Machine Learning 12주차
Dimension Reduction
feature 차원이 증가하면, 시각화와 데이터를 분석할 때 한계가 있다.
PCA 같은 dimension reduction 알고리즘은 기존 특징 중 일부만 선택하는게 아니라, 기존 특징들의 proportion들을 조합해서 새로운 차원의 구성 요소를 만든다.
Principal Component Analysis (PCA)
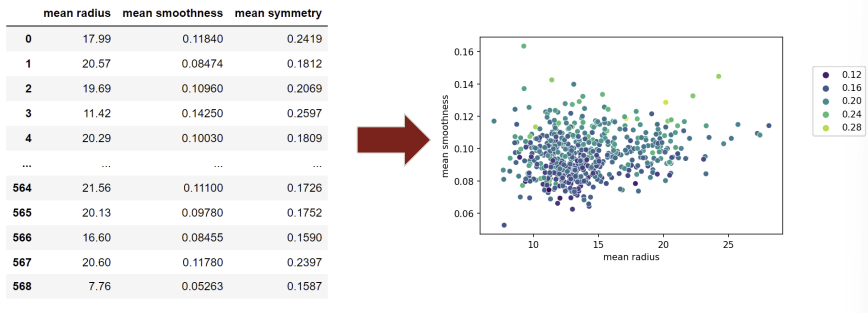
PCA outcome:
1. Reduce number of dimensions in data
- transformation으로 n feature를 작은 component로 감소
- does not simply select a subset of features
2. Show which features explain the most variance in the data
feature들 중에서 데이터를 더 잘 설명하는 특정 feature가 있다.
데이터에 label이 존재하면, 각 특징이 얼마나 중요한지 판단하기 쉽지만 unlabeled 데이터에서는 이런 중요도를 측정하기 어렵다.
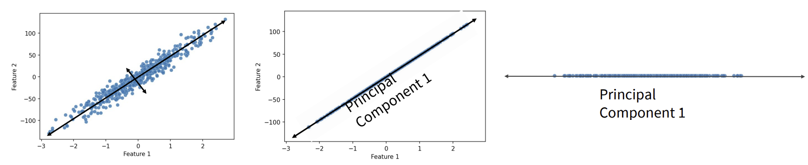
- 데이터가 분포된 방향으로 principal component(주성분)를 찾는다.
- principal component: 분산 설명하는 축
- 데이터의 variance를 기준으로 새로운 축 정의
- 데이터가 principal component 1 축을 기준으로 projection 된다.
Principal Component:
- component of original features
- 각 feature가 가진 variance가 클수록 principal component에 더 큰 영향을 미친다.
→ feature가 2개 있을 때 1개의 feature로 줄인 경우, principal component는 original data의 특정 비율(ex. 90%)을 설명한다. 데이터의 차원을 줄여도 중요한 정보(variance를 많이 설명하는 축)는 보존된다.
Mathematic
Mathematical expression..
PCA는 original feature들의 normalized된 linear combination으로 이루어진 새로운 차원 집합(principal component)을 만든다.
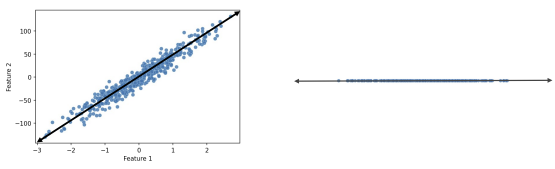
2차원에 분포되어있던 feature 1, 2가 더 많은 분산을 갖고 있는 방향으로 principal component가 정해졌다. 데이터에 principal component가 projection되어 차원이 감소하였다.
→ principal component가 original feature들의 linear combination으로 표현된다는 것을 보여준다.
- , : weight (각 feature의 principal component에 대한 가중치)
- : original data의 feature
- : 의 linear combination으로 계산된 principal component
Calculate
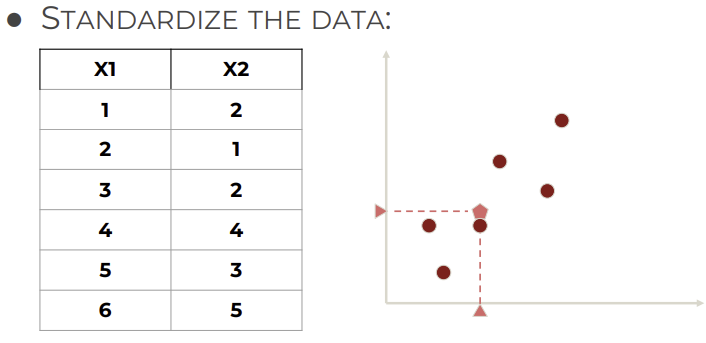
1. 2D dataset
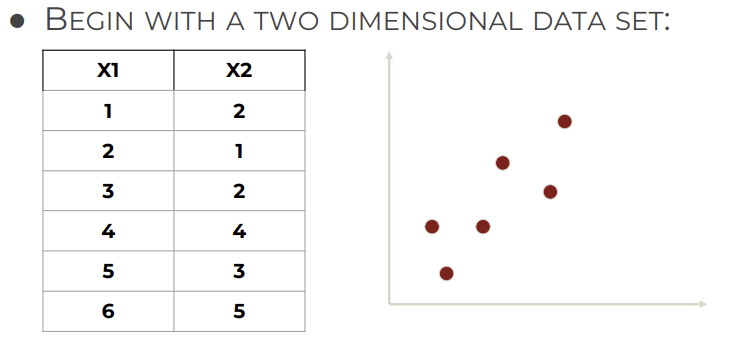
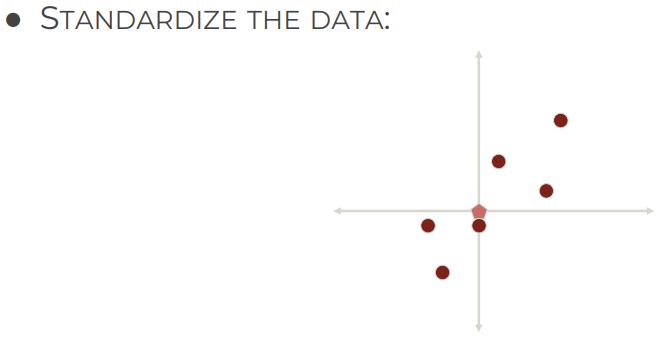
2. Standardize data
- Standardize: 평균 0, 표준편차 1 되도록 변환하는 과정
→ 데이터 스케일 맞춰서 특징들 영향 불균형 방지
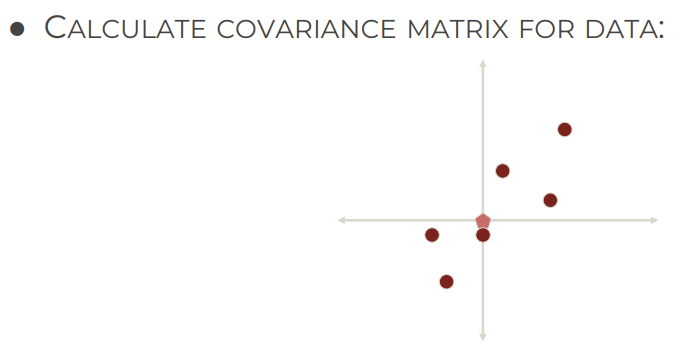
3. Calculate covariance matrix for data
4. Linear transformation of data



5. Eigenvector: directional information

6. Eigenvalue: magnitude information
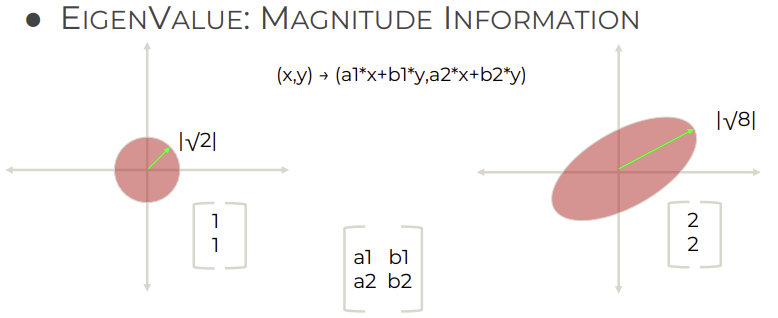
7. Orthogonal eigenvector

Eigenvector is just a linear transformation
