비가 까다롭다. 서로 다른 시점의 사진들이 정확히 정렬돼 있어야 한다. (view-consistency 있어야 함)
그리고 underconstrained reion에 대해서 interpolation으로만 해결하는 한계가 있다. (prior 없어서)
그래서 이 논문에서는 2D generative model(diffusion 같은)을 써서 대규모 이미지로 학습해서 다양한 장면들에 대해 일반화하고, inpainting이나 outpainting 같은 태스크에서 좋은 성능을 보였다.
DIFIX3D+에서는
single step diffusion 모델에 finetuning해서 3DGS/NeRF의 output을 보정(fix)할 수 있게 만들었다.
DIFIX로
-
Recon할 때 pseudo training view를 생성하고, 이걸 다시 3D에 반영한다. (distillation)
-
Inference 과정에서 렌더링된 이미지들에 실시간으로 post processing을 수행한다.
2. Related Work
- Improving 3D reconsruction discrepancies
많은 3D recon 기법들은 완벽한 input data(정확한 카메라 포즈, 일관된 조명)를 가정하는데, real world를 캡쳐할 때 조명 변화나 occlusion 때문에 artifact나 블러가 생길 수 있다.
기존에는 이를 해결하기 위해 (1) 카메라 파라미터를 최적화하거나 (2) 조명 보정 (3) 임시로 occlusion 처리 방법을 썼다.
하지만 이 방법들은 training 할 때만 보정이 가능하고 training이 끝나면 남은 오류를 없애지 못한다.
그래서 DIFIX3D+는 rendering 시점에도 DIFIX를 적용해서 남은 artifact를 해결하고 최종 품질을 높인다.
- Novel View Synthesis
기존에 recon할 때는 under observed 영역을 추론할 때 추측에 의존해야 해서 품질이 낮다는 문제가 있었다.
따라서 prior을 활용해서 이를 해결하고자 했다.
1) Geometric priors
Regularization, depth, normal 정보등을 pretrained model로 넣어준다. (ex. pretrained depth estimation 모델로 깊이를 보정해서 NeRF를 도와준다.)
이때 문제점은 노이즈에 민감하고, view가 많으면 효과가 없다.
2) multi view에서 학습된 feed forward nn
multi view 데이터 모아서 학습하고, 추론할 때 주변 시점들 참고해서 novel view를 생성한다.
하지만 정보가 적은 영역에서는 블러리하다.
3) Generative priors for novel view synthesis
progressive 3D update pipeline + fixer를 optimization, render time 모두에 사용
→ 품질 좋아짐
3. Background
NeRF는 MLP로 연속적인 3D volume을 모델링한다.
3DGS는 Gaussian으로 scene을 렌더링한다. 각각 position, rotation, opacity, color, scale을 갖고 있다.
Diffusion은 2D 이미지 분포를 학습해서 자연스러운 결과를 생성하는 모델이다. 데이터에 노이즈를 추가하고, denoise하는 방향으로 학습한다.
4. Boosting 3D Reconstruction with DM priors
GOAL: 무작위 시점에서 realistic novel view synthesis하기!
이를 위해서
- 3D representation이 생성한 novel view를 diffusion으로 보정해서 pseudo view로 재사용하고
- 최종 novel view 출력 결과를 실시간으로 후처리해서 artifact를 처리한다.
4.1. DIFIX: From a pretrained diffusion model to a 3D Artifact Fixer
⭐ diffusion으로 3D artifact 수정
input:
- : artifact 있는 novel view
- : reference view(clean)
output: 보정된 novel view
Single step diffusion model인 SD-Turbo 기반이다. 원래 image to image에 강력했던 diffusion 모델이다.
Reference view conditioning
DIFIX는 단순 보정이 아니라 reference view 정보까지 고려한다. Self attention이 쓰인다.
와 를 view dimension에 추가해서 concatenate하고 인코딩해서 latent 벡터 z를 얻는다.
C는 latent channel #, V는 input view #( + ), H와 W는 spatial latent 차원이다.
그 다음에 view 축과 spatial 축을 합쳐서 self attention을 적용하고 원래 형태로 복원한다.
이러면 2D diffusion 모델의 기존 self attention의 weight를 그대로 재활용하면서 multi view 간에 정보 교환을 할 수 있다.
결국 novel view가 많이 깨져있더라도 reference view에서 정보 잘 가져와서 보정할 수 있게 된다.
Fine-tuning
⭐ 어떻게 fine tuning해서 diffusion 모델을 3D artifact fixer로 사용할까?
Pix2pix-Turbo 학습 방식 따라감
- VAE encoder는 고정하고,
- LoRA로 decoder만 finetuning
학습할 때
- input으로 random noise 대신 artifact 있는 자체를 넣는다.
- 이때 낮은 노이즈 ε = 200를 적용한다.
artifact 이미지 = diffusion이 특정 노이즈(200) 레벨에서 보던 이미지 분포랑 유사하다는 점에서 나온 아이디어이다!
Losses
output 과 간 픽셀 차이를 측정하는 L2 loss를 사용한다.
그리고 perceptual loss인 LPIPS loss와 style을 보존하는 Gram loss도 사용한다.
DIFIX3D+ pipeline (Fig.2)
artifact 있는 이미지 고치고 → 다시 3D 모델 고치고 → 마지막 렌더링도 실시간으로 고침
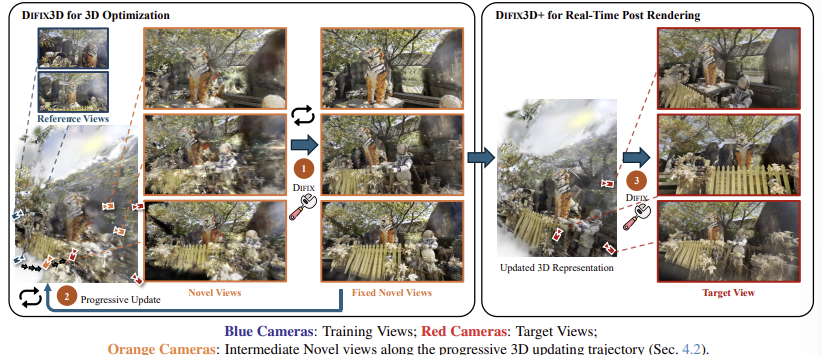
- 먼저 novel view 생성 → DIFIX로 보정
원래의 3D 모델로부터 novel view를 렌더링한다. 이 렌더링된 이미지들은 artifact 있음! 이걸 DIFIX에 넣어서 artifact 제거된 fixed novel views를 생성한다.
- Progressive update (3D optimization 반복)
Fixed novel views로 3D 모델을 다시 학습시키고 3D reprensentation을 업데이트한다. 이러면 원래 artifact 있던 부분도 개선된다.
이렇게 3D 모델 자체가 나아진다.
- Real time post rendering
최종적으로 업데이트된 3D 모델에서 target view를 렌더링한다. 이때도 artifact 있을 수 있으니까 DIFIX로 실시간으로 보정한다.
이러면 최종 렌더링 결과도 깨끗해짐!
DIFIX architecture (Fig.3)
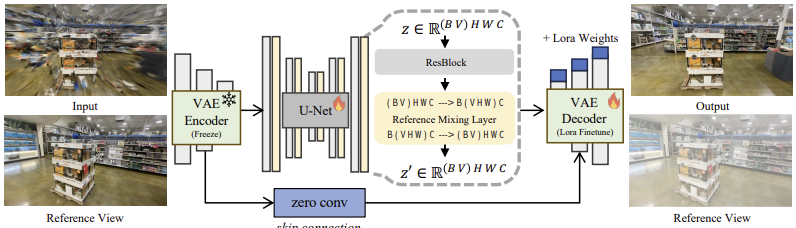
일단 Input으로
- NeRF or 3DGS로 렌더링한 artifact 이미지와
- Reference view (동일 scene clean image)
를 넣는다.
그 다음에 VAE 인코더를 거쳐서 input 이미지들을 latent vector z를 얻는다. 이때 인코더는 frozen 상태이다.(학습 x)
이때 latent vector 를 얻는다.
그 다음에 U-Net을 통과하는데 이때 reference와 input이 교차되어 여러 시점 사이의 정보들이 잘 섞인다.
view + spatial 하고 self attention을 적용한다.
그 다음에 LoRA를 적용한 pretrained 디코더로 를 다시 RGB 이미지로 복원한다.
따라서 최종적으로 artifact가 제거된 이미지가 나온다.
(모델이 만든 reference view도 같이 나오는데 사용하진 않음)
4.1.1 Data Curation
Input으로 들어갈 (, ) pair가 많이 필요하다.
보통 n번째 프레임만 학습에 사용하고 나머지는 test용 novel view로 렌더링하는데 이러면 train, test view가 비슷한 영역만 보고있는다는 문제점이 있다.
Solution:
- Cycle reconstruction
일부러 artifact가 있는 이미지를 만드는 방법이다.
Artifact가 있는 이미지를 DIFIX가 잘 고치는지 알고싶은데 현실에서는 artifact가 얼마나 생길지 알 수 없기 때문에 artifact가 있는 이미지를 일부러 만든다.
자율주행 데이터처럼 거의 직선 경로 따라서 촬영된 경우 사용된다. 경로를 수평으로 이동하고 렌더링하는 식으로 한다.
- Model Underfitting
일부러 NeRF가 제대로 학습되지 않게 만든다.
- Cross Reference
일반화하는 방법인데, 여러 카메라 중 하나만 NeRF 학습 시키는 방법이다.
현실에서 모든 카메라의 데이터를 다 얻기 어려울 수도 있고, 모델이 익숙하지 않은 시점에서도 잘 동작하는지 확인하기 위함이다.
4.2. DIFIX3D+: NVS with Diffusion Priors
학습된 diffusion 모델은 novel view를 렌더링하는 중에 적용될 수 있다. 하지만 추론 중에 계속 넣다보면 3D scene의 일관성이 떨어진다. (특히 noisy 영역)
따라서 바로 고치는게 아니라 diffusion 모델의 output을 distill해서 3D representation에 훈련 중에 넣는다. 이러면 multi view 일관성이 높아진다. 그리고 마지막 렌더링 단계에서도 artifact를 제거하는 과정을 거친다.
⭐3D를 계속 업데이트하고 실시간으로 후처리해서 artifact를 없앤다.
DIFIX3D: Progressive 3D updates
Reference view에서 멀리 떨어진 시점을 렌더링할 때는 diffusion 모델이 참고할 정보가 부족해서 결과가 좋지 않다.
이를 해결하기 위해 progressive training을 한다.
- Reference 이미지들로 NeRF 먼저 학습
- 학습 중에
- 1.5k iteration마다 카메라 위치 조금 이동 (target view로)
- 그 위치에서 novel view 렌더링하고 DIFIX로 보정
- fixed 이미지를 학습 데이터로 사용
- 반복
점점 target view 근처에서 더 많은 3D 힌트를 갖게 돼서 멀리 떨어진 시점도 잘 recon할 수 있게 된다.
DIFIX3D+: Real-Time Post Render Processing
학습하면서 여러 번 fix하긴 했지만 그래도 artifact가 남아있을 수 있으니 마지막에 삭제해준다.
한번만 denoising 하기 때문에 실시간으로 가능하다.
5. Experiments
