Ensemble
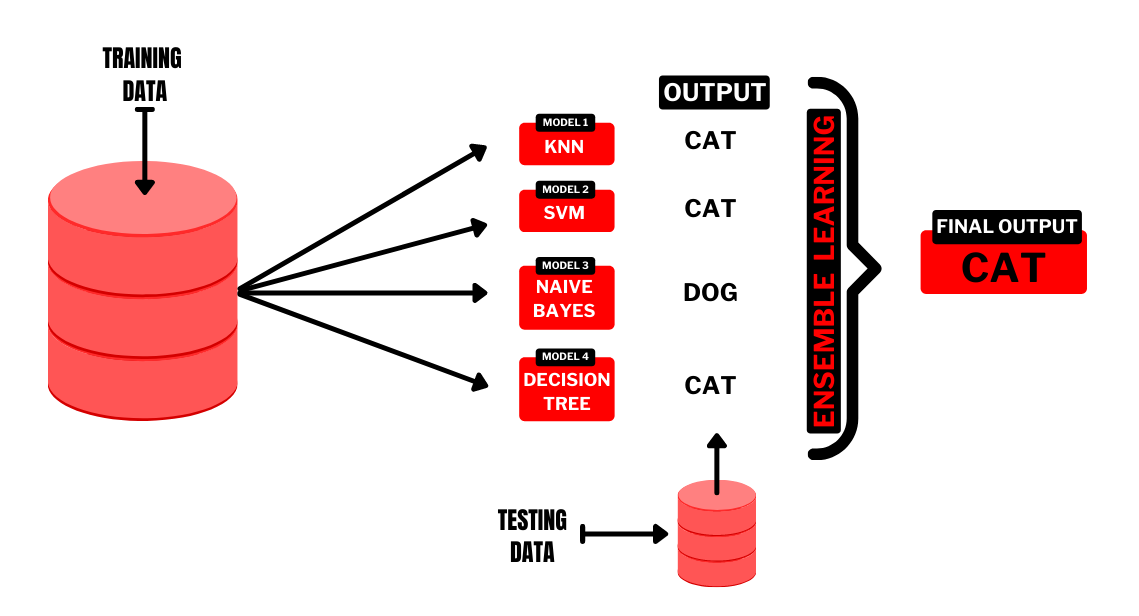
여러 개의 분류기를 생성하고, 그 예측을 결합함으로써, 보다 정확한 예측을 도출하는 기법
다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측 값을 얻는 것이 목표.
강력한 하나의 모델을 사용하는 대신, 보다 약한 모델 여러개를 조합하여 더 정확한 예측에 도움을 주는 방식.

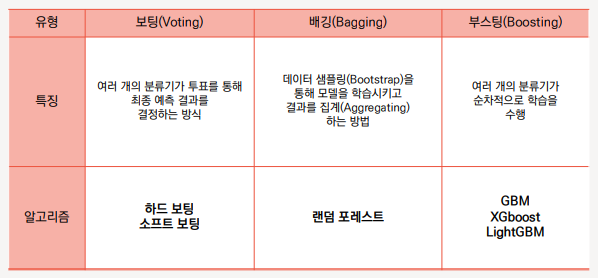
앙상블 학습은 일반적으로 보팅(Voting), 배깅(Bagging), 부스팅(Boosting) 세 가지의 유형으로 나눌 수 있다.
1. 보팅 (Voting)
-
여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식.
-
서로 다른 알고리즘을 여러 개 결합하여 사용.
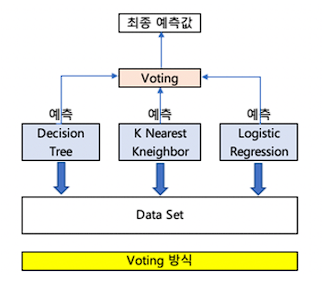
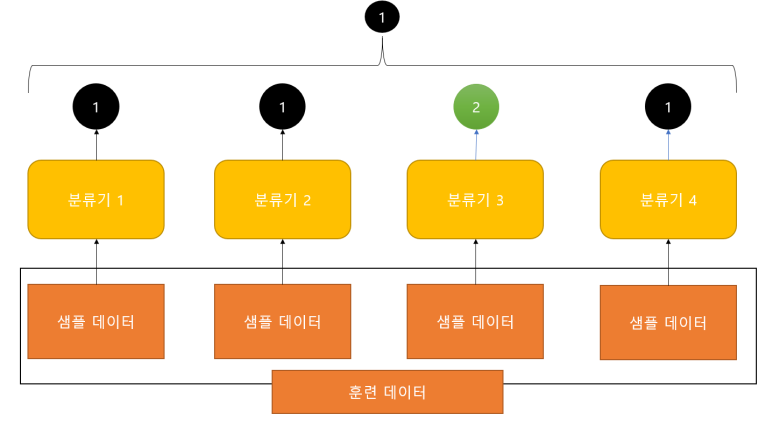
하드 보팅(Hard Voting)
다수의 분류기가 예측한 결과값을 최종 결과로 선정. (다수결의 원칙)
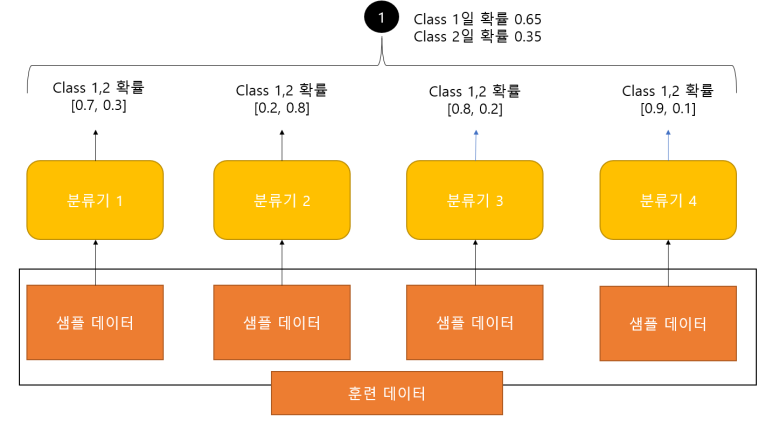
소프트 보팅(Soft Voting)
모든 분류기가 예측한 레이블 값의 결정 확률 평균을 구한 뒤, 가장 확률이 높은 레이블 값을 최종 결과로 선정. (확률 스코어 경쟁)
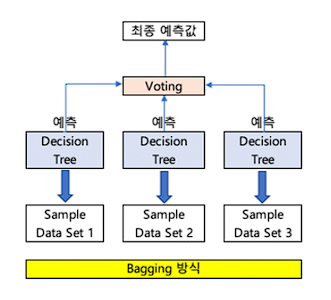
2. 배깅 (Bagging)
-
데이터 샘플링(Bootstrap) 을 통해 모델을 학습시키고 결과를 집계(Aggregating) 하는 방법.
-
모두 같은 유형의 알고리즘 기반의 분류기를 사용.
-
데이터 분할 시 중복을 허용.
-
과적합(Overfitting) 방지에 효과적
Categorical Data : 다수결 투표 방식으로 결과 집계
Continuous Data : 평균값 집계
대표적인 배깅 방식 : 랜덤 포레스트 알고리즘
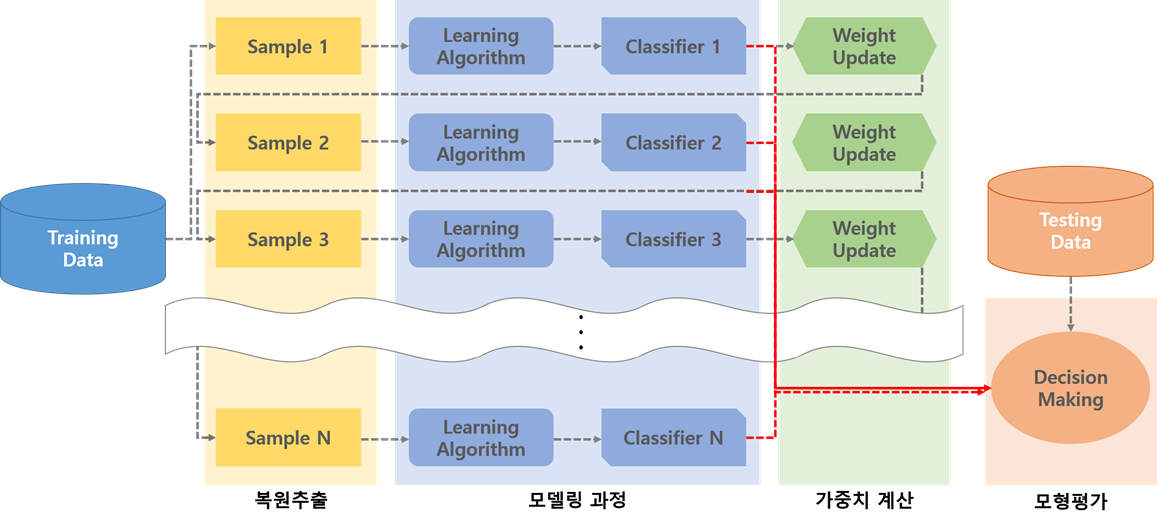
3. 부스팅 (Boosting)
-
여러 개의 분류기가 순차적으로 학습을 수행.
-
이전 분류기가 예측이 틀린 데이터에 대해서 올바르게 예측할 수 있도록 다음 분류기에게 가중치(weight)를 부여하면서 학습과 예측을 진행.
(학습하면서 이전 모델의 단점 보완을 반복) -
계속해서 분류기에게 가중치를 부스팅하며 학습을 진행하기에 부스팅 방식이라고 불림.
-
예측 성능이 뛰어나 앙상블 학습을 주도
-
대표적인 부스팅 모듈 – XGBoost, LightGBM
※ 보통 부스팅 방식은 배깅에 비해 성능이 좋지만, 속도가 느리고 과적합이 발생할 가능성이 존재하므로 상황에 따라 적절하게 사용해야 함.
<과정>
-
한 round 당 하나의 모델을 학습시킨다.
-
각 round 당 오분류된 객체들에 가중치를 조절한다.
-
다시 모델을 학습시킨다.
-
위 과정을 반복한다.