1. Semantic Segmentation
- CNN을 영상단위로 하는것이 아니라 픽셀 단위로 하는 것
- 영상 속의 물체에 mask를 생성. 하지만 같은 클래스이지만 서로 다른 물체를 구분하지는 않는다.
어디에 사용?
- 의료 이미지
- 자율주행
2. Semantic Segmentation architectures
2.1 Fully Convolutional Networks(FCN)
-
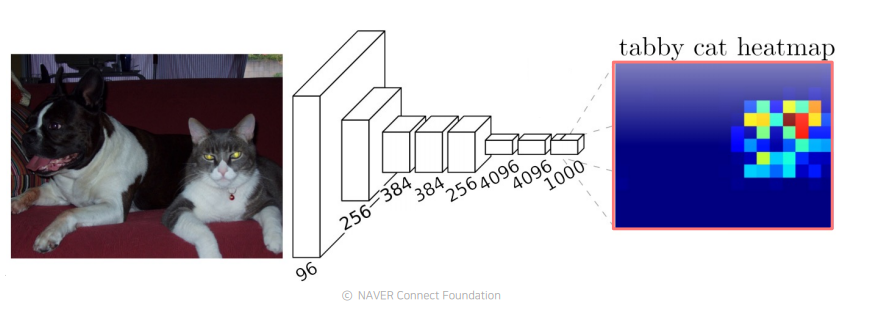
sematic segmentation을 위한 첫번째 end-to-end architecture
-
특정 해상도에 학습이 되었더라도 테스트 할 때 임의의 사이즈에 영상을 입력으로 사용해도 문제없이 작동하는, 호환성이 높은 구조이다.
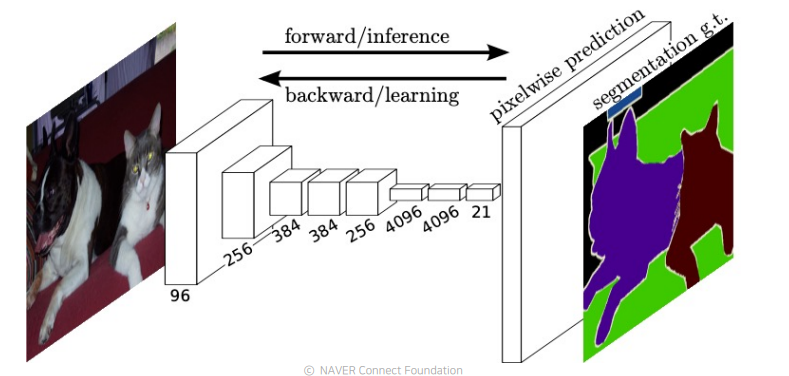
-
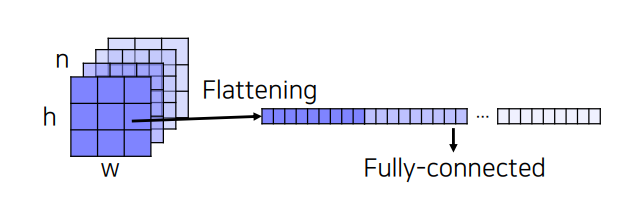
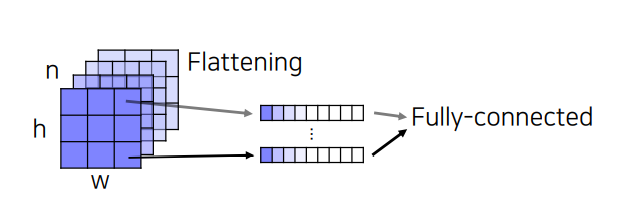
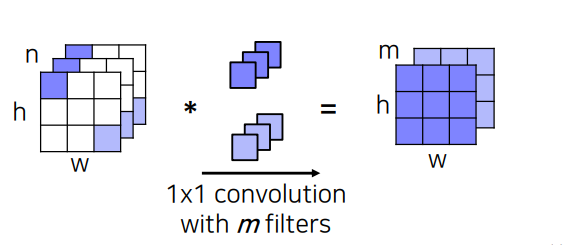
FC layer를 1x1 convolution으로 대체 함으로써 공간의 정보를 담아낸다.
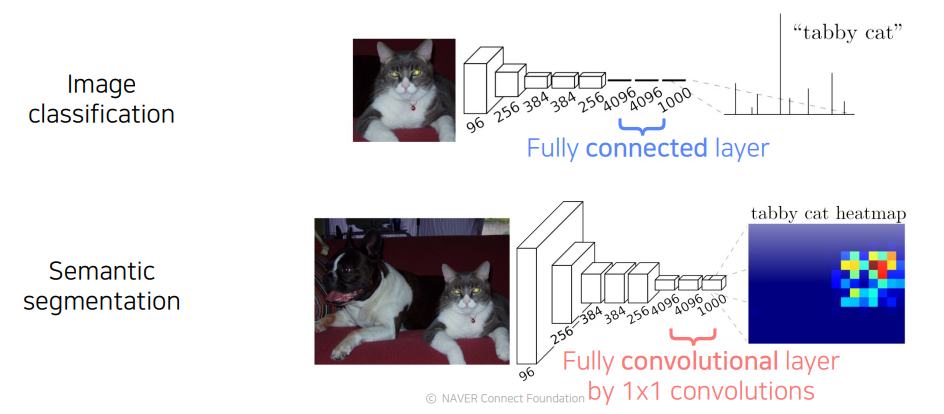
-
FC layer
-
1x1 convolution
-
pooling layer나 stride로 인해서 최종 activation map의 해상도는 저해상도인 경우가 많다. pooling layer나 stride는 receptive field 사이즈를 키워서 넓은 contest를 고려한다.(넓은 면적을 보게 되므로 좀 더 정답에 가까운 결론을 내릴 수 있게 한다.)그렇기 때문에 해상도를 필연적으로 낮추게 되므로 저해상도 문제를 회피하기 위해 upsampling을 도입한다.
-
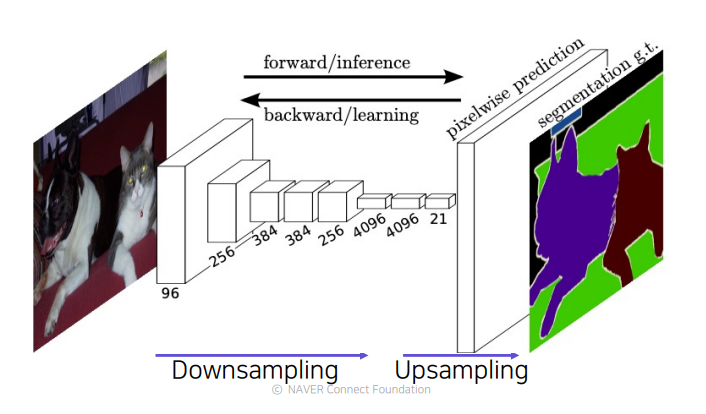
FCN(Fully Connected Network)에서는 작은 activation map을 원래 사이즈에 맞춰주기 위해서 upsampling layer를 사용한다.(Transopsed convolution, Upsample and convolution)
-
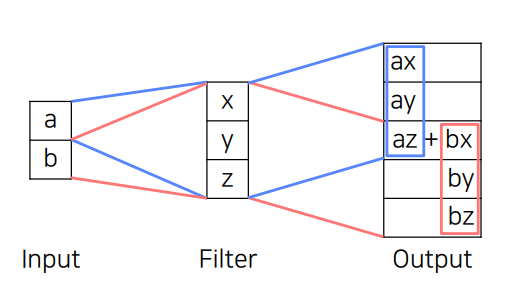
Transopsed convolution : 학습 가능한 upsamping을 하나의 layer로 한번에 처리한것. 중첩된 부분은 계속 더해진다. -> 일부만 오버랩되는 단점이 생김

-
upsampling convolution : upsampling operation을 두개로 분리. 간단한 영상처리 operation으로 많이 쓰이는 imterpolation을 먼저 적용하고, Nearest-neighbor(NN), Bilinear를 많이 사용한다. 여기까지는 학습 가능한 파라미터가 들어가 있지 않고, 해상도만 키워줬지만, 학습 가능한 learnable upsampling으로 만들어 주기 위해서 convolution을 적용시켜 준다.

-
아무리 upsampling을 했다 하더라도 해상도가 이미 줄어든 상태에서 잃어버린 정보를 다시 살리는것은 쉽지 않다. 따라서 각 layer별로 activation map의 해상도와 의미를 살펴보면
-
낮은 layer쪽에서는 receptive field사이즈가 작기 때문에 국지적이고 작은 디테일을 보고, 작은 차이에도 민감하다.
-
높은 layer쪽에서는 해상도는 꽤 낮아지지만 큰 receptive field를 가지고 영상에서 전반적이고 의미론적인 정보들을 많이 포함하는 경향을 가지고 있다.
-
sementic segmentation에서는 두개 모두가 필요하다. 각 픽셀별로 의미를 파악해야하고, 영상전체를 바라보면서 현재 하나의 픽셀이 물체의 안쪽에 해당하는지, 바깥쪽에 해당하는지도 파악해야한다.

-
따라서 두 특징을 모두 확보하기위해서 fusion을 한다.
-
높은 layer에 있던 activation map을 upsampling을 통해서 해상도를 크게 올리고, 그에 맞춰서 중간층의 activation map을 upsampling해서 가져온다. 이것을 concatenate 해서 최종 출력을 만들게 된다. FCN-8s가 가장 많은 activation map을 사용하는 버전이다.
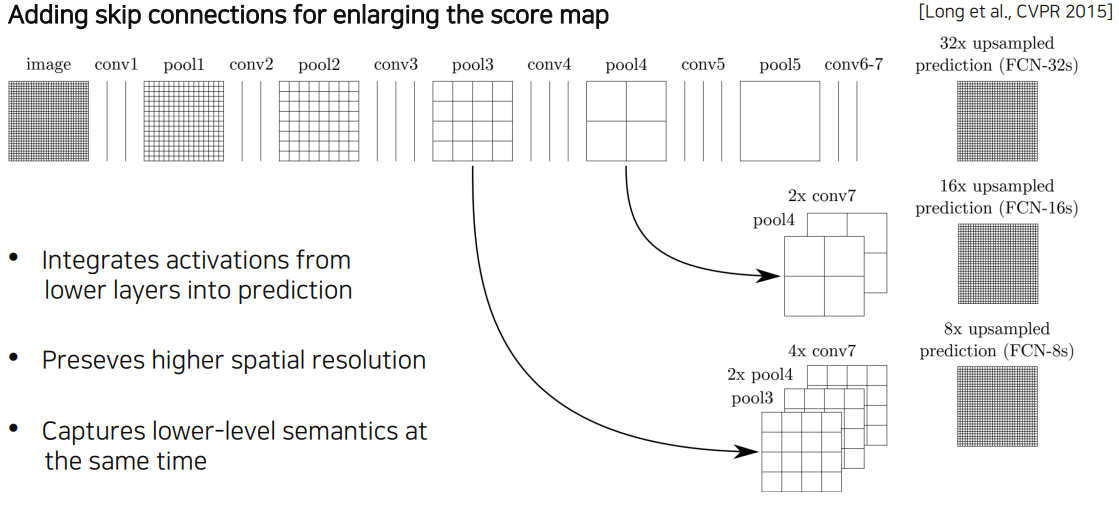
-
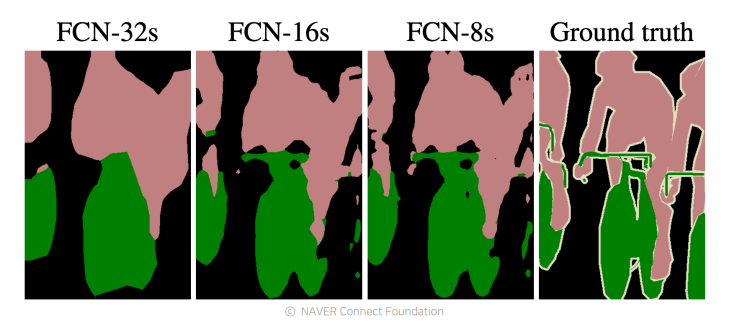
Features of FCN
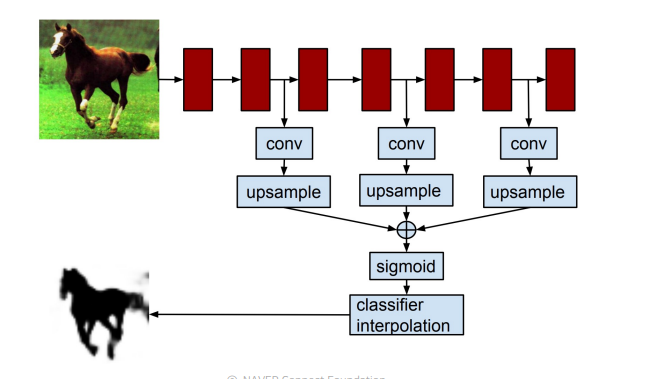
2.2 Hypercolumns for object segmentation
- FCN과 많은 부분이 유사하지만 바운딩 박스를 먼저 친 이후에 적용하는 부분이 다르다.
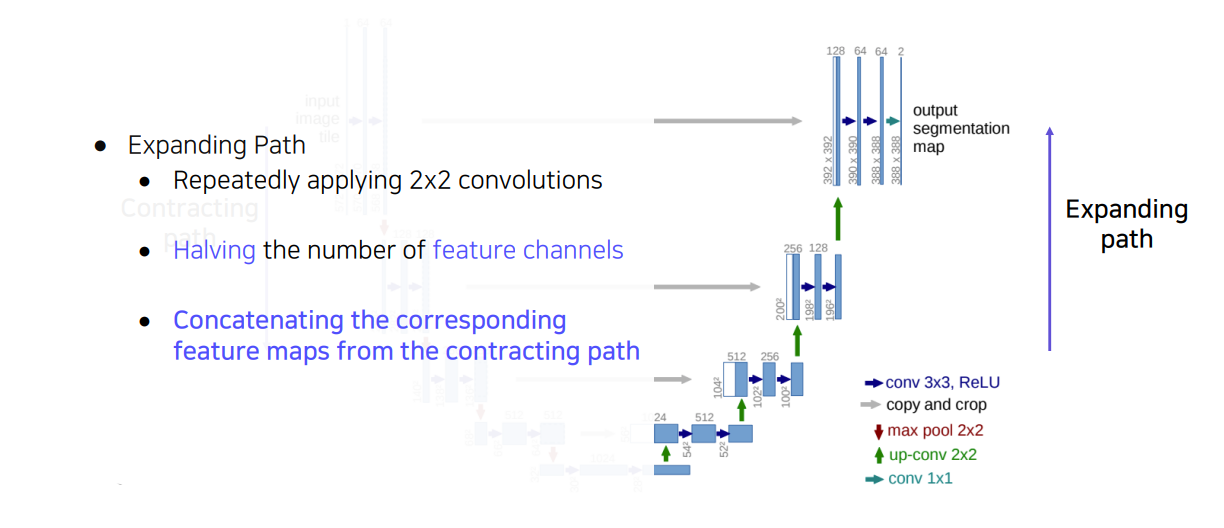
2.3 U-Net
- fully convolutional network이다.
- 낮은 층의 feature와 높은 층의 특징을 잘 결합하는 방법을 제시했다.(skip connection을 통해서)
- FCN 모델보다 더 정교한 segmentation 결과물을 볼 수 있다.


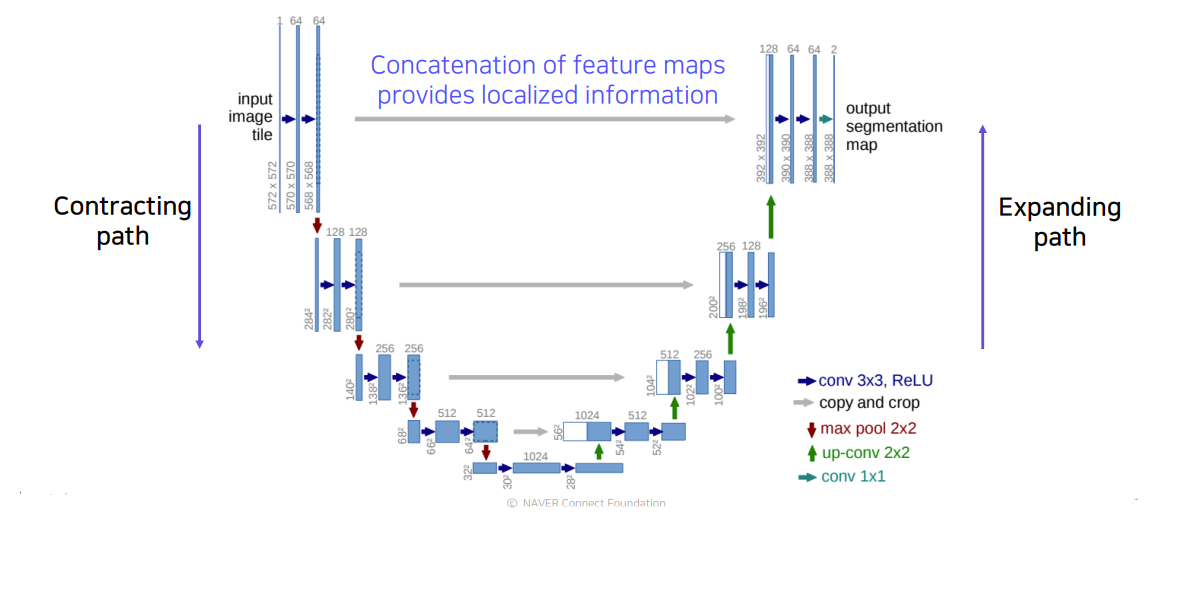
-
Concatenation of feature maps provides localized information : 공간적으로 높은 해상도 와 입력이 약간 바뀌는것 만으로도 민감한 정보를 제공하기 때문에 경계선이나 공간적으로 중요한 정보들을 뒤쪽 layer에 바로 전달한다.
-
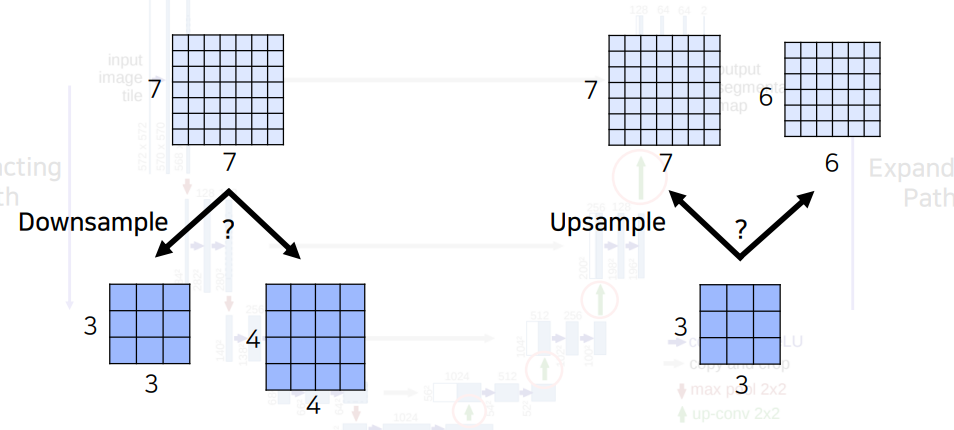
feature map 즉, activation map의 saptial size가 홀수이면 다운샘플링 후 업샘플링을 하는데 있어서 돌아올 수 없다.(다운샘플링 또한 버림인지, 반올림, 올림인지 구현에 따라 다를 수 있으므로 항상 꼼꼼하게 체크해야한다.) 따라서 중간에 어떤 layer에서도 홀수 해상도의 activation map이 나오지 않도록 유의해야한다.
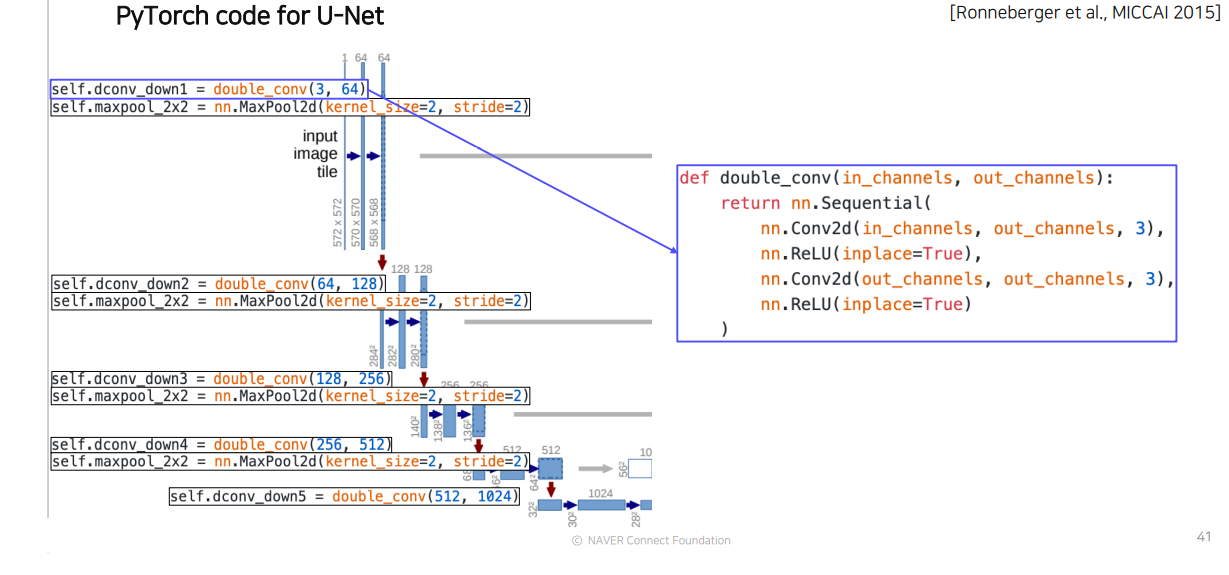
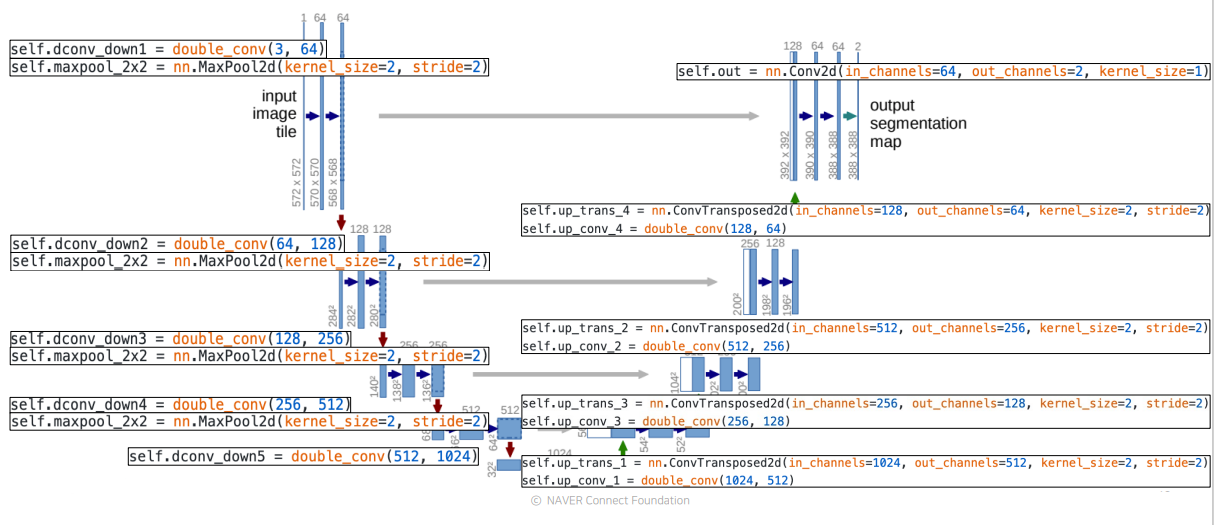
U-Net의 PyTorch code
2.4 DeepLab
-
Conditional Random Fields(CRFs)
- 픽셀과 픽셀 사이의 관계를 모두 이어주고 regular한 gride(pixel map)를 그래프로 본것. 즉, 경계를 잘 찾을 수 있도록 한것.
- sementic segmentation이후 후처리 하는것.
-
Dilated convolution
- convolution 사이에 일정 공간을 넣어주는것으로, weight사이를 한칸씩 띄어서 실제 convolution 커널보다 더 넓은 영역을 고려할 수 있게하면서, parameter를 늘리지 않는다.
-
Depthwise separable convolution

