ObjectDetection을 공부하면서 새로운 tool을 익히고 까먹으면 다시 찾아보는 과정이 귀찮아서 만들게 된 게시물입니다.
공부 목적이니 궁금하시거나 오류가 있을 경우 알려주시면 감사하겠습니다.
OpenCV는 Computer Vision을 더 쉽게 다루도록 해준 tool입니다.
오늘은 그중에서도 DNN에 대해 알아볼 예정입니다.
📚 Architecture
dnn 사용법을 알아보기 전에 큰 틀로 알아보면 더 쉽습니다.
dnn을 사용해 pretrained된 모델(tensorflow 기반)을 가지고 와 inference하려면 모델을 빌드하는 과정, 데이터를 모델에 맞게 입력하는 과정, 최종적으로 모델이 결과 값을 반환해주는 과정이 있습니다.
이후에 결과 값을 이미지에 표현하는 것은 사용자의 재량에 따라 코드가 달라질 수 있습니다.
여기서는 opencv를 이용해 시각화 하는 방법을 알아보겠습니다.
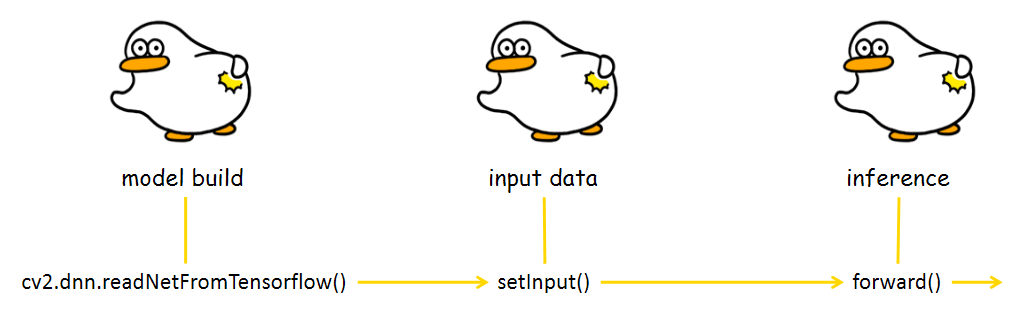
📚 readNetFromTensorflow()
우선, pretrained된 모델을 가져와야 합니다.
opencv에서는 readNetFromTensorflow API를 이용해 tensorflow기반의 모델을 가져올 수 있습니다.
인자로는 checkpoint file, config file을 입력받습니다.
import cv2
cv_net = cv2.dnn.readNetFromTensorflow('/content/pretrained/ssd_inception_v2_coco_2017_11_17/frozen_inference_graph.pb',
'/content/pretrained/ssd_config_01.pbtxt')checkpoint file과 config file은 opencv 공식 깃허브에 나와있습니다.
TensorFlow Object Detection API
📚 setInput()
pretrained된 모델을 가져와 객체로 만들었습니다.
하지만, 모델마다 학습에 사용된 input은 다를 것입니다.
opencv에서는 모델 객체의 setInput 메서드를 이용해 입력받는 이미지를 사용자가 정할 수 있습니다.
cv_net.setInput(cv2.dnn.blobFromImage(img_array, size=(300, 300), swapRB=True, crop=False))setInput 메서드는 인자로 cv2.dnn.blobFromImage() 혹은, cv2.dnn.blobFromImages()를 받습니다.
blobFromImage의 인자는 다음과 같습니다.

-
image : 입력받는 이미지 array
-
scalefactor : 이미지 값에 곱할 값
-
size : 출력 이미지의 크기
-
mean : 입력 이미지의 각 채널에서 뺄 값
-
swapRB : R과 B 채널을 바꿀 것인지 결정하는 플래그
-
crop : crop수행 여부
-
ddepth : 출력 블롭의 깊이(CV_32F 또는 CV_8U)
📚 forward()
모델을 만들고, input 값을 넣는 과정까지 진행했습니다.
이제 모델이 추론하여야 합니다.
opencv에서는 model.forward() 메서드를 이용해서 추론한 값을 쉽게 얻을 수 있습니다.
forward() API에는 인자로 layer name이 들어갈 수 있습니다.
하나의 layer만 넣을 때는 string형식으로 넣어도 되고, 리스트로 감싸 넣어도 됩니다. 다만, 여러 layer의 결과를 보고싶을 때에는 리스트로 꼭 감싸주셔야 합니다. 아무것도 넣지 않으면 마지막 layer 출력 값이 나옵니다.
cv_out = cv_net.forward()이렇게 출력된 cv_out은 4차원 형태를 가진 ndarray입니다.
( ○ , ○, 100, 7) 형태의 shape로 되어있는데 맨 처음 ' ○ '는 output layer 갯수이며, 두번째 ' ○ '는 입력된 이미지 갯수입니다. 3번째 ' 100 '은 모델이 예측한 100개의 object입니다. 마지막 ' 7 '은 ( ○, class_id, inference_score, xmin, ymin, xmax, ymax)형태를 가집니다. ' ○ '는 무시해도 되는 값입니다.
한 이미지에서 100개의 object만큼 넉넉하게 찾은 다음 inference_score를 기준으로 걸러내는 것입니다.
이 부분에서는 사용자가 직접 코딩으로 구현해야 합니다.
주의할 점은 setInput에서 입력 이미지를 resize해줬기 때문에 forward에서 나온 bbox 결과값은 resize된 이미지를 기반으로 전처리된 값으로 나오게 됩니다. 따라서 원본 입력 이미지의 row와 col값을 곱해줘야 합니다.
import matplotlib.pyplot as plt
import cv2
img = cv2.imread('/content/data/beatles01.jpg')
# 원본 이미지 (633, 806)를 네트웍에 입력시에는 (300, 300)로 resize 함.
# 이후 결과가 출력되면 resize된 이미지 기반으로 bounding box 위치가 예측 되므로 이를 다시 원복하기 위해 원본 이미지 shape정보 필요
rows = img.shape[0]
cols = img.shape[1]
# cv2의 rectangle()은 인자로 들어온 이미지 배열에 직접 사각형을 업데이트 하므로 그림 표현을 위한 별도의 이미지 배열 생성.
draw_img = img.copy()
# 원본 이미지 배열을 사이즈 (300, 300)으로, BGR을 RGB로 변환하여 배열 입력
cv_net.setInput(cv2.dnn.blobFromImage(img, size=(300, 300), swapRB=True, crop=False))
# Object Detection 수행하여 결과를 cv_out으로 반환
cv_out = cv_net.forward()
print(cv_out.shape)
# bounding box의 테두리와 caption 글자색 지정
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# detected 된 object들을 iteration 하면서 정보 추출
for detection in cv_out[0,0,:,:]:
score = float(detection[2])
class_id = int(detection[1])
# detected된 object들의 score가 0.4 이상만 추출
if score > 0.4:
# detected된 object들은 image 크기가 (300, 300)으로 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
# labels_to_names 딕셔너리로 class_id값을 클래스명으로 변경. opencv에서는 class_id + 1로 매핑해야함.
caption = "{}: {:.4f}".format(labels_to_names[class_id], score)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(draw_img, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, red_color, 2)
print(caption, class_id)
img_rgb = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
plt.imshow(img_rgb)mask rcnn을 배우며 mask정보와 bbox정보에 대해 공부하였으므로 여기에 끼워넣겠습니다.
앞에서 forward에 인자로 layer name이 들어갈 수 있다고 했습니다.
이는 layer name이 가르키는 layer가 반환한 값을 출력하라는 의미입니다.
boxes, masks = cv_net_mask.forward(['detection_out_final', 'detection_masks'])위 코드의 의미는 'detection_out_final' layer name을 가진 layer와 'detection_masks' layer name을 가진 layer에서 반환하는 값을 의미합니다.
mask rcnn 모델의 경우 bbox정보와 mask 정보를 가집니다. 여기서 cv_net_mask는 mask rcnn 모델 객체입니다.
boxes 정보는 앞에서 언급한 format과 똑같습니다.
masks는 (100, n, 15, 15) shape를 띕니다.
100은 예측한 object의 수, n은 category 개수, 15X15는 mask shape입니다.
boxes에서 100개의 object를 예측했고 그 박스 안에서 category n개에 따라 15X15 mask 정보를 제공합니다.
하지만, 모든 box가 15X15라는 보장은 없죠. 따라서 mask를 15X15에서 box 크기에 맞게 resize해줘야 합니다.
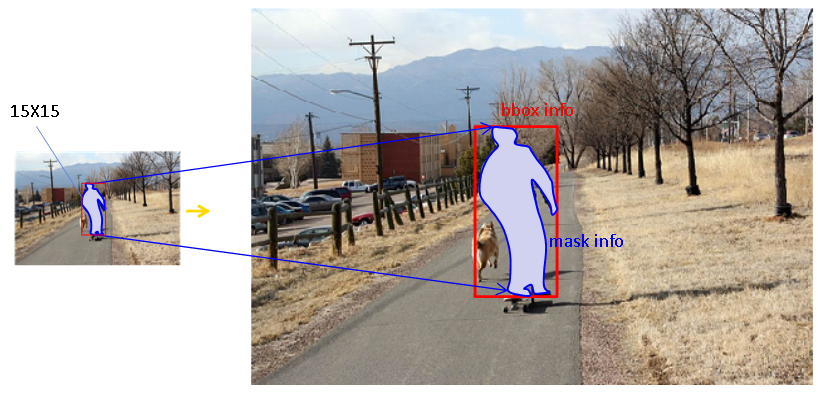
위 그림에서는 15X15에 bbox도 표시했지만, 실제로 bbox는 원본 이미지 기준으로 나오고 mask 정보만 15X15 안에서 나옵니다.(15X15에 그려진 bbox는 이해하기 쉬우라고 그린 것입니다.)
📚 Video
opencv를 활용해 비디오를 다루는 방법도 간단합니다.
참고로 get_detected_img( )함수는 detect된 이미지를 BGR 형태로 반환하는 함수입니다.
def do_detected_video(cv_net, input_path, output_path, score_threshold, is_print):
cap = cv2.VideoCapture(input_path)
codec = cv2.VideoWriter_fourcc(*'XVID')
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
vid_fps = cap.get(cv2.CAP_PROP_FPS)
vid_writer = cv2.VideoWriter(output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt, )
while True:
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
break
returned_frame = get_detected_img(cv_net, img_frame, score_threshold=score_threshold, is_print=True)
vid_writer.write(returned_frame)
# end of while loop
vid_writer.release()
cap.release()-
VideoCapture() : 인자로 영상 경로를 입력받습니다.(아마 영상을 입력받으면 그에 대한 frame 및 정보를 꺼내기 위해서라고 파악됩니다.)
-
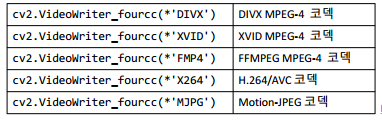
VideoWriter_fourcc() : 코덱은 영상을 복원/압축하는 기술을 말합니다. 이 메서드를 사용해 그 종류를 정할 수 있습니다.
종류는 다음과 같습니다.
VideoCapture() 메서드를 통해 만들어진 cap 객체를 활용해 영상의 size 및 다양한 정보를 알 수 있습니다.
-
cap.get() : video 객체에서 get()메서드를 이용해 비디오를 저장하기 위해 필요한 정보들을 가져올 수 있습니다. get()메서드에 인자로 어떤 값이 들어가냐에 따라 얻을 수 있는 정보는 다릅니다. 들어가는 인자는 cv2.CAP_PROP으로 시작합니다.
-
cv2.CAP_PROP_FRAME_FPS : fps정보를 가져옵니다.
-
cv2.CAP_PROP_FRAME_WIDTH : 가로 사이즈를 가져옵니다.
-
cv2.CAP_PROP_FRAME_HEIGHT : 세로 사이즈를 가져옵니다.
-
cv2.CAP_PROP_FRAME_COUNT : 프레임 수를 가져옵니다.
-
cv2.VideoWriter() : 최종적으로 영상을 저장할 경로, 코덱, fps, 사이즈를 입력받습니다. 이렇게 만들어진 vid_writer 객체는 write()메서드를 통해 한 프레임씩 넣을 수 있게 됩니다.
-
cap.read() : cv2.VideoCapture 객체에서 read() 메서드를 호출하면 한 프레임씩 이미지를 가져오게 됩니다. 이때 반환값은 두개입니다. frame이 끝났는지 아닌지에 관한 값. 한 frame 이미지에 대한 값입니다.
-
vid_writer.write() : 만들어진 이미지를 경로에 저장하는 메서드입니다. 인자로는 이미지가 들어갑니다. 주의할 점은 이미지는 BGR형태여야 한다는 점입니다.
📜 Reference
