안녕하세요. 오늘은 Fast R-CNN 논문을 읽고 공부해봤습니다.
Fast R-CNN Paper
Abstract

이 논문은 convolutional network를 사용한 Object Detection에 관한 것입니다.
Fast R-CNN은 혁신적인 방법을 이용하여, 모델의 성능을 높이는 동시에 학습/ 테스트 속도도 빨라졌습니다.
Fast R-CNN은 R-CNN보다 9배 빠른 속도로 학습하였고, 213배 빠른 test-time을 보여주었습니다. 성능도 더 좋았습니다.(PASCAL VOC 2012)
SPPnet보다 3배 빠른 속도로 학습하였고, 10배 빠른 test-time을 보여주었습니다. 마찬가지로 성능도 더 좋았습니다.
1. Introduction

Image Classification과 비교해봤을 때, Object Detection은 해결해야 할 더 많은 문제가 있습니다. 따라서 이를 해결하기 위해 더 복잡한 방법을 구상해야 했습니다.
이런 복잡성때문에 지금까지의 모델들은 multi-stage pipeline을 구성하게 되었고, 이는 모델의 한계를 조성합니다.(slow and inelegant)
Object Detection이 localization에서 요구하는 두가지 주요 challenge가 있습니다.
- 수많은 Object Proposals이 수행되어야 합니다.
- 앞서 Proposal에서 나온 rough localization을 정제해야 합니다.
논문에서는 학습 과정을 간소화 시킵니다.
기존과는 다르게 single-stage training 알고리즘을 구축합니다.
Object Proposal과 rough localization을 정제하는 과정을 한번에 학습 시킨다는 의미입니다.
이렇게 나온 Fast R-CNN은 R-CNN, SPPnet과 비교했을 때, 더 뛰어난 성능과 속도를 보여줍니다.
Fast R-CNN은 PASCAL VOC 2012에서 top accuracy mAP 66%를 달성하며, 뛰어난 성능을 보여주었습니다.
✔ R-CNN and SPPnet
이 논문이 나오기 전, 좋은 성능을 낸 R-CNN이라는 모델이 있었습니다.
하지만, R-CNN은 다음과 같은 문제가 있었습니다.
Training is a multi-stage pipeline

R-CNN은 분류를 수행할 때, SVM 모델을 활용했습니다.
SVM은 softmax를 대신하여 Object Detector로 사용되었습니다. 또한, 3번 째 training stage에서 bounding box regression이 학습됩니다.
이는 다시 말해, convolutional layer, SVM, bounding box regression 으로 총 3단계의 학습이 진행된다는 의미입니다. 따라서 모델이 복잡해집니다.
Training is expensive in space and time

R-CNN은 SPPnet과 달리 region proposal된 영역에 대해 각각 합성곱 연산을 진행합니다.
이는 너무 많은 저장 공간이 필요함을 시사합니다.
Object detection is slow

테스트 시에 feature는 각 Object Proposal에 대해 추출됩니다.
이는 GPU에서 한 이미지를 Detection하는데 47초나 걸리게 합니다.(1/47fps)
다시 말해, Detection 속도가 너무 느립니다.
R-CNN은 region proposal마다 공유하는 computation 없이 연산을 진행하기 때문에 느립니다.
이후에 나온 SPPnet은 R-CNN의 no sharing computation 문제를 해결했습니다.
전체 이미지에 대해 Convolutional layer를 한 번만 거침으로써 이를 가능하게 했습니다.
SPPnet은 테스트 시간에서 R-CNN을 10-100배 가량 능가하는 모습을 보였습니다.
하지만, SPPnet도 문제가 있었습니다.
R-CNN과 마찬가지로 multi-stage pipeline 문제를 가지고 있었으며, feature가 여전히 디스크에 저장된다는 문제도 있었습니다.
또한, R-CNN과는 다르게 파인튜닝 시 Convolutional layer가 업데이트 되지 않습니다.
당연하게도, 이런 한계는 성능에 제한을 두었습니다.
✔ Contributions

논문에서는 R-CNN과 SPPnet의 단점을 보완하고, 성능을 올리는 새로운 알고리즘을 제시합니다.
이 모델의 이름은 Fast R-CNN으로 명명합니다.(학습과 테스트에서 빠른 속도를 보여줍니다.)
Fast R-CNN은 다음과 같은 장점이 있습니다.
-
R-CNN과 SPPnet에 비해 높은 mAP
-
multi task loss를 사용. single stage training
-
모든 layer의 가중치 업데이트 가능
-
feature caching을 위한 어떤 디스크도 필요하지 않음
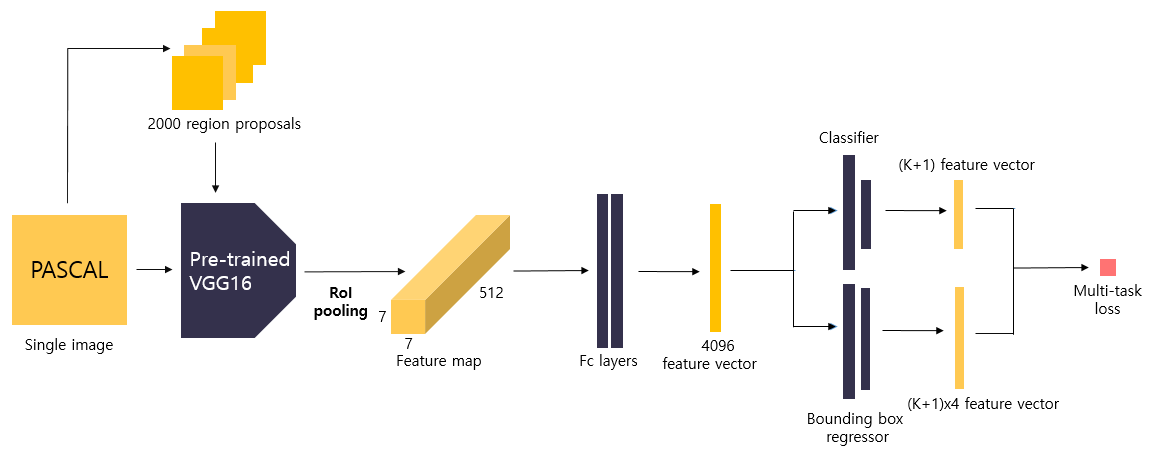
2. Fast R-CNN architecture and training

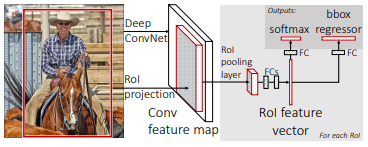
Fast R-CNN은 SPPnet과 비슷한 면이 많습니다.
Fast R-CNN의 작동 원리를 살펴보면 다음과 같습니다.
-
이미지가 들어오면, 하나의 이미지 전체를 Convolution layer에 넣는다.
-
Convolution layer에서 feature map을 뽑는다.
-
feature map에 ROI Pooling을 적용하여 region proposal 한다.
-
fully-connected layer에 ROI Pooling을 적용한 vector를 넣어준다.
-
fully-connected layer는 분류를 수행하는 softmax와 bounding box regression을 진행하는 layer로 나뉘어진다.
✔ The RoI pooling layer

ROI Pooling layer는 feature map을 small feature map으로 변환하기 위해 max pooling을 적용합니다.
이때, ROI는 feature map으로 투영된 사각형 윈도우를 의미합니다.
ROI를 h X w, ROI Pooling 결과를 H X W라고 할 때, ROI Pooling에 적용되는 윈도우 크기는 (h/H X w/W)가 됩니다.
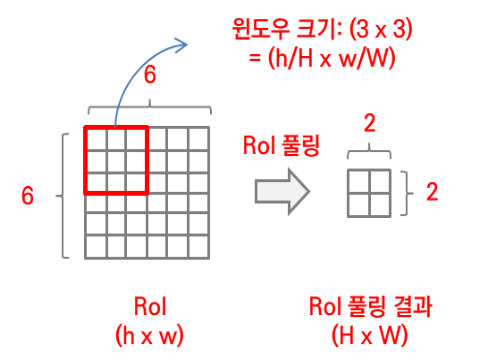
예를 들어, ㅁ X ㅁ feature map이 존재하고, 여기서 뽑아낸 ROI가 6 X 6이라고 가정합시다. 또한, 이를 ROI Pooling을 적용한 결과가 2 X 2가 되길 원한다고 가정해 봅시다. 그렇다면, max pooling을 적용하기 위해 사용되어야 하는 윈도우는 3 X 3입니다.
이는 SPPnet의 Spatial Pyramid Pooling과 비슷한 개념입니다. 실제로 논문에서도 SPP에서 Pyramid level이 1개인 경우와 같은 것이라고 설명합니다.
✔ Initializing from pre-trained networks

Fast R-CNN은 pre-trained된 모델의 가중치로 초기화 합니다.
다만, 이때 모델의 아키텍처 3가지가 바뀝니다.
1. 마지막 max pooling layer가 ROI Pooling layer로 바뀝니다.
2. network의 마지막 fully-connected layer와 softmax는 2개의 layer로 바뀝니다.
(fully-connected layer를 거친 softmax layer 하나와, fully-connected layer를 거친 bbox regression layer로 나뉩니다.)
3. 이렇게 만들어진 network는 2개의 데이터를 입력 받습니다.(image / ROI)
✔ Fine-tuning for detection

모든 네트워크의 가중치를 학습 하는 것은 Fast R-CNN의 중요한 능력입니다.
우선, SPPnet이 SPP layer 아래에서 가중치가 업데이트 되지 않는 이유를 살펴보겠습니다.
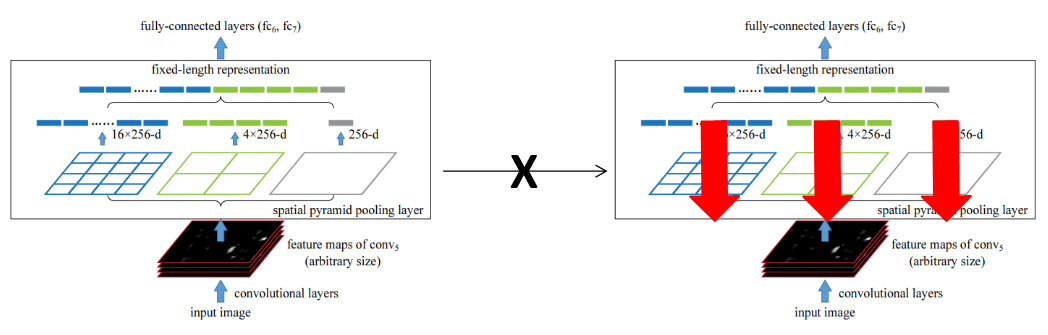
SPPnet에서 모든 가중치를 학습시킬 수 없는 이유는 SPP layer를 통한 back-propagation이 매우 비효율적이기 때문입니다.
이런 비효율성은 ROI가 매우 큰 수용장을 가지기 때문에 나타납니다. 사실상 전체 이미지가 training input으로 들어가게 된다는 말입니다.
논문에서는 더 효율적인 학습 방법을 제시합니다.
Fast R-CNN 학습 과정에서 SGD 미니배치는 각각의 이미지에 대해 R/N개의 ROIs를 샘플링합니다.(N은 이미지 개수) 같은 이미지로부터 온 ROIs는 컴퓨팅 연산과 메모리를 공유합니다.
이런 전략은 N=2, R=128에서 좋은 성능을 보여주었습니다.
게다가 Fast R-CNN은 multi stage training이 아닌 one stage training을 통해 학습합니다.
one stage training이 가능한 이유를 설명하겠습니다.
Multi-task loss

Fast R-CNN은 Multi-task loss를 사용합니다.
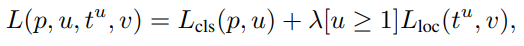
이는, 기존에 Classification loss와 localization loss를 합친 것입니다. 이를 통해 Classification과 regression을 동시에 학습시킬 수 있습니다.
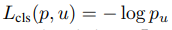
Cls loss = -log(pu)로 정의되며, 이때 u는 true class u입니다.
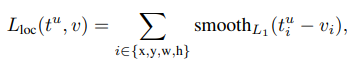
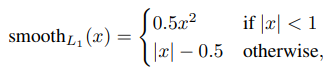
loc loss는 smooth loss의 합으로 정의됩니다.
이때, smooth loss는 L1 loss이며 이는 이전의 L2 loss보다 덜 민감하다는 특징이 있습니다.
smooth에는 t와 v가 들어가는데 t는 모델의 예측 값, v는 gt값 입니다.

클래스 분류 손실값과 회귀 손실값 사이의 균형을 잡아주는 람다가 있으며, 아이버슨 괄호라는 부분도 있습니다. 아이버슨 괄호는 객체가 존재할 때만 loc loss가 필요하다는 의미로 사용됩니다.
(배경인 경우 0 반환)
Mini-batch sampling

Fast R-CNN은 미니배치 샘플링 시 각 이미지당 64개의 ROI 정보를 샘플링합니다.
gt box와 IOU가 최소 0.5인 ROI 25%를 가져옵니다. 이 ROI를 Positive로 간주합니다.
IOU가 0.1 ~ 0.5 미만인 경우는 Negative로 간주합니다.
데이터 증강 훈련을 위해 50% 확률로 좌우 대칭을 진행하고 이외의 augmentation 기법은 적용하지 않습니다.
✔ Scale invariance

논문에서는 "scale invariant"를 수행하기 위해 두 가지 방법을 실험했습니다.
scale invariant는 변하지 않는 스케일을 의미하며, 이는 이미지의 크기가 불변함을 의미합니다.
논문에서는 "brute force" 학습 방식과 "pyramids" 학습 방식을 실험했습니다.
brute force 학습 방식은 각 이미지를 정해진 픽셀 크기로 받는 것을 의미합니다.

반면, pyramid(multi-scale) 학습 방식은 image pyramid를 통해 scale invariant를 갖게 합니다. 이전에 정의한 이미지 크기가 들어오는 것이 아닌 다양한 크기의 이미지가 들어온다는 것입니다.
(이는 SPPnet의 구조와 거의 동일합니다.)
3. Fast R-CNN detection

Fast R-CNN 네트워크는 이미지와 R object proposals를 입력받습니다.
image pyramid 학습 방식을 사용할 경우, 각 RoI가 할당됩니다. 이때 RoI는 224제곱 픽셀에 가까워집니다.
✔ Truncated SVD for faster detection

이미지 분류시, fully connected layer는 conv layer에 비해 시간이 덜 소요됩니다.
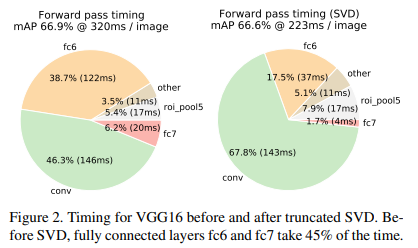
하지만, detection시에는 RoI의 수가 상당히 많고, fully connected layer에 드는 시간이 전체의 절반가량 됩니다.
논문에서는 이런 문제를 truncated SVD 기법을 이용하여 해결합니다.
SVD에 대한 자세한 설명은 이전에 다룬 적 있으니 참고하시기 바랍니다.
[ML] 차원 축소(dimensionality reduction) PCA, LDA, SVD, NMF
4. Conclusion
이전 모델보다 성능은 높이고, 예측 시간을 줄인 Fast R-CNN에 대해 알아보는 시간을 가졌습니다.
Fast R-CNN에서 새롭게 도입한 기술은 다음과 같았습니다.
- RoI Pooling
- Multi loss
sigle level SPP라고 언급한 RoI Pooling을 통해서 다양한 이미지 크기가 모델에 들어올 수 있습니다.
또한, Multi loss를 이용해 cls와 reg를 한번에 학습시킬 수 있었습니다.
Referecne
