오늘은 CNN의 아키텍쳐에 대해 공부해봤습니다.
앞에서 CNN이 Convolution 연산을 통해 계산을 수행한다는 것은 알았습니다.
이제 Convolution 연산을 할 때, 필요한 개념들에 대해 공부하려고 합니다.
📚 Kernel(커널)
커널은 Receptive Field(수용장) 라고 생각하면 됩니다.
CNN은 인간의 인지 구조를 본떴다고 알려져 있습니다. (실제로 그런지는 모르지만)
인간은 특정 사물을 볼 때, 수용장을 토대로 인식합니다. 마찬가지로 CNN도 수용장의 개념을 이용합니다.
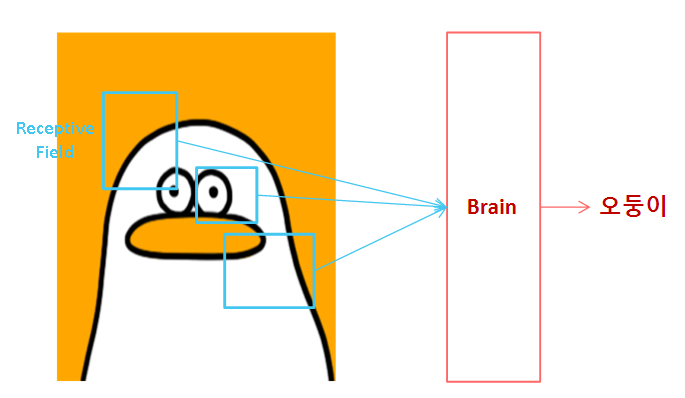
이는 CNN 모델을 구성할 때, '커널'로 불립니다. ('필터'라고 불리기도 합니다.)
커널의 크기는 Convolution 연산 진행시 나오는 Feature Map에서 한 부분이 얼마나 데이터의 함축적인 부분을 요약하는지 알려주는 지표입니다.
즉, 커널의 크기를 크게 설정할수록 부분이 더 함축적인 데이터를 담고 있습니다.
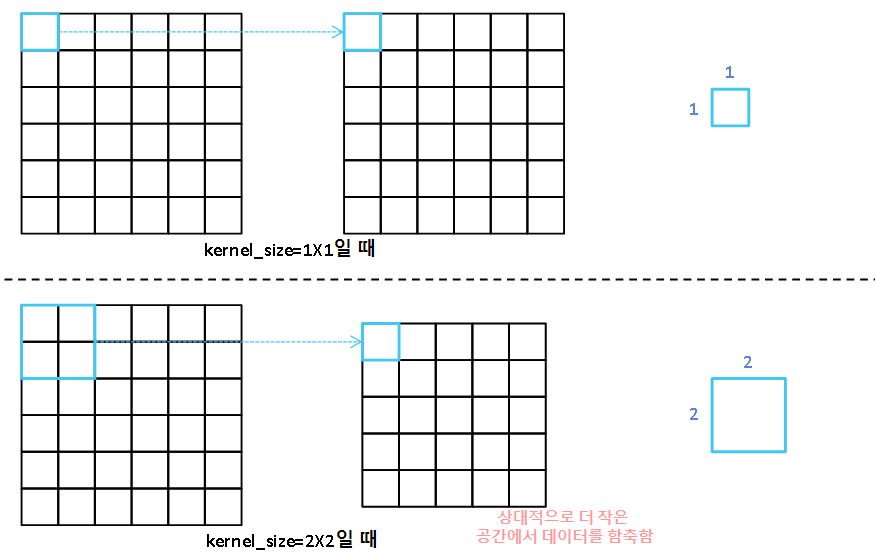
예를 들어, 3x3짜리 커널이라고 한다면 3x3만큼의 크기를 한 수용장으로 봐서 Convolution 연산을 진행하는 모델인 겁니다.
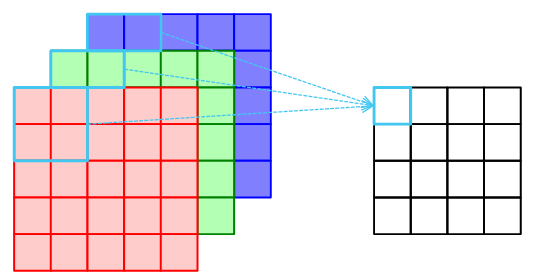
데이터가 3차원인 경우(RGB와 같은 이미지)에는 각 채널에 Kernel만큼 Convolution 연산을 적용합니다.
📚 Stride(스트라이드)
스트라이드는 커널이 움직이는 스텝입니다.
Convolution연산을 진행할 때, 커널의 크기를 수용장으로 가지며 슬라이딩 윈도우 방식으로 이동합니다.
이때, 슬라이딩 윈도우 방식은 단순히 1칸씩 이동할 수도 있지만, 사용자가 직접 지정할 수도 있습니다.
예를 들어,
Stride=1인 경우, 커널이 한 칸씩 이동하며 합성곱을 수행합니다.
Stride=2인 경우, 커널이 두 칸씩 이동하며 합성곱을 수행합니다.
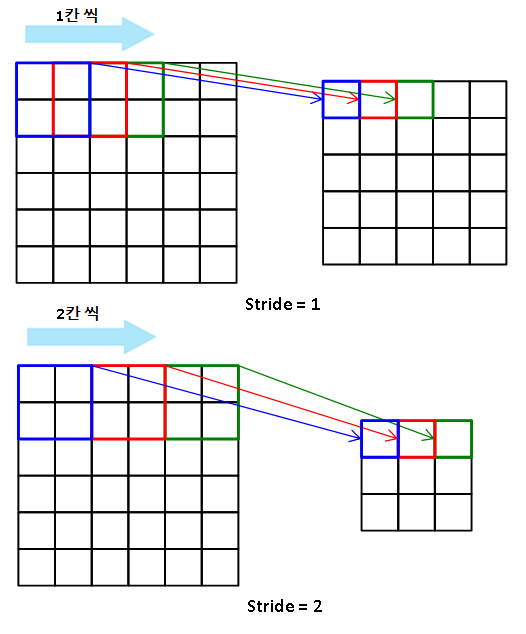
스트라이드의 크기가 커질수록 Feature Map의 크기는 작아집니다.
또한, 스트라이드 크기를 너무 크게 설정하면 데이터의 손실이 발생할 수 있다는 것에 주의해야 합니다.
📚 Padding(패딩)
패딩은 데이터의 크기를 키워주는 역할을 합니다.
일반적으로 데이터의 손실이나 불균형을 막아주기 위해 적용합니다. 여기서 말하는 불균형은 어떤 데이터는 3번 합성곱을 계산하고, 다른 데이터는 1번 합성곱을 계산하는 경우를 말합니다.
스트라이드가 1이며, 커널 사이즈가 3X3인 경우를 살펴보면 이해하기 편합니다.
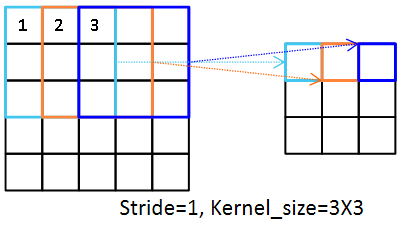
커널 사이즈가 3X3인 경우, 1번 데이터는 합성 곱 연산이 1회 수행되고, 2번 데이터는 2회, 3번 데이터는 3회 수행됩니다. 이는 데이터의 불균형을 야기할 수 있습니다.
또한, 이렇게 합성 곱 연산을 진행하면 데이터의 크기가 줄어들게 되거나, 스트라이드가 1이 아닌 다른 값인 경우 각 끝의 데이터가 연산에 들어가지 못하는 경우가 생길 수 있습니다.
이 경우, 원본 데이터의 손실이 일어날 수 있습니다.
이러한 문제를 해결하기 위해 데이터에 패딩을 적용합니다.
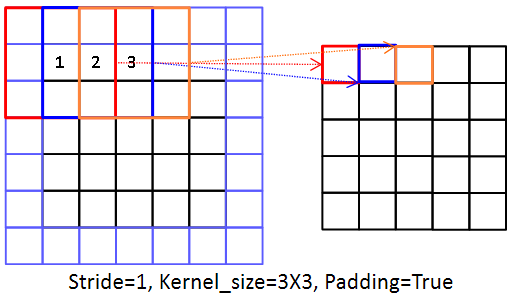
이렇게 패딩을 적용하면, 원본 데이터의 1번 데이터는 연산이 2회, 2번 데이터는 3회, 3번 데이터는 3회 수행됩니다. 또한, 반환되는 Feature Map이 원본 데이터와 동일하게 5X5로 유지됩니다.
이때, 패딩의 값은 주로 0으로 채워집니다. 이를 Zero-Padding(제로 패딩)이라고 부릅니다.
이렇게 커널 크기, 스트라이드, 패딩에 따라 Feature Map의 크기가 달라집니다.
Feature Map의 크기를 구하는 공식은 다음과 같습니다.

텐서플로우에서 Conv2D를 적용할 때, padding='same'으로 설정한 경우 stride=1이면 Output Feature Map의 크기가 Input Feature Map의 크기와 동일하게 만들어줍니다.
stride!=1이면 Input Feature Map에서 스트라이드로 인해 연산을 진행하지 못하는 부분이 안 생기도록 패딩을 적용합니다.
📚 Pooling(풀링)
풀링은 패딩과 반대되는 개념으로 Feautre Map을 일정 수용장에서 다운 샘플링합니다.
일반적으로 CNN 모델의 경우, 합성 곱 연산을 진행한 후 풀링을 적용합니다.
이는 파라미터 수가 너무 많아지는 것을 방지해줍니다. 이를 통해, 과적합 문제도 완화시켜 줍니다.
풀링은 보통 Max Pooling과 Average Pooling을 사용합니다.
✅ Max Pooling
맥스 풀링은 정해진 수용장에서 최대 값을 뽑아줍니다.
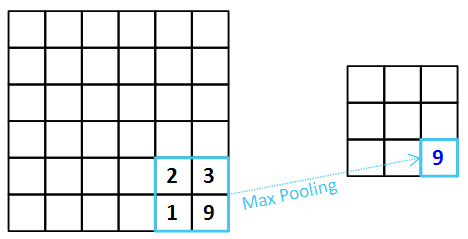
맥스 풀링을 적용한 경우 Feature Map의 특징을 더 잘 뽑아줍니다. 따라서 Ouput Feature Map이 Sharp해진다는 특징이 있습니다.
일반적으로 맥스 풀링을 많이 적용합니다.
✅ Average Pooling
에버리지 풀링은 정해진 수용장에서 평균 값을 뽑아줍니다.
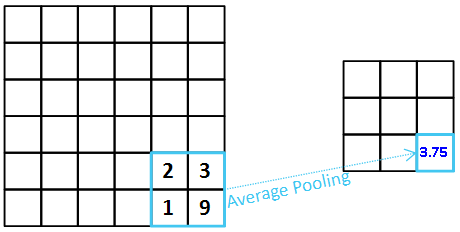
에버리지 풀링은 Feature Map의 특징을 뭉그러뜨립니다. 따라서 맥스 풀링에 비해 Output Feature Map이 Dull해집니다.
에버리지 풀링은 Fully Connection Layer로 가기 전 Flatten 대신 GlobalAveragePooling처럼 차원 단위로 풀링을 적용할 때, 자주 쓰입니다.
텐서플로우에서 간단한 모델을 만들어보면 다음과 같습니다.
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Input, Flatten, GlobalAveragePooling2D, Conv2D, Dropout
from tensorflow.keras.layers import Activation, BatchNormalization
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
INPUT_SIZE = 32
def create_model():
input_tensor = Input(shape=(INPUT_SIZE, INPUT_SIZE, 1))
x = Conv2D(filters=32, kernel_size=(3, 3), padding='same')(input_tensor)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=32, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(filters=64, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=64, kernel_size=(3, 3), padding='same')(input_tensor)
x = Activation('relu')(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(filters=128, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=128, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(filters=256, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=256, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=512, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=512, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = GlobalAveragePooling2D()(x)
x = Dropout(rate=0.5)(x)
x = Dense(300, activation='relu', name='fc1')(x)
x = Dropout(rate=0.3)(x)
output = Dense(10, activation='softmax', name='output')(x)
model = Model(inputs=input_tensor, outputs=output)
return model
model = create_model()
# model_check_cal = ModelCheckpoint(filepath="DACON_IMAGE_CLF{epoch:02d}-{val_loss:.2f}.weights.h5", monitor='val_loss', verbose=1, save_best_only=True, save_weights_only=True, mode='min')
erl_cb = EarlyStopping(monitor='val_loss', patience=30)
reduce_lr_cb = ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=15, verbose=1, mode='min')
model.compile(metrics=['accuracy'], loss='categorical_crossentropy', optimizer=Adam(0.001))
model.fit(train_images, oh_train_labels, batch_size=16, epochs=200, validation_data=(val_images, oh_val_labels), callbacks=[reduce_lr_cb, erl_cb])📜 Reference
딥러닝 CNN 완벽 가이드 - TFKeras 버전
11-01 합성곱 신경망(Convolution Neural Network)
