Transformer
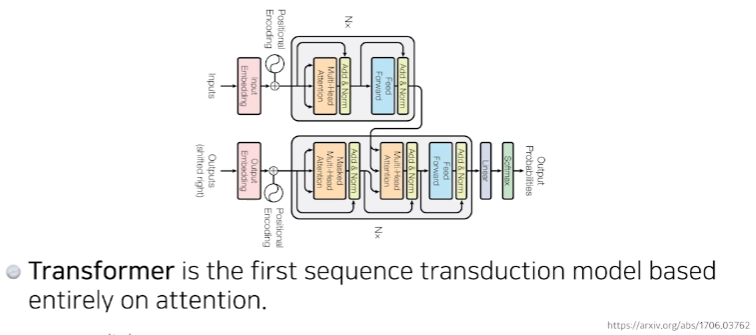
- attention이라고 불리는 구조를 활용했다.
- transformer는 단순히 기계어 번역에만 활용되는것이 아니라 이미지 분류, 이미지 디텍션, 비주얼 트랜스포머 등 많은곳에서 활용된다.

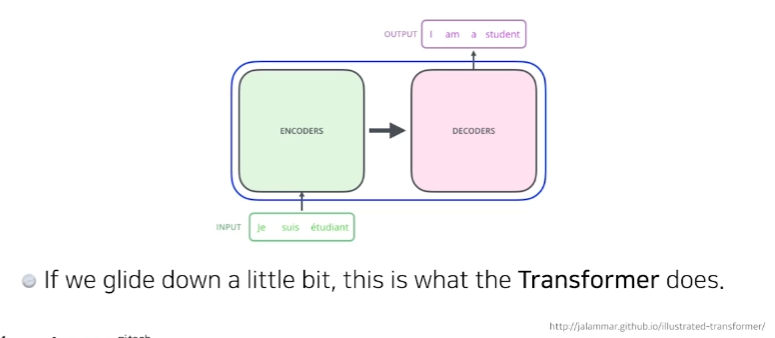
- sequence to sequence model
- 여기서는 불어를 영어로 바꾼다.

- 입력 : 3개의 단
- 출력 : 4개의 단
- 입력 sequence와 출력 sequence의 수는 다를 수 있다.
- 입력 sequecne의 domain과 출력 sequence의 domain이 다를 수 있다.
- n개의 단어를 한번에 처리한다.
어떻게 n개의 단어를 한번에 처리하는지?

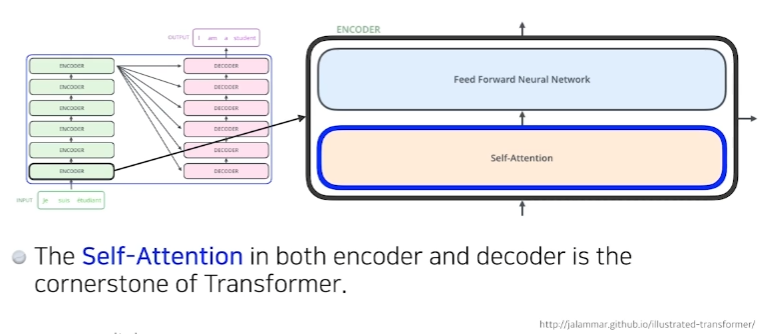
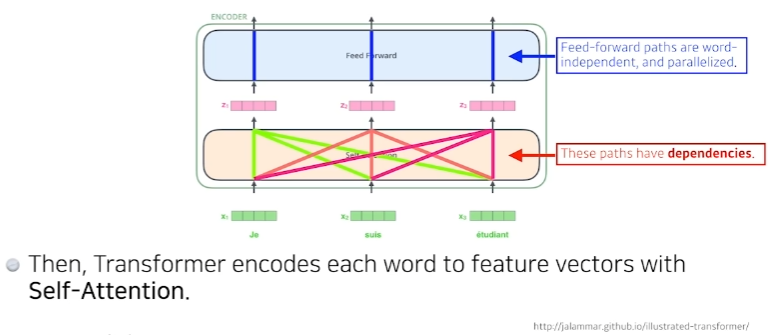
- self-Attention이라는 구조와 Feed Forward Neural Network를 한단씩 거치는것이 하나의 encoder이다.
- 그 n개의 출력값이 두번째 encoder로 들어간다.
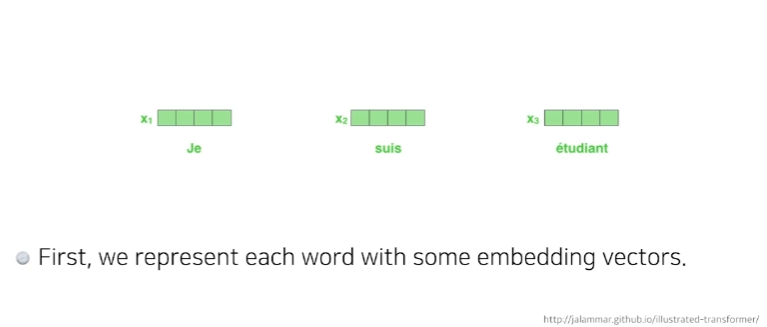

-
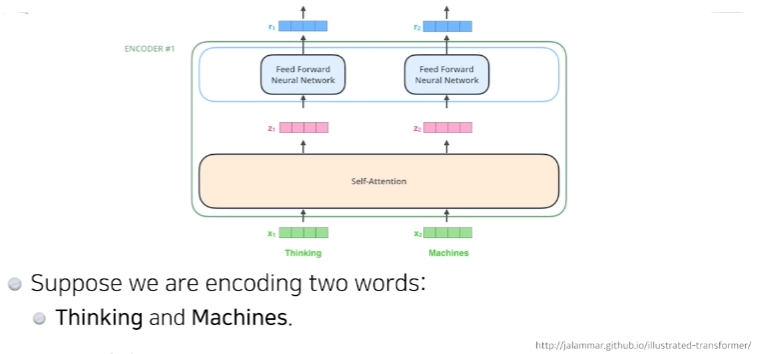
Self-Attention은 n개의 x가 주어지고 n개의 z벡터를 찾는데 각각의 i번째 x벡터를 로 바꿀 때 나머지 n-1개의 x벡터를 같이 고려하는것이 요점이다.

-
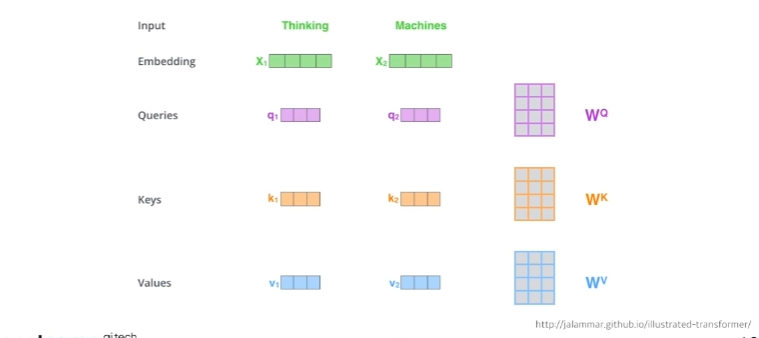
단어가 주어졌을 때(Thinking, Machines) self-attention 구조는 3가지 벡터를 만들어낸다.(3개의 뉴럴네트워크를 만든다.) Queries, Keys, Values
-
이 3개의 벡터를 통해서 x_1이라고 불리는 첫번째 단어에 대한 embedding 벡터를 새로운 벡터로 바꿔준다.
-
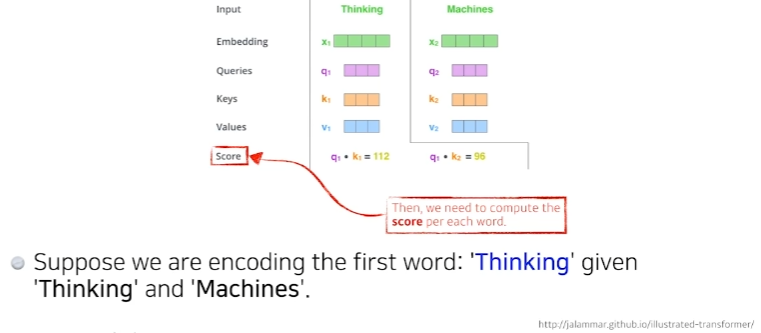
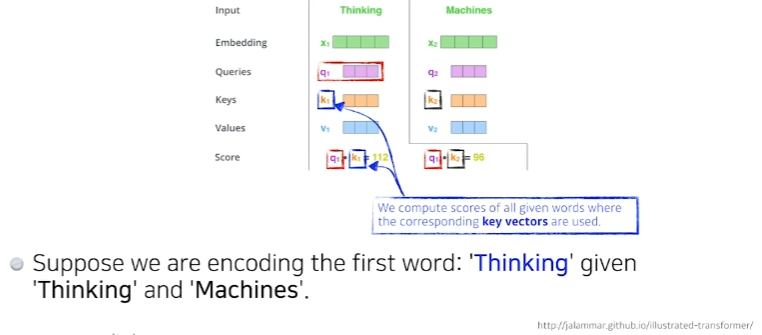
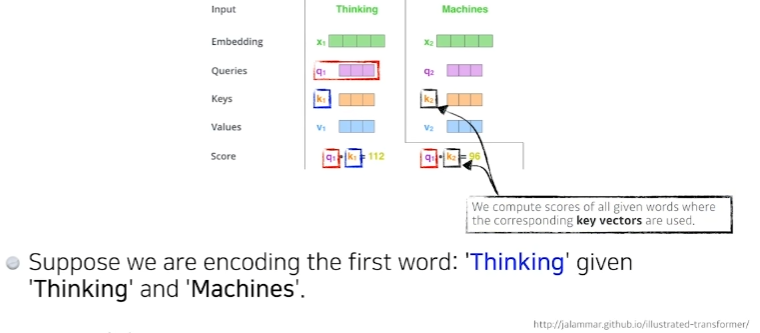
두 단어 중 Thinking이라는 단어를 embedding 하고 싶을 때,(각각의 단어마다 Queries, Keys, Values 벡터를 만들었는데) 추가로 score 벡터를 만든다.

-
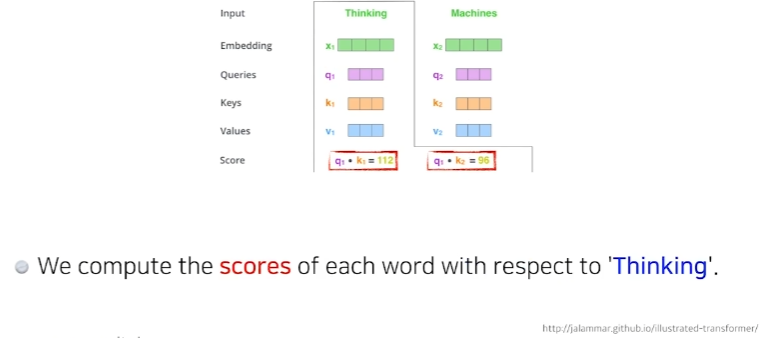
score 벡터는 내가 인코딩 하고자 하는 벡터(단어)의 Query벡터와 나머지 모든 n개에 대한 key벡터를 구해서 내적하는 것이다. 즉, i번째 단어가 나머지 단어와 얼마나 유사도가 있는지를 이런식으로 정하게 된다.
-
이 과정을 통해 우리는 단어에 score벡터로 만들 수 있다.

-
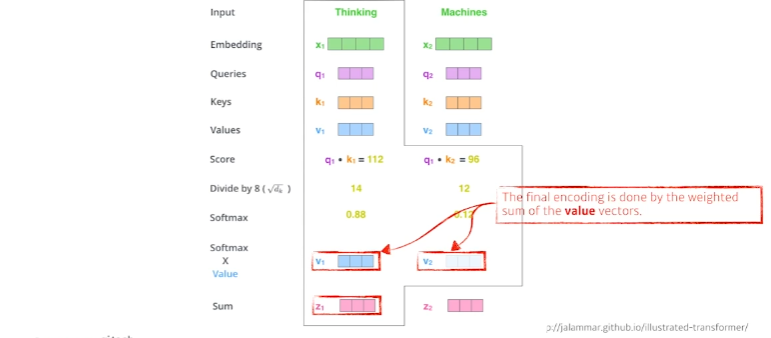
score 벡터가 나오면 key벡터의 dimension으로 나눠준다.(여기서는 64개의 벡터로 만들어서 루트를 씌운 8) -> 이 과정을 통해 score 값 자체가 너무 커지지 않게 하기위해
-
그 후 softmax를 취하면 단어간에 interaction을 알 수 있다.(여기서는 자기 자신과의 attention weigt는 0.88이되고, 다른 단어와의 attention weight는 0.12가 된다.)
-
위에서 구한 attention weigh와 Value벡터와 weighted sum을 한 것이 최종적으로 나오는 Thinking이라는 단어에(Thinking이라는 단어에 해당하는 embedded 벡터에) 인코딩된 벡터가 되는 것이다. 이 과정을 모두 거치면 하나의 단어에 대한 인코딩 벡터가 나오게 된다.
-
주의 할 점 :
- query 벡터와 key벡터는 항상 차원이 같아야 한다.
- value 벡터는 차원이 달라도 된다.(value벡터는 weighted sum을 하기만 하면되므로)
- 최종적으로 인코딩된 벡터의 차원은 value 벡터의 차원과 동일하다.(이 section에서는)
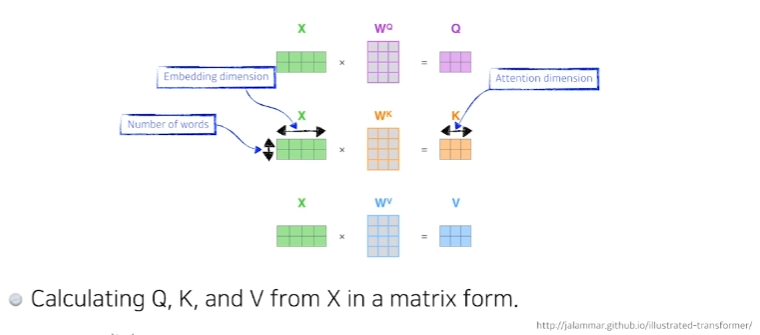
- 행렬 연산으로 모든 과정을 한번에 할 수 있다.

- quary벡터와 key벡터를 내적해서 스칼라를 뽑고, 그 값을 squared key dimension으로 나눠주고, softmax를 취한 다음에 value 벡터에 대해서 weighted sum을 하는 과정이 이 한줄로 모두 표현된다.
positional encoding
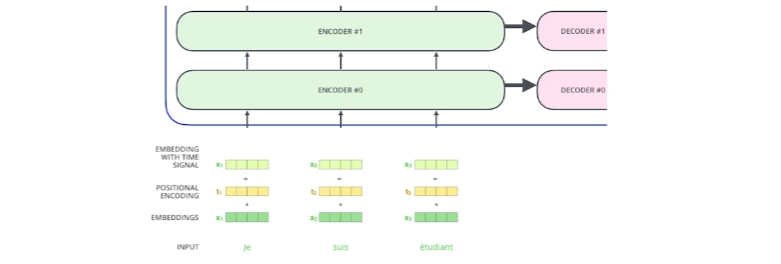
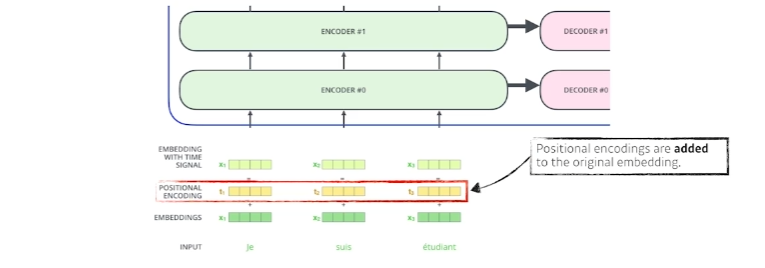
- n개의 단어를 Sequential(순차적으로)하게 넣어줬다고 치지만 Sequential한 정보가 이 안에 포함되어 있지 않다.(ABCD를 넣거나 BCDA를 넣거나 DACB를 넣거나 각각의 A단어 B단어 C단어 D단어가 encoding되는 값은 달라질 수 없다.) 우리가 문장을 만들 때는 어떤 단어가 먼저나오는지가 중요하기 때문에 positional encoding이 중요하게 된다.
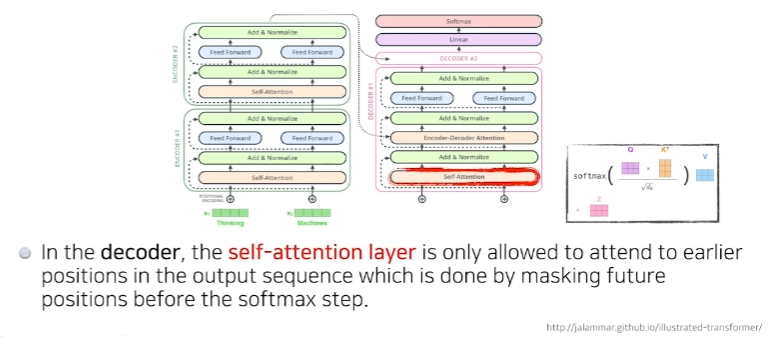
Add & Normalize
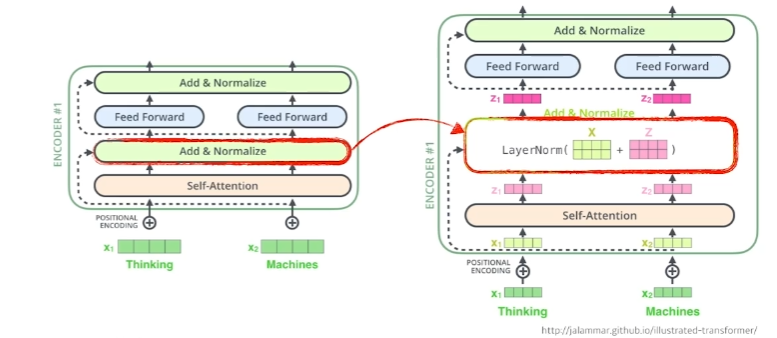
Encoder-Decoder Attention layer
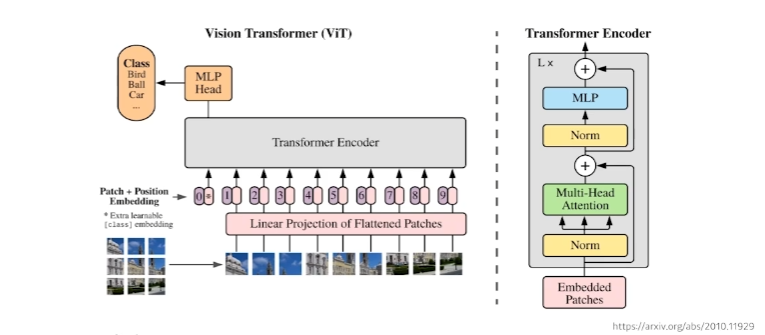
Vision Transformer
DALL-E

- 문장이 주어지면 문장에 대한 이미지를 만들어냄
