오늘은 로지스틱 회귀와 회귀 트리에 대해 공부하려고 합니다.
로지스틱 회귀는 텍스트 분석에서도 사용되는 알고리즘이며, 나중에 딥러닝을 공부할 때 필요한 개념중 하나인 시그모이드 함수를 내포하고 있다는 점에서 중요합니다.
📚 Logistic Regression (로지스틱 회귀)
로지스틱 회귀는 선형 회귀 방식을 분류에 적용한 알고리즘입니다.
보통 이진분류에 사용됩니다.
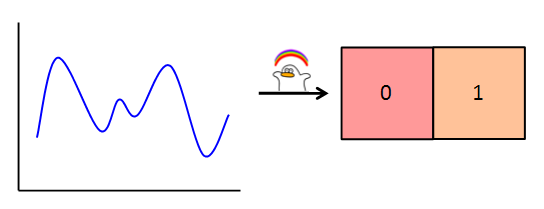
로지스틱 회귀가 분류에 사용이 가능한 이유는 Sigmoid(시그모이드) 함수를 사용했기 때문입니다.
기본 방식은 선형 회귀와 똑같이 예측 값을 구하지만, 최종적인 반환 값은 시그모이드를 취합니다.
이렇게 얻어진 최종 반환 값은 확률로써 처리됩니다.
아래와 같이 말이죠.
- 0.5 <= pred: 1
- 0.5 > pred: 0
또한, 로지스틱 회귀는 희귀 데이터에 대해 성능이 상대적으로 높을 수 있다는 장점이 있습니다.
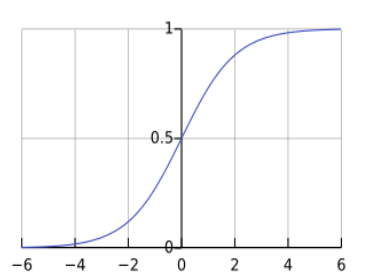
✅ Sigmoid Function(시그모이드 함수)
시그모이드 함수 식은 다음과 같습니다.

즉, x값이 무한정 커져도 1을 넘지 못하며, 무한정 작아져도 0 아래로 내려갈 수 없습니다.
이는 나올 수 있는 값에 제한이 없던 회귀에 시그모이드를 적용함으로써 반환값 제어가 가능해졌음을 의미합니다.
이런 특성 때문에 시그모이드 함수는 다음과 같은 형태로 나타납니다.
우리가 선형 회귀 모델을 다음과 같은 식으로 정의한다고 가정하면,
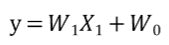
이를 시그모이드 함수에 대입하면 다음과 같아집니다.
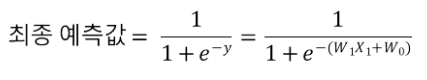
최종적으로 0과 1사이의 값을 모델이 반환하게 되면서 그로 인해 파생된 비용 함수에 경사하강법을 적용하게 됩니다.
✅ Cost Function(비용 함수)
이렇게 로지스틱 회귀가 어떻게 예측하는지 알았습니다.
하지만, 아직 한 가지 질문이 남아있습니다.
어떻게 비용 함수가 구성되며, 어떻게 비용 함수를 최소로 하는 회귀계수를 찾을 수 있을까?

우선, 하나의 데이터에 대해 로지스틱 회귀의 비용함수는 다음처럼 표현할 수 있습니다.
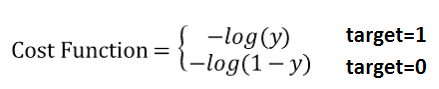
이는 target이 1인 경우 낮은 확률을 추정하면 높은 페널티가 부과되며, target이 0인 경우 높은 확률을 추정하면 높은 페널티가 부과됨을 의미합니다.
이를 로지스틱 회귀의 전체 데이터에 대한 비용함수로 표현하면 다음과 같아집니다.
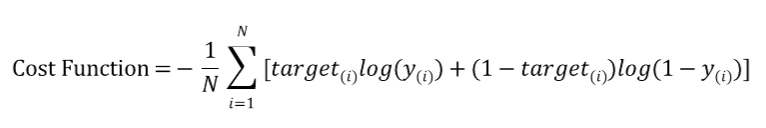
이 식을 상황에 따라 해석하면 다음과 같습니다.
- target(i)=0: 두 번째 항만 의미가 있어짐.
- target(i)=1: 첫 번째 항만 의미가 있어짐.
이제 이렇게 만들어진 비용 함수에 경사 하강법을 적용하면 최솟값을 찾을 수 있습니다.
(이 비용 함수는 볼록 함수이므로 경사 하강법이 전역 최솟값을 찾는 것을 보장합니다.)
✅ Logistic Regression Code
sklearn에서 LogisticRegression 클래스를 제공합니다.
우리는 다음과 같이 코드를 짤 수 있습니다.
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
iris_data = load_iris()
features = iris_data.data
targets = iris_data.target
lg_lr = LogisticRegression(max_iter=1000)
scores = cross_val_score(lg_lr, features, targets, scoring='accuracy', cv=5)
print(scores)
print(np.mean(scores))
sklearn의 로지스틱 회귀의 주요 파라미터는 다음과 같습니다.
- penalty: 규제의 종류. {‘l1’, ‘l2’, ‘elasticnet’, None}, default=’l2’
- C: 규제의 정도. float, default=1.0(값이 작아질수록 강도가 세짐.)
- solver: 최적화 알고리즘. {‘lbfgs’, ‘liblinear’, ‘newton-cg’, ‘newton-cholesky’, ‘sag’, ‘saga’}, default=’lbfgs’
- max_iter: 최대 iteration 횟수. int, default=100
📚 Regression Tree (회귀 트리)
선현 회귀는 회귀계수의 관계를 모두 선형으로 가정하는 방식입니다.
회귀 트리는 회귀를 위한 트리를 생성하고, 이를 기반으로 회귀 예측을 하는 것입니다.
여기서 말하는 트리는 분류에서 다룬 트리와 크게 다르지 않습니다.
다만, 리프 노드에서 최종 결과 값을 평균으로 다룬다는 점에 차이가 있습니다.
예시를 통해 살펴봅시다.
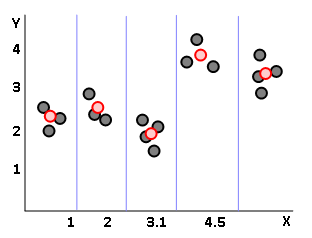
아래와 같은 데이터가 있습니다.(X라는 독립변수에 따라 Y라는 종속변수가 정해짐.)
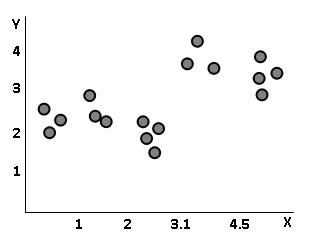
이런 데이터는 직관적으로 다음과 같이 나눌 수 있습니다.
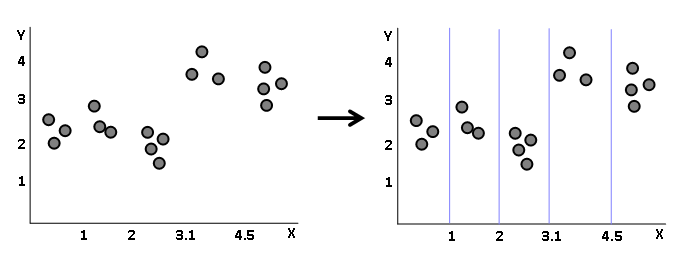
그렇다면 이를 트리로 나타내면 어떨까요?
아래처럼 우리가 분류에서 사용한 트리처럼 나오게 됩니다.
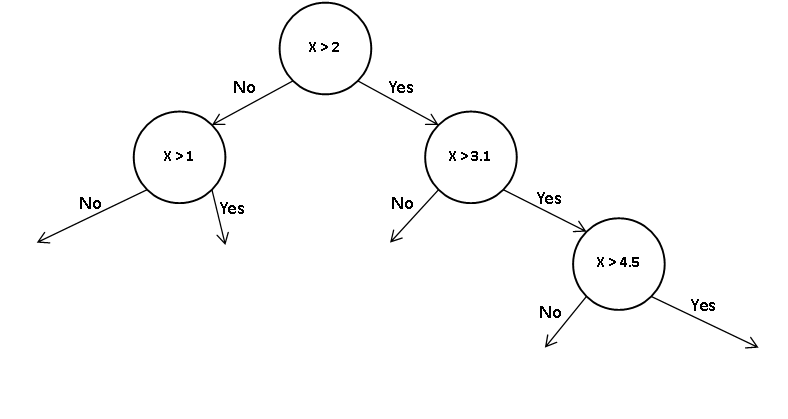
기존 분류에서는 이렇게 서브트리를 거쳐서 나온 리프 노드에서 많은 클래스 값으로 예측했습니다.
회귀 트리에서는 리프 노드 값들의 평균을 반환 합니다.
✅ 다양한 회귀 트리 알고리즘
분류에서 트리 기반의 알고리즘이 뛰어난 성능을 얻어낼 수 있습니다.
sklearn에서는 회귀에서도 트리 기반의 알고리즘을 사용할 수 있도록 제공합니다.
이것이 가능한 이유는 트리 생성이 CART(Classification And Regression Trees) 알고리즘에 기반하기 때문입니다.
대표적으로 DecisionTree, RandomForest, GBM, XGBoost, LightGBM이 있습니다.
아래는 캘리포니아 집 가격을 예측하는 회귀 문제를 통해 DecisionTreeRegressor, RandomForestRegressor, GradientBoostingRegressor, XGBRegressor, LGBMRegressor 모델 성능을 파악한 코드 입니다.
from sklearn.datasets import fetch_california_housing
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.model_selection import cross_val_score
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
house_data = fetch_california_housing()
features = house_data.data
targets = house_data.target
dt_reg = DecisionTreeRegressor()
rf_reg = RandomForestRegressor()
gb_reg = GradientBoostingRegressor()
xgb_reg = XGBRegressor()
lgb_reg = LGBMRegressor()
models = [dt_reg, rf_reg, gb_reg, xgb_reg, lgb_reg]
for model in models:
scores = cross_val_score(model, features, targets, scoring='neg_mean_squared_error', cv=5)
rmse = np.mean(np.sqrt(-1 * scores))
print(model.__class__.__name__)
print(round(rmse, 4))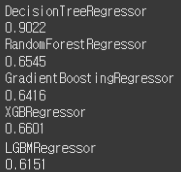
당연한 얘기겠지만, 이를 통해 어떤 모델이 성능이 더 좋은지는 알 수 없습니다.
일반적으로, 저는 부스팅 계열을 대회에서 많이 애용하긴 합니다.😊
📜 Reference
[개정판] 파이썬 머신러닝 완벽 가이드
시그모이드 함수
『핸즈온 머신러닝』- 오렐리앙 제롱
LogisticRegression Sklearn 공식문서
