
기존에 Classification(분류)에 대한 내용을 공부하고, 이번 장에서는 Regression(회귀)에 대해 공부하려고 합니다.
회귀 자체도 중요하지만, Deep Learning(딥러닝)에 대해서 더 자세히 공부하기 원하는 저로써는 회귀에 쓰이는 경사 하강법을 놓칠 수 없었습니다. 딥러닝도 이 원리를 사용하기 때문입니다.
따라서 이번 장에서는 회귀에 대한 소개, 원리, 종류에 대해 소개하며 경사 하강법에 대해 공부하려고 합니다.
마지막에는 Stochastic Gradient Descent(확률적 경사 하강법)에 대해서 간단한 정의 정도만 다룹니다.😊
📚 Regression(회귀)
회귀는 현대 통계학을 떠받치고 있는 주요 기둥 중 하나입니다.
회귀 분석은 유전적 특성을 연구하던 영국의 통계학자 갈톤(Galton)이 수행한 연구에서 유래했다는 것이 일반론이라고 합니다.
통계학에서 회귀란, 여러 개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링하는 기법을 통칭합니다.
지도학습의 두 축인 분류와 회귀는 예측값이 이산형 클래스인지, 연속형 숫자값인지 차이가 있습니다.(분류는 이산형, 회귀는 연속형)
예를들어, 주택 가격을 예측하는 모델을 만든다고 가정합니다.
이때, 주택 가격에 영향을 미치는 요인은 다양하게 있을 것입니다.(땅 크기, 방 개수 ...)
우리는 이 회귀 모델을 다음과 같이 나타낼 수 있을 것입니다.
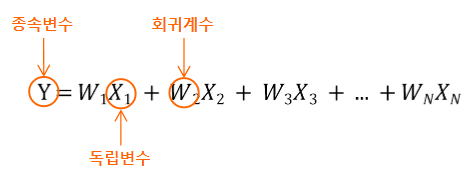
즉, 주택 가격이라는 종속변수는 땅 크기, 방 개수와 같은 독립변수에 의해 결정됩니다.
그리고 독립변수에 영향을 미치는 값을 회귀계수라고 부릅니다.
머신러닝적으로 정리하자면 다음과 같습니다.
- 종속변수: target 값
- 독립변수: feature 값
- 회귀계수: feature에 부여하는 가중치
머신러닝 회귀에서 모델을 학습한다는 의미는 최적의 회귀계수를 찾는다는 의미입니다.
단순 선형 회귀를 통해 회귀를 더 이해해 봅시다.
단순 선형 회귀는 독립변수도 하나, 종속변수도 하나인 선형 회귀입니다.
예를들어, 주택 가격을 예측하는 모델을 만들 때 주택 가격이 땅 크기에 따라 달라진다고 하면 이를 단순 선형 회귀로 표현하면 다음과 같습니다.
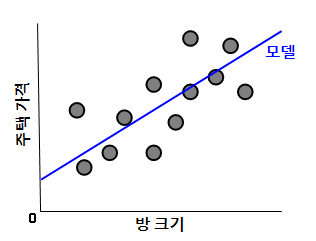
이때, 모델의 수학적 정의는 다음과 같습니다.
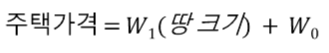
이때, 회귀계수 W1와 W0를 찾는 것이 회귀입니다.
✅ 회귀 종류
회귀는 크게 4가지 종류로 나눌 수 있습니다.
회귀는 회귀계수에 따라 선형 / 비선형 회귀, 독립변수의 개수에 따라 단일 / 다중 회귀로 구분됩니다.
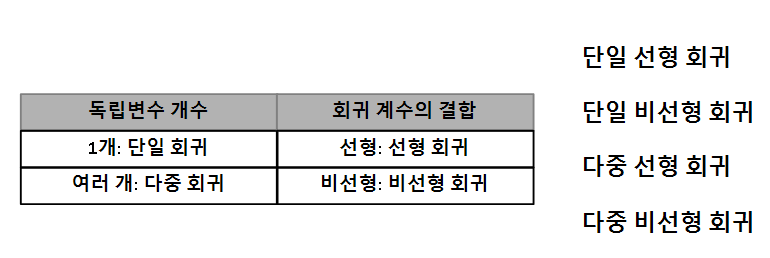
여러 회귀 중에서 선형 회귀가 가장 많이 사용됩니다.
선형 회귀는 또다시 Regularization(규제) 방법에 따라 아래와 같이 유형이 나뉩니다.
- 일반 선형 회귀: 예측값과 실제값의 RSS(Residual Sum of Squares)를 최소화할 수 있도록 회귀 계수를 최적화하며, 규제를 적용하지 않은 모델
- Ridge(릿지): 일반 선형 회귀에 L2규제를 적용한 모델
- Lasso(라쏘): 일반 선형 회귀에 L1규제를 적용한 모델
- ElasticNet(엘라스틱넷): L2, L1규제를 함께 결합한 모델(주로 피처가 많은 데이터 세트에서 사용)
- Logistic Regression(로지스틱 회귀): 회귀지만, 시그모이드 함수를 이용해 일반적으로 분류 알고리즘에 사용되는 모델
✅ Gradient Descent(경사 하강법)
앞서 회귀에서 모델을 학습한다는 의미는 최적의 회귀계수를 찾는 것이라고 말했습니다.
그렇다면 다음과 같은 질문이 나올 것입니다.
최적의 회귀계수를 어떻게 찾으라는 것인가?
회귀계수가 적으면 고차원 방정식으로 풀 수 있지만, 회귀계수가 많아지면(피처 수가 많아지면) 고차 방정식으로 풀기 힘들어집니다.

이런 상황 속에서 경사 하강법은 최적의 회귀계수를 찾는 방법을 제공합니다.
경사 하강법이란, '점진적으로' 반복적인 계산을 통해 회귀계수 값을 업데이트하면서 오류 값이 최소가 되는 회귀계수를 구하는 방식입니다.
여기서 '점진적으로'라는 의미는 미분을 의미합니다.
다시말해, 경사 하강법이란 오류 값을 나타내는 함수를 편미분해서 점진적으로 최적의 회귀계수를 구하는 것입니다.
땅 크기 회귀계수에 따른 주택 가격이 어떤 관계를 가질 때, 경사 하강법을 표현하면 다음과 같습니다.
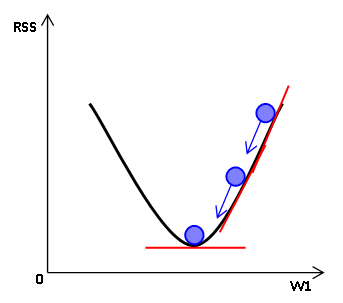
이때, RSS(Residual Sum of Square)는 오류 값의 제곱을 구해서 더하는 방식을 뜻합니다.
이를 우리는 비용 함수(Cost Function) 또는 손실 함수(Loss Function)이라고 합니다.
모델을 f(x)=w1X1 + w0라고 가정하고 RSS를 구하면 다음과 같습니다.
(여기서 RSS는 편의상 R(w0, w1)이라고 하겠습니다.)
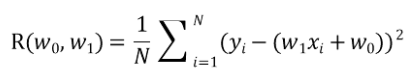
R(w0, w1)을 w0와 w1에 대해 각각 편미분을 하면 다음과 같습니다.
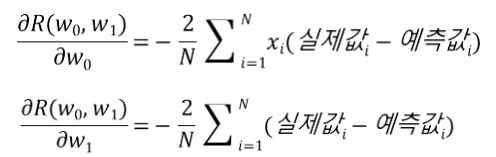
이렇게 편미분한 결과 값을 Update Value라고 부른다면, 우리는 기존 회귀계수 - Update Value를 해줘야 합니다. -1을 곱해주는 이유는 아래 그림을 보시면 이해가 될 것 같습니다.
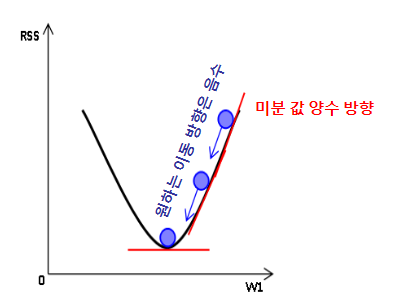
이렇게 Update Value를 바로 적용하면 값이 너무 클 수 있기 때문에 보정 계수를 곲하는데,
이를 'learning rate(학습률)'라고 합니다.
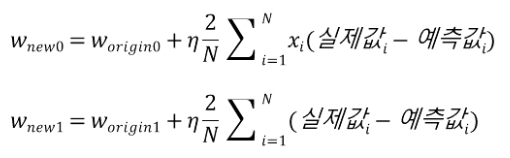
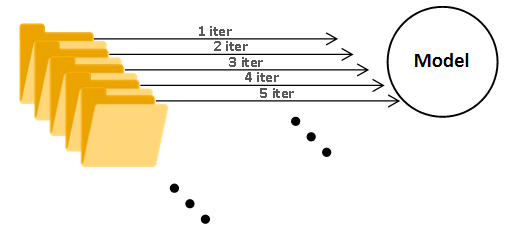
이렇게 한 과정을 우리는 '한 iteration'이라고 합니다.
iteration을 많이 돌릴수록 일반적으로 최적의 값을 찾아갈 수 있습니다.
✅ Stochastic Gradient Descent(확률적 경사 하강법)
앞에서 경사 하강법은 모든 데이터에 대해 적용하기 때문에 학습 시간이 오래 걸립니다.
그래서 대부분 실전에서는 확률적 경사 하강법을 이용합니다.
확률적 경사 하강법은 전체 입력 데이터로 값을 업데이트 하는 것이 아니라 일부 데이터만 이용해 값을 업데이트하기 때문에 일반적 경사 하강법에 비해 빠른 속도를 보장합니다.
"이렇게 일부 데이터로만 학습하면 성능이 심하게 감소하지 않나?"라는 의문이 들지만, 실제로 큰 예측상의 차이가 없다고 합니다.
따라서 큰 데이터를 처리할 경우에는 경사 하강법은 매우 시간이 오래 걸리므로 일반적으로 확률적 경사 하강법을 사용합니다.
📚 추가적인 내용
이번 장에서 경사 하강법에 대해 공부했습니다.
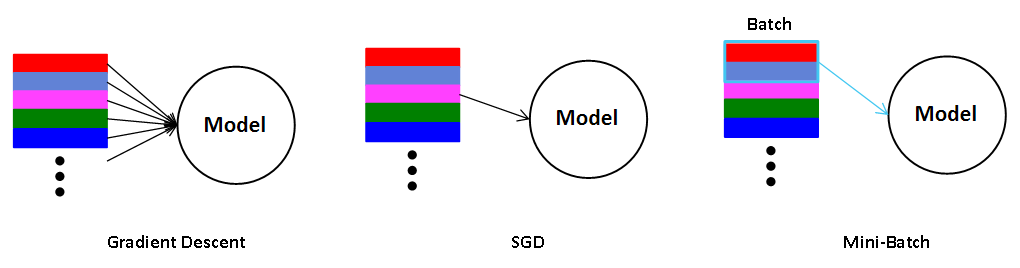
경사 하강법의 종류는 GD, SGD로 나누어 설명했습니다만, 좀 더 아카데미적으로 들어가면 경사 하강법에는 크게 GD, SGD, Mini-batch가 있습니다.
가장 일반적인 경사 하강법인 GD는 전체 데이터에 대해서 학습한다는 점으로써 완전히 개념이 똑같습니다.
하지만, 확률적 경사 하강법은 일부 데이터라기 보다는 단 하나의 데이터를 가지고 학습하는 것입니다.
물론, 일부 데이터의 집합에 단 하나의 데이터가 포함되긴 하지만, 면밀히 보자면 위에서 설명한 SGD는 Mini-Batch Gradient Descent입니다.
SGD는 모델이 Global Minimum까지 가는 동안 너무 요동친다는 단점 때문에 현재는 Mini-Batch Gradient Descent를 많이(사실상 전부) 사용합니다.
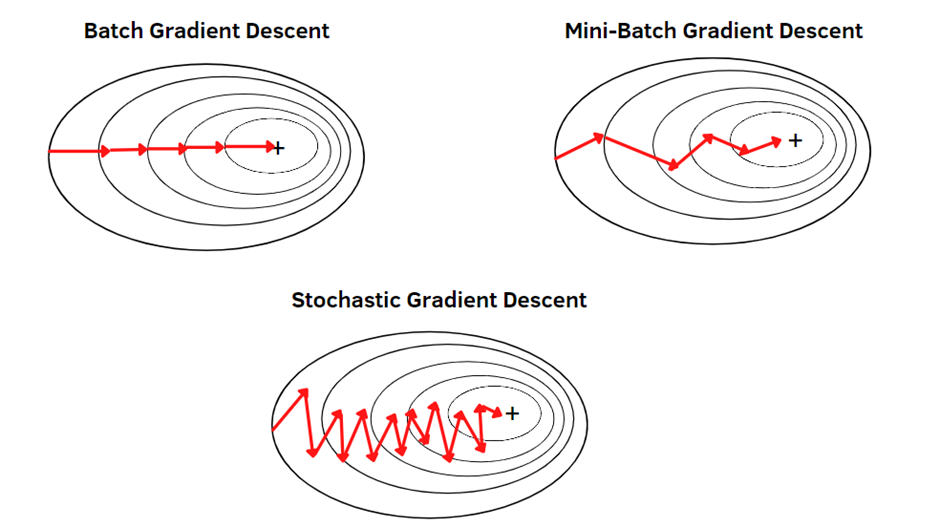
하지만, SGD와 Mini-Batch는 혼용되어 사용되는 것 같습니다.
이상으로 이번 장을 마치겠습니다. 감사합니다!
현대 머신러닝의 주요 이론을 다루는 만큼 설레는 시간이었습니다.😁
📜 Reference
