해커랭크, 리트코드 에서 문제를 풀어볼거다.
목표 : 프로그래머스의 고득점sql 키트 를 풀 수 있도록 하는 것
https://www.hackerrank.com/dashboard
https://www.w3schools.com/sql/trysql.asp?filename=trysql_select_all
https://leetcode.com/problemset/all/
count
갯수를 센다. NaN 는 제외하고 센다.
SELECT COUNT(*) FROM sample -> 5
SELECT COUNT(Name) FROM sample ->4
SELECT COUNT(DISTINCT(Name)) FROM sample ->3DISTINCT
는 해당 컬럼의 중복값을 제거한다.
SUM, AVG
SUM은 총합을 센다.
AVG는 평균인데, NULL 값을 제외하고 생각해서 계산한다.
(mysql 기준)
SELECT SUM(Price) FROM Products
SELECT AVG(Price) FROM Products
-- NULL 값을 0이라고 생각하고 평균을 구하고 싶을 때
SELECT SUM(Price)/COUNT(*) FROM ProductsMIN, MAX
MIN 은 최솟값이다.
MAX 는 최댓값이다.
SELECT MIN(Price) FROM Products
SELECT MAX(Price) FROM Products
SELECT
COUNT(Price), SUM(Price), AVG(Price), MIN(Price), MAX(Price)
FROM ProductsGROUP BY
카테고리별로 묶어서 보고 싶을 때 쓴다.
GROUP BY 해준 컬럼을, SELECT 절에도 써줘야 한다.
-- 공급자별 평균 가격
SELECT SupplierID
, AVG(Price)
FROM Products
GROUP BY SupplierID
-- 공급자별, 카테고리별 평균 가격
SELECT SupplierID
, CategoryId
, AVG(Price)
FROM Products
GROUP BY SupplierID, CategoryId
-- *줄을 잘 맞춰써 이쁘게 쓰자
여러 기준으로 묶어주고 싶다면
GROUP BY에 , 를 하고 붙여서 써준다.
# GROUP BY 절에 숫자가 가능!
SELECT SupplierID, CategoryId, AVG(Price)
FROM Products
GROUP BY 1, 2GROUP BY에 숫자가 올 때가 있는데 이는 SELECT 절에 있는 첫번째, 두번째 컬럼을 쓰겠다는 거다. 이 기능은 권장되지 않는다.
GROUP BY 결과물을 가지고 ORDER BY를 할 수 있다.
SELECT SupplierID, CategoryId, AVG(Price)
FROM Products
GROUP BY SupplierID, CategoryId
ORDER BY AVG(Price) DESC
평균(집계함수) 가격이 100이상인 것을 보고 싶을 때는, GROUP BY 결과물을 기준으로 조건을 걸고 싶은 거기 때문에 HAVING 절을 사용해야 한다.
SELECT SupplierID, CategoryId, AVG(Price)
FROM Products
GROUP BY SupplierID, CategoryId
HAVING AVG(Price) >=100
-- Alias 를 사용 할 수 있다.
SELECT SupplierID
, CategoryId
, AVG(Price) AS avg_price
FROM Products
GROUP BY SupplierID, CategoryId
HAVING avg_price >=100
집계함수 문제풀이
SELECT round(avg(population),3)
FROM CITY
WHERE district = "California";
SELECT SUM(population)
FROM city
WHERE District = "California";
SELECT COUNT(*)
FROM CITY
WHERE population > 100000;
CEIL() 올림
FLOOR() 내림
ROUND() 반올림
SELECT floor(avg(population))
FROM city;
SELECT (MAX(population) - MIN(population))
FROM CITY;
SELECT COUNT(CITY) - COUNT(DISTINCT(CITY))
FROM STATION;GROUP BY 문제풀이
https://www.hackerrank.com/challenges/earnings-of-employees/problem?isFullScreen=true
SELECT (salary*months) as earnings , COUNT(*)
FROM EMPLOYEE
GROUP BY earnings
ORDER BY earnings desc
LIMIT 1;- alias 붙인 컬럼도 GROUP BY 가 된다.
- 근데 그럴때 집계 함수는 에 대해서만 된다.
count(earnings) 도 안되고, count(employee_id) 도 안된다.
CASE
sql 의 조건절이다.
/* CASE
WHEN (A조건) THEN (A조건이 True 일 때)
WHEN (B조건) THEN (B조건이 True 일 때)
ELSE (위의 조건이 모두 False 일 때)
END */
SELECT CASE
WHEN CategoryID = 1 THEN '음료'
WHEN CategoryID = 2 THEN '조미료'
ELSE '기타'
END AS categoryName, *
FROM Products
# AND, OR 같은 논리 연산자
SELECT CASE
WHEN CategoryID = 1 AND SupplierID=1 THEN '음료'
WHEN CategoryID = 2 THEN '조미료'
ELSE '기타'
END AS categoryName, *
FROM Products
case 문으로 만들어진 컬럼으로 group by 도 할 수 있다.
SELECT CASE
WHEN CategoryID = 1 AND SupplierID=1 THEN '음료'
WHEN CategoryID = 2 THEN '조미료'
ELSE '기타'
END
AS categoryName
, AVG(price)
FROM Products
GROUP BY categoryName
첫번째 WHEN 절에 해당이 되면, 다음조건을 볼 때 해당 데이터는 아래 조건으로 넘어가지 않는다.
그래서 WHEN 절을 써주는 순서도 중요하다.
select CASE
-- WHEN 절의 순서를 바꾸면 결과가 달라진다.
WHEN A = B AND A = C AND B = C THEN 'Equilateral'
WHEN A + B <= C OR A + C <= B OR B + C <= A THEN 'Not A Triangle'
WHEN A = B OR A = C OR B = C THEN 'Isosceles'
ELSE 'Scalene'
END AS NAME
FROM TRIANGLES ;sql에서 세로로 출력되는 데이터를 가로형으로 바꿀 수도 있다.
select avg(case when categoryid = 1 then price else NULL end) AS category1_price,
avg(case when categoryid = 2 then price else NULL end) AS category2_price,
avg(case when categoryid = 3 then price else NULL end) AS category3_price
from products
-- 요약 통계를 case 를 이용해서 옆으로 보여주는 거다.case 문제 풀이
https://leetcode.com/problems/reformat-department-table/
-- 테이블을 피보팅한것
select
id,
SUM(case when month = 'Jan' then revenue ELSE NULL END) AS 'Jan_Revenue',
SUM(case when month = 'Feb' then revenue ELSE NULL END) AS 'Feb_Revenue',
SUM(case when month = 'Mar' then revenue ELSE NULL END) AS 'Mar_Revenue',
SUM(case when month = 'Apr' then revenue ELSE NULL END) AS 'Apr_Revenue',
SUM(case when month = 'May' then revenue ELSE NULL END) AS 'May_Revenue',
SUM(case when month = 'Jun' then revenue ELSE NULL END) AS 'Jun_Revenue',
SUM(case when month = 'Jul' then revenue ELSE NULL END) AS 'Jul_Revenue',
SUM(case when month = 'Aug' then revenue ELSE NULL END) AS 'Aug_Revenue',
SUM(case when month = 'Sep' then revenue ELSE NULL END) AS 'Sep_Revenue',
SUM(case when month = 'Oct' then revenue ELSE NULL END) AS 'Oct_Revenue',
SUM(case when month = 'Nov' then revenue ELSE NULL END) AS 'Nov_Revenue',
SUM(case when month = 'Dec' then revenue ELSE NULL END) AS 'Dec_Revenue'
FROM Department
group by id;
/*
{"headers":
[
"id", "Jan_Revenue", "Feb_Revenue", "Mar_Revenue", "Apr_Revenue", "May_Revenue", "Jun_Revenue", "Jul_Revenue", "Aug_Revenue", "Sep_Revenue", "Oct_Revenue", "Nov_Revenue", "Dec_Revenue"],
"values":
[
[1, 8000, 7000, 6000, null, null, null, null, null, null, null, null, null],
[2, 9000, null, null, null, null, null, null, null, null, null, null, null],
[3, null, 10000, null, null, null, null, null, null, null, null, null, null]
]}
*/Join
inner join
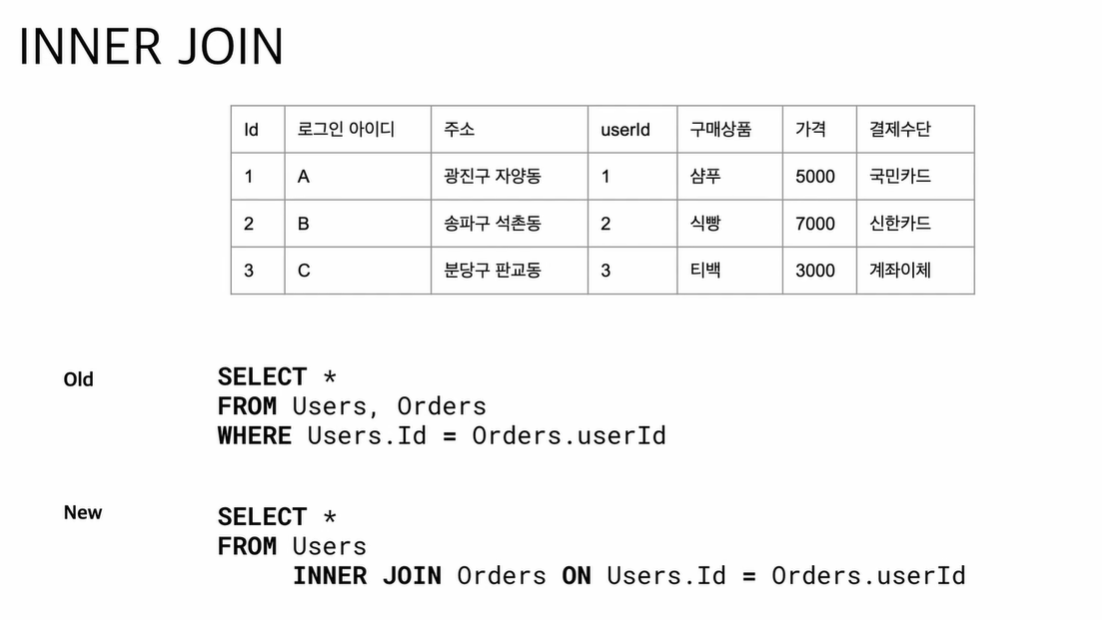
inner join은 양쪽 테이블에 다 정보가 있을 때에만 출력이 된다.
select * from Orders
INNER JOIN Customers ON ORDERS.CustomerID = Customers.CustomerIDleft join
왼쪽 테이블에는 데이터가 있고, 오른쪽 테이블에는 데이터가 없을 때 하는 join이다.
오른쪽 데이터의 없는 값들은 NULL 로 나온다.
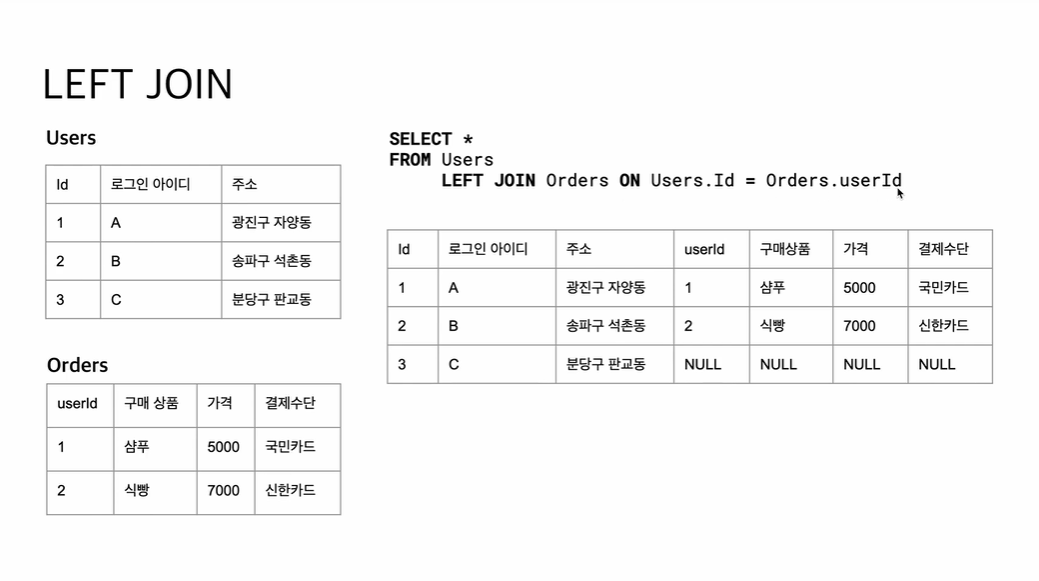
주로 left join을 선호한다. (해석상의 편의)
시간을 더하고 빼기
date_add(기준날짜, Interval)
select date_add(now(), interval 1 second)
select date_add(now(), interval 1 minute)
select date_add(now(), interval 1 hour)
select date_add(now(), interval 1 day)
select date_add(now(), interval 1 month)
select date_add(now(), interval 1 year)
select date_add(now(), interval -1 year)
date_sub(기준날짜, Interval)
select date_sub(now(), interval 1 year)오후 강의
추천도서
RFM Segmentation
- Recency: 얼마나 최근에 구매했는지
- Frequency: 얼마나 자주 구매했는지
- Monetary: 얼마나 많은 금액을 구매했는지
이 기준으로 고객을 분류하는 방법론이다.
테이블 피봇
행으로 나열되어 있는 데이터를 열 방향으로 변환해서 데이터를 보기 쉽게 하려고 사용한다.
피봇을 하기 위해 열 방향으로 쪼갠다.
