머신러닝을 공부하면서 분류에 모델을 다시 공부하게 되었습니다.
오늘은 분류 모델에 대한 평가지표를 공부해 봤습니다.
0️⃣ Accuracy(정확도)
정확도는 실제 데이터에서 예측 데이터가 얼마나 같은 지를 판단하는 지표입니다.
정확도는 모델 예측 성능을 직관적으로 나타내주지만, 이진 분류의 경우 데이터의 구성에 따라 ML 모델의 성능을 왜곡할 수 있습니다.
예를 들어, MNIST 데이터셋을 7인지 아닌지 예측하는 이진 분류 문제로 만든다고 가정합니다.
다음은 어떤 데이터가 들어와도 "7이 아니다."라는 예측을 해주는 모델을 만든 뒤 MNIST데이터셋에 대한 모델 정확도를 나타낸 것입니다.
import numpy as np
import pandas as pd
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.base import BaseEstimator# 들어온 데이터와는 상관없이 무조건 False라고 예측하는 모델
class MyFakeClassifier(BaseEstimator):
def fit(self, X, y):
pass
def predict(self, X):
return np.zeros((X.shape[0], 1), dtype=bool)mnist_data = load_digits()
features = mnist_data.data
targets = mnist_data.target
# 이진 분류 데이터셋으로 바꾸기(7이냐 아니냐)
targets = (targets == 7)
X_train, X_test, y_train, y_test = train_test_split(features, targets, test_size=0.2, stratify=targets)
custom_clf = MyFakeClassifier()
custom_clf.fit(X_train, y_train)
pred = custom_clf.predict(X_test)
score = accuracy_score(y_test, pred)
print('이진 분류에 대한 정확도: {0:.4f}'.format(score))
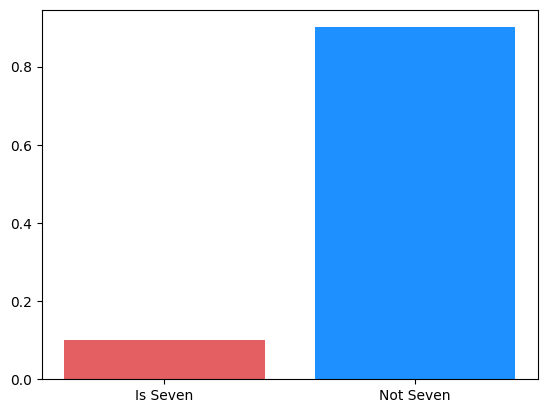
이렇게 단순한 모델 예측 성능이 90%가 나왔습니다.
이처럼 정확도는 데이터가 불균형한 레이블(Imbalanced Label)을 가질 경우, 적합한 평가 지표가 아닙니다.
아래는 이진 분류 MNIST 데이터의 불균형도를 나타낸 그래프입니다.
1️⃣ Confusion Matrix(오차 행렬)
오차 행렬은 이진 분류의 예측 오류가 얼마인지와 더불어 어떠한 유형의 예측 오류가 발생하고 있는지를 함께 나타내는 지표 입니다.
오차 행렬은 다음과 같이 4분면 행렬로 나타낼 수 있습니다.
앞에 TN인 경우 Negative로 예측을 잘 했다는 의미이며, TP는 Positive로 예측을 잘 했다는 의미입니다.
오차 행렬을 MNIST 이진 분류에 적용하면 다음과 같이 나옵니다.
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, pred)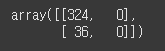
TN은 324로 Negative 값은 다 맞췄지만, FN은 36으로 실제가 Positive인 값은 하나도 맞추지 못했음을 알 수 있습니다.
즉, 모델이 Positive 예측을 전혀 수행하지 않았음을 알 수 있습니다.
2️⃣ Precision/Recall(정밀도/재현율)
정밀도와 재현율은 Positive 데이터 세트의 예측 성능에 좀 더 초점을 맞춘 평가 지표입니다.
MNIST 이진 분류에서 TP는 0이기 때문에 재현율과 정밀도 모두 0입니다.
정밀도와 재현율의 식은 다음과 같습니다.

정밀도는 Positive라고 예측한 값에 대해, 재현율은 실제로 Positive인 값에 대한 TP의 비율입니다.
즉, 정밀도는 모델이 Positive라고 잘못 예측한 경우를 줄이기 위한 평가 지표라고 할 수 있고, 재현율은 실제 Positive인 값에 대해 잘못 예측한 경우를 줄이기 위한 평가 지표라고 할 수 있습니다.
정밀도는 양성으로 잘못 예측하면 피해가 큰 경우에 사용됩니다.(ex 스팸 메일)
재현율은 실제로 양성인데 음성으로 잘못 예측하면 피해가 큰 경우에 사용됩니다.(ex 암 진단)
다음은 MNIST 이진 분류에 모델의 정밀도와 재현율을 확인합니다.
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score
# classification evaluation
def clf_eval(y_test, pred):
print('### CONFUSION_MATRIX ###')
print(confusion_matrix(y_test, pred))
print()
print('### ACCURACY ###')
print(accuracy_score(y_test, pred))
print()
print('### PRECISION ###')
print(precision_score(y_test, pred))
print()
print('### RECALL ###')
print(recall_score(y_test, pred))from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(random_state=42)
lr_clf.fit(X_train, y_train)
pred = lr_clf.predict(X_test)
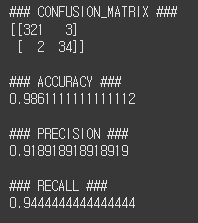
clf_eval(y_test, pred)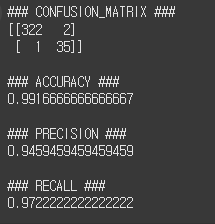
보통은 재현율이 정밀도보다 많이 쓰입니다.
📚 정밀도/재현율 트레이드오프
분류하려는 업무의 특성상 정밀도 또는 재현율이 강조되어야 하는 경우가 있습니다.
이런 경우 결정 임계값(Threshold)을 조정해 정밀도 또는 재현율을 높일 수 있습니다.
하지만, 정밀도와 재현율은 상호 보완적인 평가 지표이므로 한 쪽을 강제로 높이면 다른 쪽은 떨어지기 쉽습니다. 이를 정밀도/재현율 트레이드오프(Trade-off)라고 합니다.
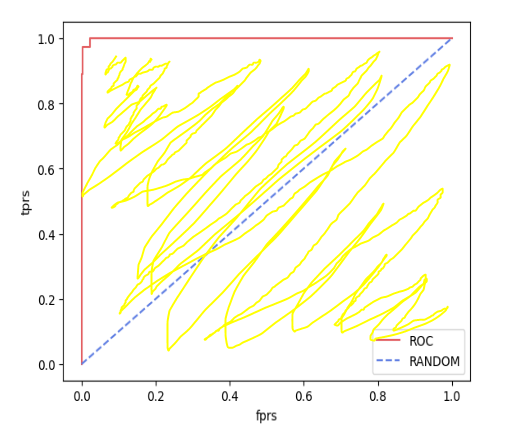
재현율과 정밀도 식을 곰곰히 생각해본 후 아래 그림을 보면 이해가 쉬울 것입니다.
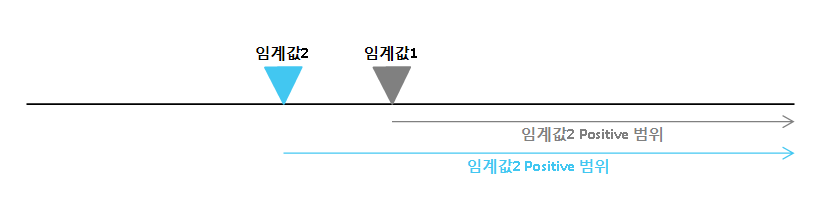
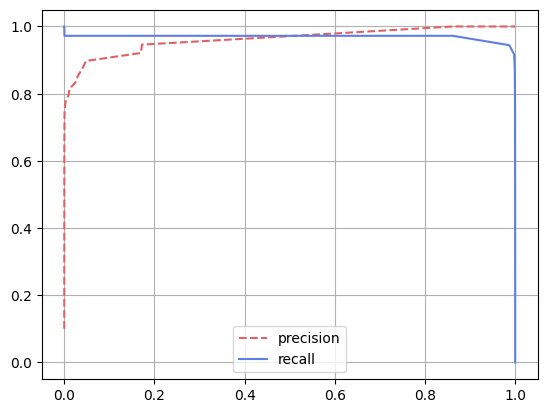
다시말해, 임계값이 낮아질 수록 모델은 Positive로 예측할 확률이 높아져 재현율은 높아지지만 그만큼 Positive로 잘못 예측할 확률이 높아지므로 정밀도는 떨어지기 쉽습니다.
이를 그래프로 나타내면 다음과 같습니다.(MNIST 이진 분류)
3️⃣ F1 Score
F1 Score는 정밀도와 재현율을 결합한 지표입니다.
F1 Score는 정밀도와 재현율이 어느 한 쪽으로 치우치지 않는 수치를 나타낼 때 상대적으로 높은 값을 가집니다.
공식은 다음과 같습니다.
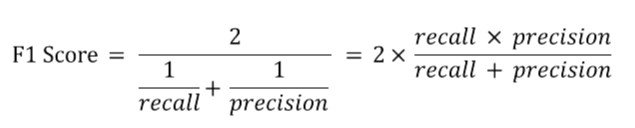
앞서, MNIST 모델에 적용해보면 다음과 같습니다.
from sklearn.metrics import f1_score
print(f1_score(y_test, pred))
from sklearn.preprocessing import Binarizer
def get_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
print('confusion matrix')
print(confusion)
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f}, F1 Score: {3:.4f}'.format(accuracy, precision, recall, f1))
def get_clf_eval_with_bin(y_test, thresholds, pred_proba):
for thr in thresholds:
binarizer = Binarizer(threshold=thr)
pred = binarizer.fit_transform(pred_proba)
print('threshold: {}'.format(thr))
get_clf_eval(y_test, pred)
thresholds = [0, 0.2, 0.4, 0.6, 0.8, 0.9]
pred_proba = lr_clf.predict_proba(X_test)[:, 1].reshape(-1, 1)
get_clf_eval_with_bin(y_test, thresholds, pred_proba)
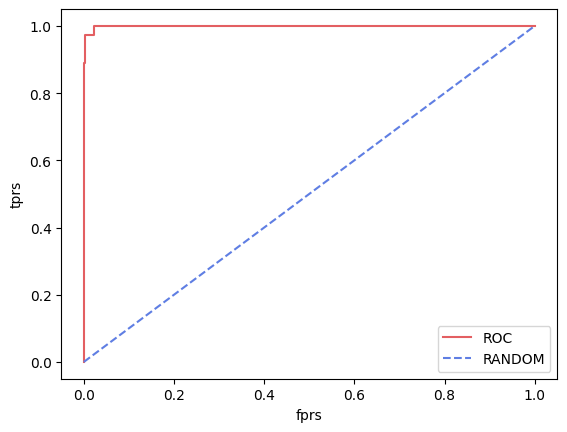
4️⃣ ROC 곡선과 AUC
ROC 곡선은 FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)이 어떻게 변하는지 나타내는 곡선입니다.
FPR을 X축으로 TPR을 Y축으로 잡으면 됩니다.
TPR과 FPR은 공식은 다음과 같으며, TPR은 재현율과 같습니다.(민감도라고도 불립니다.)

TPR은 모델이 Positive라고 제대로 예측한 비율을, FPR은 모델이 실제 Negative를 Positive라고 잘못 예측한 비율을 나타냅니다.
ROC 곡선은 FPR이 떨어질 때, TPR이 최대한 안 떨어지는 것을 목표로 합니다.
(쉽게말해, FPR은 오류를 나타내고 TPR은 정확도를 나타낸다고 보시면 됩니다. 쉽게 보자면 그렇다는 겁니다.)
아래는 MNIST 이진 분류에서 roc_curve를 적용한 값입니다.
from sklearn.metrics import roc_curve
pred_proba = lr_clf.predict_proba(X_test)[:, 1]
fprs, tprs, thresholds = roc_curve(y_test, pred_proba)
print(thresholds)
print(fprs)
print(tprs)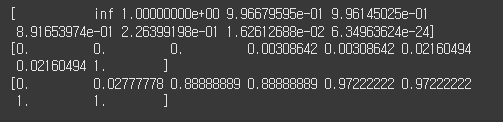
결정 임계값이 작아질 수록 TPR이 높아지지만, FPR도 같이 높아집니다.
AUC는 ROC 곡선과 FPRS 축이 이루는 넓이 입니다.
보통 1에 가까울수록 좋은 수치라고 말합니다.
(MNIST 이진 분류의 경우 0.999로 굉장히 좋은 수치가 나오긴 했습니다.)
from sklearn.metrics import roc_auc_score
print(round(roc_auc_score(y_test, pred_proba), 3))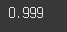
여기서 ROC곡선과 AUC는 아래와 같이 나타납니다.