이 머신러닝 시리즈는 내 인공지능의 Base가 되어준 『파이썬 머신러닝 완벽 가이드 - 권철민』을 다시 곱씹어 읽어보며 작성하려고 한다.
이외에도 필요하거나 따로 공부하면서 알아낸 정보 출처는 reference에 넣어두겠다.
모든 환경설정은 google Colab pro에서 진행되지만 pro가 아니어도 된다.
혹시나 틀린 개념이 있거나 궁금한 점이 있으시면 알려주시면 감사하겠습니다.
Sklearn(Scikit-learn)

사이킷런(sklearn)은 파이썬 머신러닝 라이브러리 중 가장 많이 사용되는 라이브러리다.
파이썬으로 머신러닝을 한다함은 sklearn을 이용한다는 말을 의미한다고 보면 될 정도다.
최근에는 다른 딥러닝 전용 프레임워크(pytorch, tensorflow 등)가 나와 사용량이 줄어들지만 머신러닝 대회에 참여하면 아직 많은 상위 랭커들은 Sklearn을 애용한다.(traditional ML기준)
Sklearn은 많은 데이터 분석가들로 인해 검증된 라이브러리이며, 파이썬 기반의 머신러닝 라이브러리라는 말이 가장 잘 어울리는 라이브러리다.
쉬운 API기반으로 대부분의 주요 로직을 구현할 수 있다는 점이 많은 데이터 분석가가 Sklearn을 애용하는 이유다.
Coding📄
1. sklearn.datasets
sklearn.datasets 모듈은 sklearn 자체적으로 제공하는 연습용 데이터셋이다. 자체 데이터셋이므로 따로 데이터를 다운로드 할 필요가 없다.
from sklearn.datasets import load_iris
# sklearn.datasets 모듈은 다운로드가 필요없이 sklearn 자체적으로 제공하는 연습용 datasets임.
# load_iris는 아이리스(iris) 꽃 종류('setosa', 'versicolor', 'virginica')를 분류하는 Multi Classification Dataset임.
# feature column은 총 4개 : sepal length(꽃받침 길이), sepal width(꽃받침 넓이), petal length(꽃잎 길이), petal width(꽃잎 넓이)
iris_data = load_iris()
type(iris_data)
sklearn.datasets의 load_iris()를 로드한 뒤 객체를 살펴보면 "Bunch"라는 타입으로 나오는데 이는 파이썬의 딕셔너리라고 생각하면 된다.
(키와 값을 가진 데이터 구조)
# feature 값
features = iris_data.data
# column name
feature_name = iris_data.feature_names
# target 값
targets = iris_data.target
# target name
target_name = iris_data.target_names
features.shape, len(feature_name), targets.shape, len(target_name)
load_iris() 객체 iris_data는 속성(attribute)으로 feature 값을 가진 data, feature의 이름(column)을 가진 feature_names, target 값을 가진 target, target의 이름을 가진 target_names가 있다.
이외에도 data에 대한 설명을 가진 DESCR도 있다.
import numpy as np
import pandas as pd
# Pandas의 DataFrame으로 시각화(?)
iris_df = pd.DataFrame(features, columns=feature_name)
iris_df['target'] = targets
iris_df['target_name'] = target_name[targets]
iris_df.head()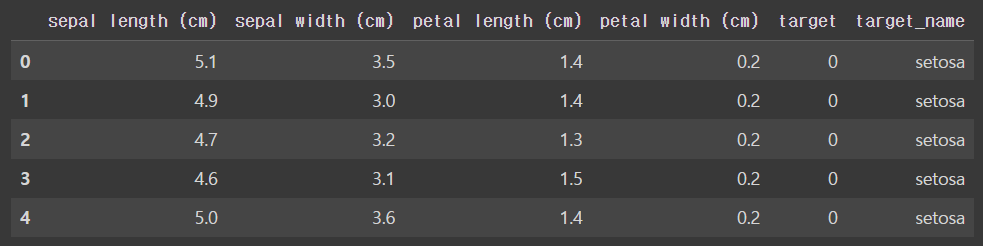
DataFrame으로 좀 더 직관적으로 iris_data가 어떻게 구성되어있는지 확인해봤다.
총 150개의 row와 4개의 column으로 구성되어있으며 column 이름은 sepal length, sepal width, petal length, petal width이다.
target값은 0~2까지 총 3개의 종류로 구성된 Multi Classification분류 데이터세트이다.
0부터 2까지 각각 setosa, versicolor, virginica라는 이름을 가지고 있다.
2. sklearn.model_selection
sklearn의 model_selection 모듈은 교차검증에 필요한 train dataset과 valid dataset을 나누는 API와 최적 파라미터 추출 등의 API를 제공한다.
주어진 iris 데이터 세트를 train_test_split()을 이용해 train 데이터세트와 test 데이터세트로 분리해 보겠다.
from sklearn.model_selection import train_test_split
# 전체 데이터세트 중 20퍼센트를 test dataset로 만듬.
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2)
print(X_train.shape, X_test.shape)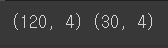
train_test_split API는 sklearn에서 많이 쓰이는 함수다.
반환값으로는 '학습 피처, 테스트(검증) 피처, 학습 타겟, 테스트(검증) 타겟'이다.
만들어진 y_train 데이터의 비율을 한번 보겠다.
# stratify 적용하지 않았을 때 y_train value_counts().
test_df = pd.Series(y_train)
test_df.value_counts()
학습 타겟의 비율은 0-2까지 차례대로 38, 46, 38개로 구성되어있다.
train_test_split()함수는 이렇게 불균형한 데이터가 만들어지지 않도록 하기 위해 stratify인자를 설정할 수 있다.
다음은 stratify인자를 적용한 코드다.
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, stratify=iris_data.target)
# stratify 적용하였을 때 y_train value_counts().
test_df = pd.Series(y_train)
test_df.value_counts()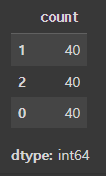
target데이터에 대해 균등하게 train데이터세트가 분리된 걸 볼 수 있다.
3. sklearn.preprocessing
인공지능 대회에 참여해보고 모델의 성능을 높이기 위해서는 사실 모델의 알고리즘을 건드릴 일은 거의 없다. 대부분의 작업은 EDA와 전처리(preprocessing)에서 이루어진다.
sklearn에서는 preprocessing 모듈을 이용해 StandardScaler, MinMaxScaler등 preprocessing API를 제공한다.
sklearn에서는 일괄성을 위해 preprocessing 객체를 fit과 transform메서드를 이용해 쉽게 preprocessing할 수 있게 해준다.
StandardScaler는 데이터를 평균 0, 분산 1로 조절해주는 역할을 하며 MinMaxScaler는 데이터를 0과 1 사이의 값으로 전처리 해주는 역할을 한다.
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
# standard scaler 객체.
std_scaler = StandardScaler()
# standard scaler 적용.
std_scaler.fit(X_train)
X_train_std = std_scaler.transform(X_train)
# minmax scaler 객체.
mM_scaler = MinMaxScaler()
# minmax scaler 적용.
mM_scaler.fit(X_train)
X_train_mM = mM_scaler.transform(X_train)우선 StandardScaler, MinMaxScaler 모듈을 불러온 뒤 preprocess해준 값을 구한다.
# DataFrame으로 시각화.
org_feature_names = [column for column in iris_data.feature_names]
std_feature_names = ['std'+'_'+column for column in iris_data.feature_names]
mM_feature_names = ['minmax'+'_'+column for column in iris_data.feature_names]
scaler_df = pd.DataFrame(X_train, columns=org_feature_names)
scaler_df[std_feature_names] = X_train_std
scaler_df[mM_feature_names] = X_train_mM
scaler_df.head()
이렇게 만들어진 데이터를 DataFrame으로 시각화해봤다.
여기서 중요한 점은 preprocess API 객체를 작동시킬 때 fit과 transform을 이용해 동작시켰다는 것이다.
이는 다음에 설명할 estimator와 메커니즘이 거의 일치하며, scikit-learn의 특징이자 장점이다.
4. Estimator
Data를 간단하게 preprocessing하고 split했으니 모델을 학습 시켜봐야한다.
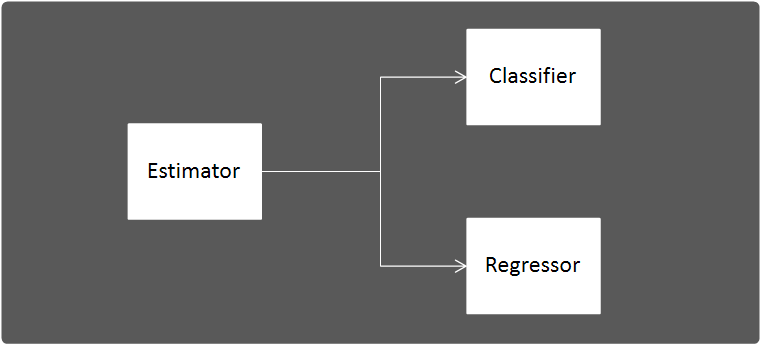
Sklearn에서는 분류를 위한 모델을 Classifier, 회귀를 위한 모델을 Regressor라고 한다.
Sklearn에서는 이런 모델(Classifier와 Regressor)을 통틀어 Estimator라고 한다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from lightgbm import LGBMClassifier
from xgboost import XGBClassifier
# 데이터 로드
iris_data = load_iris()
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target)우선 간단하게 모델을 학습시키기 위해 위처럼 Data를 간단하게 분리해줬다.
# estimator 객체 생성.
dt_clf = DecisionTreeClassifier()
lr_clf = LogisticRegression()
lgb_clf = LGBMClassifier()
xgb_clf = XGBClassifier()
# 학습
dt_clf.fit(X_train, y_train)
lr_clf.fit(X_train, y_train)
lgb_clf.fit(X_train, y_train)
xgb_clf.fit(X_train, y_train)
# 예측
dt_preds = dt_clf.predict(X_test)
lr_preds = lr_clf.predict(X_test)
lgb_preds = lgb_clf.predict(X_test)
xgb_preds = xgb_clf.predict(X_test)그 후 위처럼 모델 객체를 받아준 후 fit, predict 메서드를 통해 모델을 학습 및 예측하면 된다.
Sklearn의 모든 estimator는 fit과 predict를 이용해 모델이 학습하고 예측할 수 있게 할 수 있다.
5. sklearn.metrics
이렇게 모델을 학습시키고 학습된 모델로 예측하면 그 예측이 얼마나 정확한지 확인해야한다.
Sklearn은 metrics API를 이용해 이를 가능하게 한다.
from sklearn.metrics import accuracy_score
# 위에서 예측한 결과 값을 기반으로 성능 평가.
dt_score = accuracy_score(y_test, dt_preds)
lr_score = accuracy_score(y_test, lr_preds)
lgb_score = accuracy_score(y_test, lgb_preds)
xgb_score = accuracy_score(y_test, xgb_preds)
print('DecisionTreeClassifier accuracy_score:')
print(np.round(dt_score, 4))
print()
print('LogisticRegression accuracy_score:')
print(np.round(lr_score, 4))
print()
print('LGBMClassifier accuracy_score:')
print(np.round(lgb_score, 4))
print()
print('XGBClassifier accuracy_score:')
print(np.round(xgb_score, 4))
print()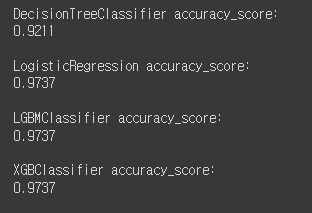
여기서는 가장 기본적인 accuracy_score()를 이용했다.
정확도를 측정하는 성능평가지표다.
Sklearn의 대부분 성능평가지표는 인자로 실제 값, 예측 값이 들어간다.
이외의 API
마지막으로 내가 인공지능을 하면서 이외에도 자주 사용하는 API에 대해 나열하겠다.
- from sklearn.model_selection import KFold
- from sklearn.model_selection import StratifiedKFold
- from sklearn.model_selection import GridSearchCV
- from sklearn.model_selection import cross_val_score
- from sklearn.preprocessing import LabelEncoder
- from sklearn.preprocessing import OneHotEncoder
- from sklearn.metrics import precision_score
- from sklearn.metrics import recall_score
- from sklearn.metrics import f1_score
- from sklearn.metrics import confusion_matrix
reference
