어떤 데이터를 분석 할 것인가?
수업에서 실습을 할 때 주식 및 금융 데이터로 분석을 했었기 때문에 그렇다면 부동산을 해볼까?는 생각으로 '부동산 데이터' 로 설정하고 스크랩핑 및 EDA 분석을 진행하기로 했다.
이슈
대부분의 부동산 데이터들이 지도상에 표기가 되어 있어서 스크랩핑을 할 수 없었다.
스크랩핑 할 수 있는 데이터를 찾다가 부동산 경매 데이터를 찾게 됐다.
https://auction.realestate.daum.net/v15/
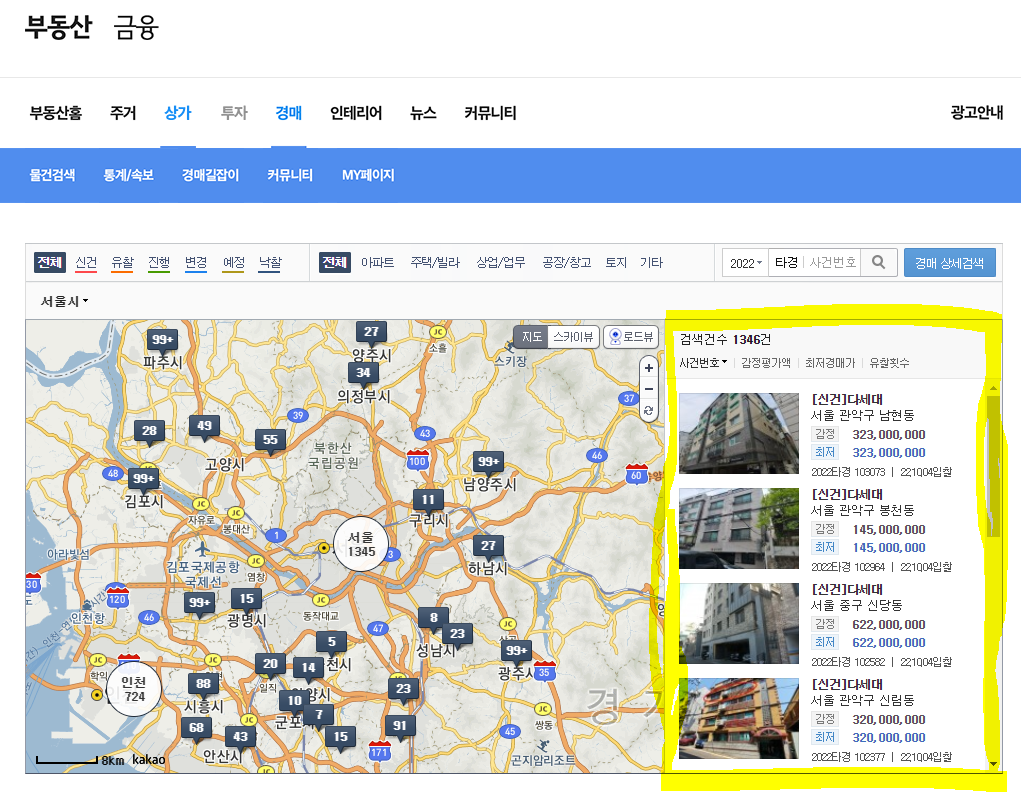
개발자 도구로 호출 할 수 있는 url 찾기
개발자도구에서 network 탭을 통해서
해당 화면에서 더보기를 눌렀을 때 url 을 확인 했다.
해당 url 은 post 방식으로 호출 하고 있는 걸 확인 할 수 있다.
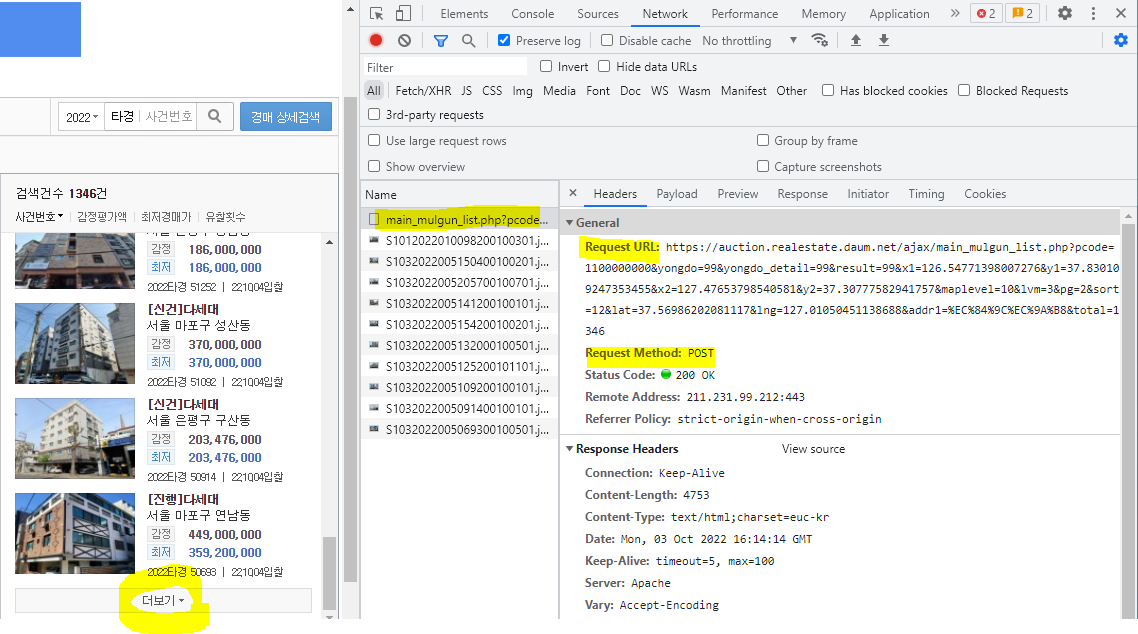
웹 데이터 스크랩핑
# 필요한 라이브러리 설정
import pandas as pd
import numpy as np
import requests
import time
import matplotlib.pyplot as plt
import seaborn as sns
# auction 데이터를 가져와서 파일로 저장하는 함수
def get_auction_list():
json_list = []
for page_no in range(50):
# url 준비
page_no += 1
addr1="서울"
url = f"https://auction.realestate.daum.net/ajax/main_mulgun_list.php?pcode=1100000000&yongdo=99&yongdo_detail=99&result=99&x1=126.54771398007276&y1=37.830109247353455&x2=127.47653798540581&y2=37.30777582941757&maplevel=10&lvm=3&pg={page_no}&sort=12&lat=37.56986202081117&lng=127.01050451138688&addr1={addr1}&total=1273"
# 데이터 받아오기
response = requests.post(url)
# json data 로 만들기
json_data = response.json()
# json data를 리스트로
list_temp = json_data["rtn"]["list"]
json_list.extend(list_temp)
time.sleep(0.1)
# 리스트를 dataFrame 으로
df_auction = pd.DataFrame(json_list)
# 컬럼 정리
df_auction = df_auction.drop(["num", "bubcd", "sano2", "sano1", "mul_seq", "tget", "im", "image"], axis=1)
#파일 이름 만들기
file_name = "auction.csv"
#파일로 저장
df_auction.to_csv(file_name, index=False, encoding="cp949")
return file_name
# 함수 호출하기
file_name = get_auction_list()
# 파일 불러오기
df = pd.read_csv(file_name, encoding="cp949", thousands = ',')
df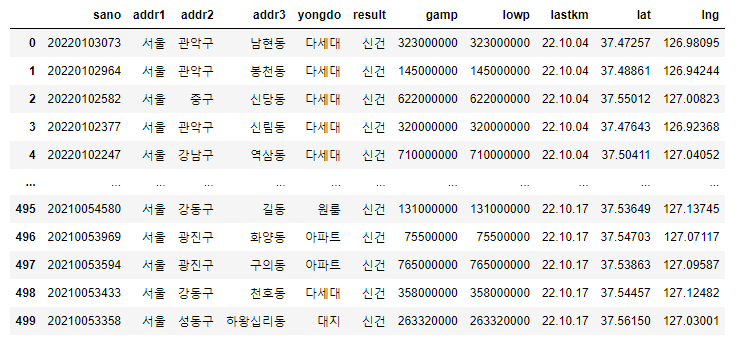
파생변수 만들기
감정가(gamp)와 최저가(lowp) 차이로 diff 라는 파생변수를 만들었다.
df["diff"] = df['gamp'] - df['lowp']기본 통계 값들 확인하기
기본 정보
df.info()
결측치의 합계
df.isnull().sum()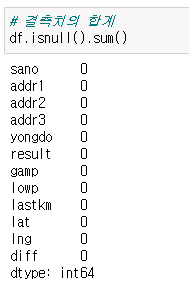
중복데이터 제거
df.shape # (500, 12)
# 중복값 확인 및 제거
df.duplicated()
df = df.drop_duplicates()
df.shape # (483, 12)결측치 제거 후 17개만큼 데이터가 줄어든 것을 확인 할 수 있다.
데이터 타입 확인
df.dtypes
수치형 기술통계
df.describe()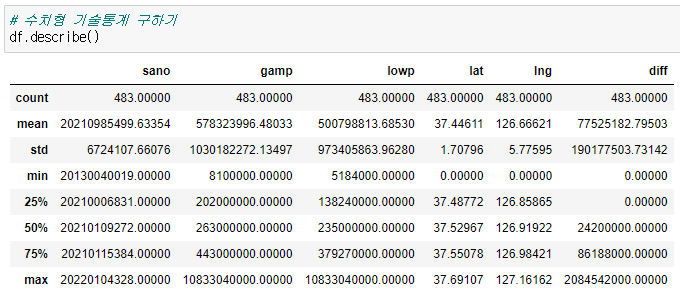
- 감정가(gamp) 와 최저가(lowp) 는 표준편차가 크다.
- 위도(lat) 경도(lng) 는 표준편차가 굉장히 작다는 걸 알 수 있다. 서울지역을 기준으로 데이터를 추출했기 때문이다.
- diff 는 감정가와 최저가의 차이이기 때문에 최소값이 0이다.
범주형 기술통계
df.describe(include=["object"])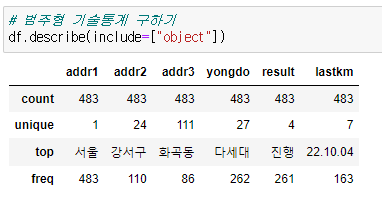
- addr2 를 확인하면 강서구에서 매물이 가장 많은 걸 알 수 있다.
- addr3 을 확인하면 강서구 중에서도 화곡동이 가장 매물이 많은 걸 알 수 있다.
- yongdo 컬럼을 확인하면 경매 매물이 다세대가 가장 많다는 걸 알 수있다.
유니크 값 갯수 구하기
df.nunique()
빈도수 구하기
# addr2 의 빈도수 구하기
df["addr2"].value_counts()
# yongdo 의 빈도수 구하기
df["yongdo"].value_counts()
- 지역별로 강서구 > 관악구 > 동작구 순으로 데이터가 많다.
- 용도별로 다세대 > 아파트 > 근린상가 순으로 데이터가 많다.
IQR 을 이용하여 이상치 제거하기
# gamp 의 이상치 찾기
gamp_q1 = df["gamp"].quantile(0.25)
gamp_q3 = df["gamp"].quantile(0.75)
IQR = gamp_q3 - gamp_q1
print(gamp_q3 + 1.5*IQR) # -> 804500000.0
print(gamp_q1 - 1.5*IQR) # -> -159500000.0
# outline 보다 큰 값들을 확인한다.
large = df["gamp"] > gamp_q3 + 1.5*IQR
# outline 보다 큰 값들의 index 를 확인한다.
index_outlayer = df[large].index
# 해당 index 를 삭제한다.
df_clean = df.drop(index_outlayer)
df.shape # -> (483, 12)
df_clean.shape # -> (402, 12)- gamp 의 최솟값은 양수라서, gamp_q1 - 1.5*IQR 가 음수기 때문에 작은 값의 이상치는 제거하지 않았다.
- df_clean.shape 을 보면 row 수가 402 개라는 걸 알 수 있다. 즉 81개의 이상치가 제거 되었다!
이상치 결과 시각적으로 확인하기
이상치 제거 전 boxplot
plt.figure(figsize=(16,15))
sns.boxplot(data=df, x="addr2", y="gamp")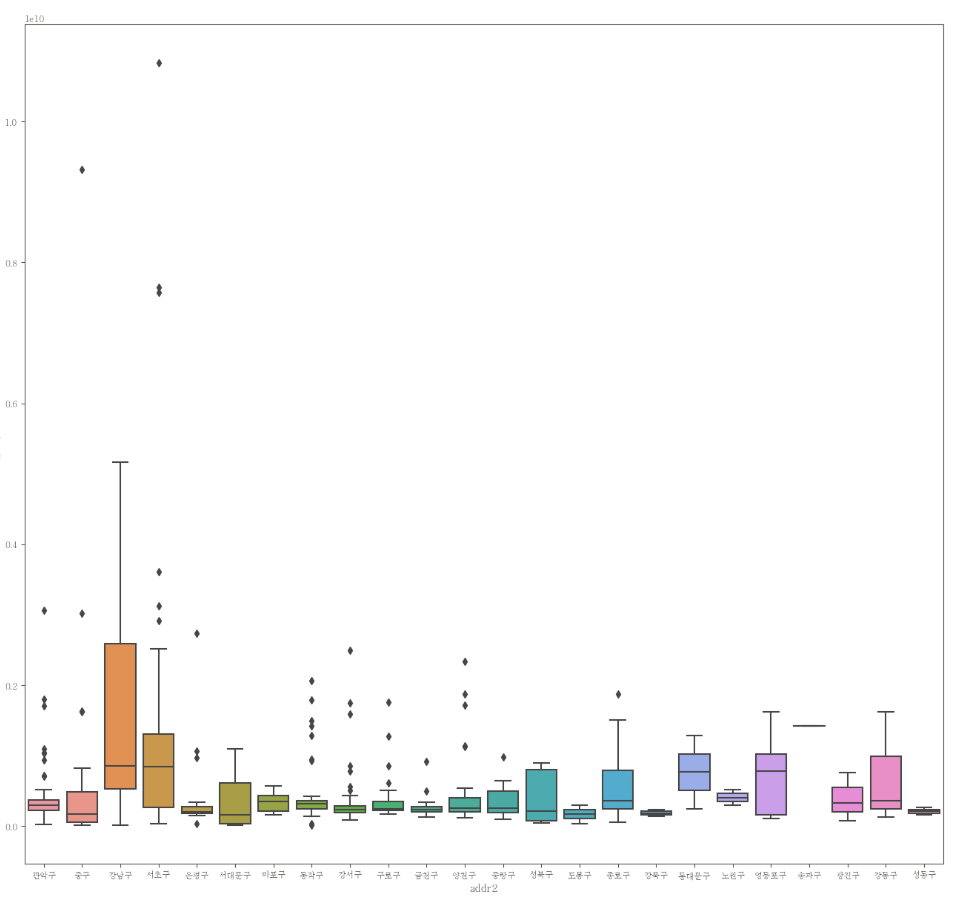
- 강남구와 서초구에 큰 값의 이상치들이 있어서 그래프가 남짝해 지는 걸 알 수 있다.
이상치 제거 후 boxplot
plt.figure(figsize=(16,15))
sns.boxplot(data=df_clean, x="addr2", y="gamp")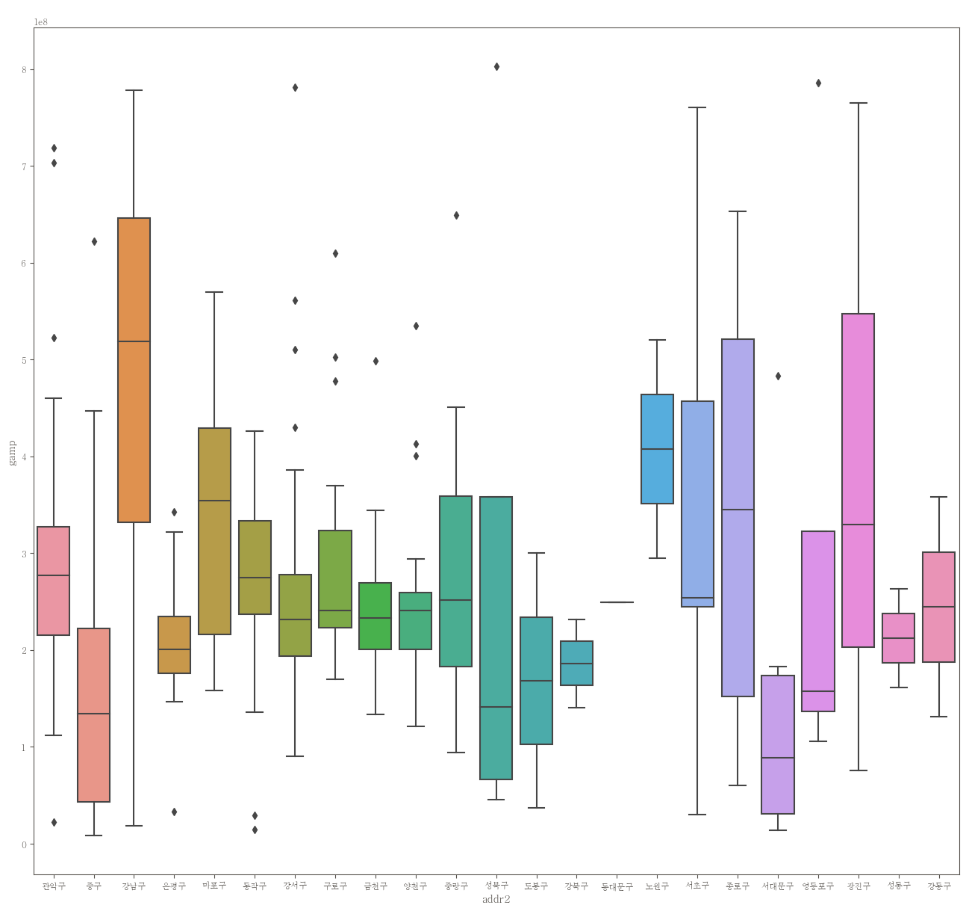
- 제거 이후의 boxplot을 확인하면 gamp 데이터의 분포를 더 잘 확인 할 수 있다.
- 강남구, 종로구, 광진구, 성북구가 gamp 분포 구간이 넓은 것을 알 수 있다.
이상치 제거 전 barplot
plt.figure(figsize=(16,15))
sns.barplot(data=df, x="addr2", y="gamp", ci=None)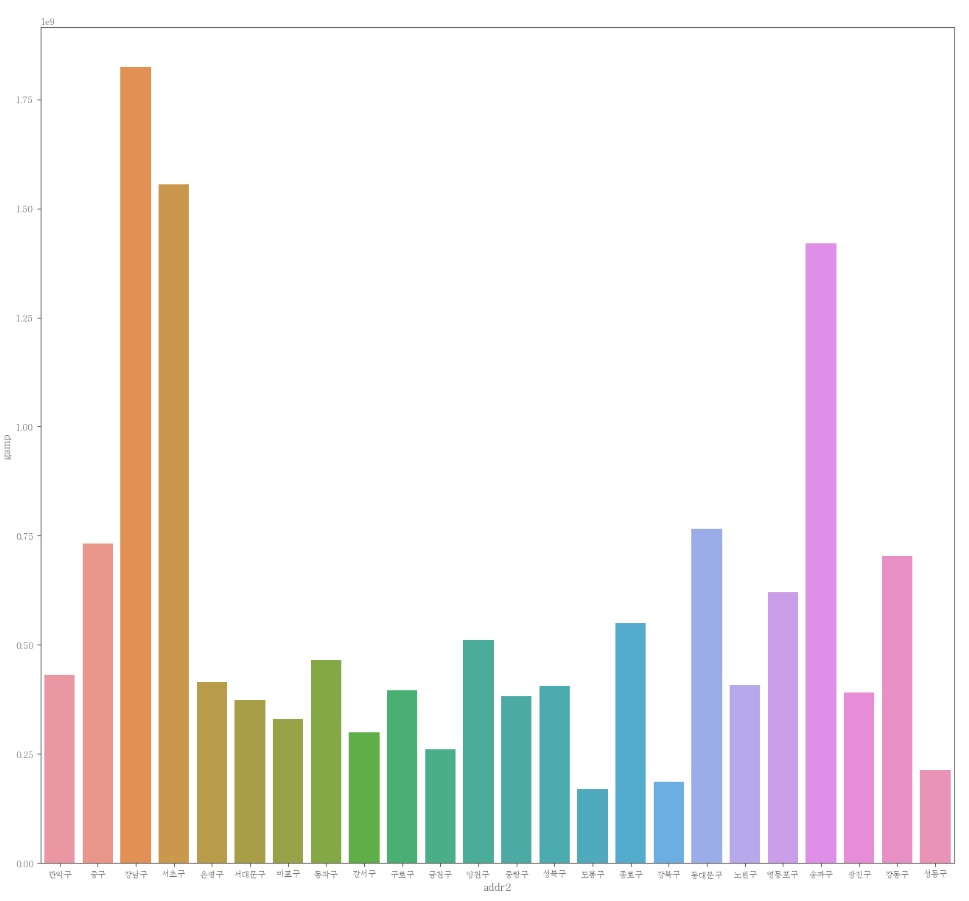
- 강남구 > 서초구 > 송파구 순으로 gamp 평균 값이 높은 걸로 보인다.
이상치 제거 후 barplot
plt.figure(figsize=(16,15))
sns.barplot(data=df_clean, x="addr2", y="gamp", ci=None)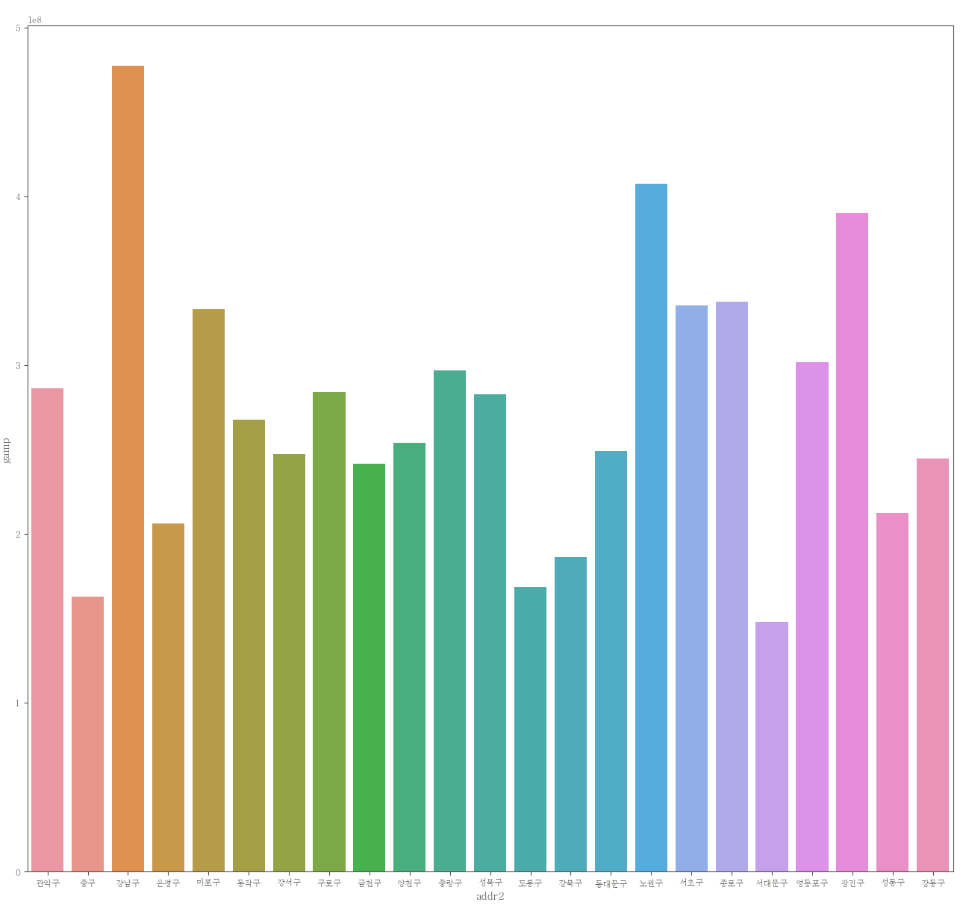
- 이상치를 제거하고 나니, 강남구 > 노원구 > 광진구 순으로 gamp 평균이 높다는 걸 확인 할 수 있다.
이상치 제거 전 stripplot
plt.figure(figsize=(12, 4))
sns.stripplot(data=df, x="addr2", y="gamp")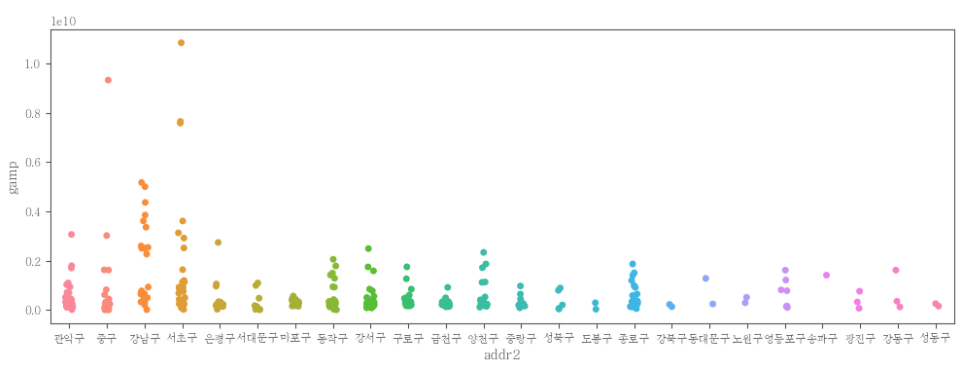
이상치 제거 후 stripplot
plt.figure(figsize=(12, 4))
sns.stripplot(data=df_clean, x="addr2", y="gamp")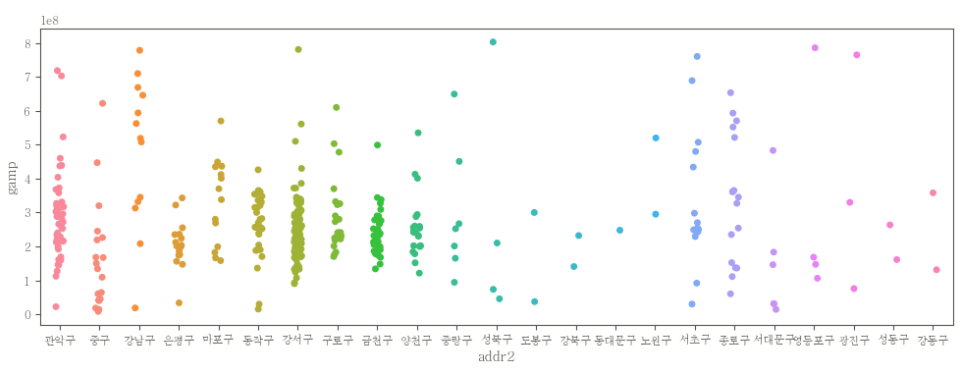
- 이상치 제거 전에는 아래쪽에 점들이 모여있었는데, 이상치 제거 후에는 전체적으로 점들이 퍼져있다.
- 이상치 제거 후 stripplot은 각 지역 별로 gamp 값들의 분포 정도를 시각화 하여 보기 좋다.
- 이상치 제거 전에는 다 적은 금액 같이 보이는게 데이터 분석에 방해가 된다.
이상치 제거 전 히스토그램 그리기
df.hist(bins=50, figsize=(16,10))
plt.show()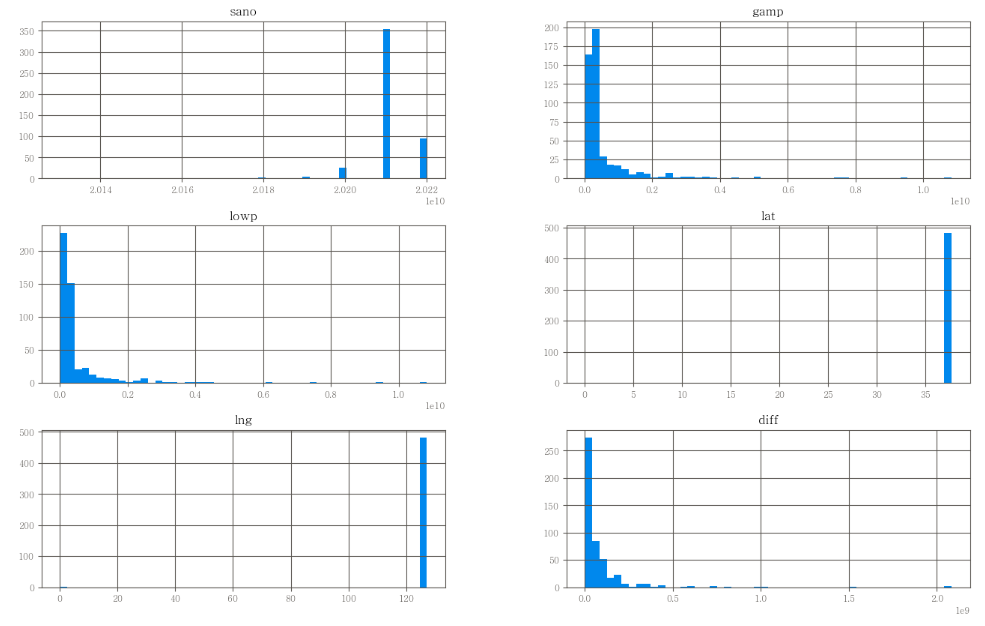
- 왼쪽으로 데이터가 너무 치우쳐져 있다.
이상치 제거 후 히스토그램 그리기
df_clean.hist(bins=50, figsize=(16,10))
plt.show()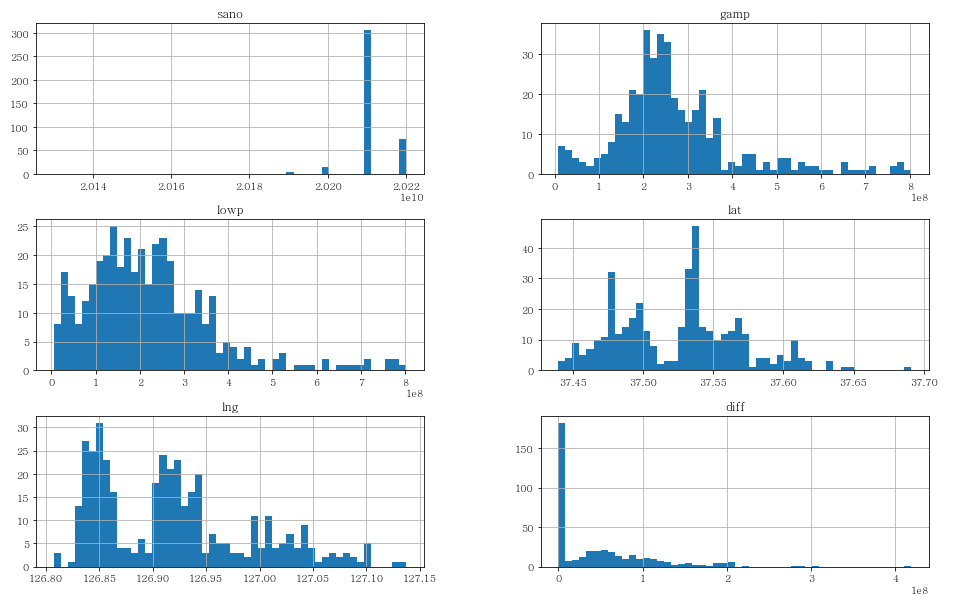
- 왜도(Skewness)가 훨씬 0에 가까워 진 모습을 볼 수 있다.
이상치 제거 전 distplot 그리기
plt.figure(figsize=(16,15))
sns.distplot(x = df["gamp"], kde=True, rug=True)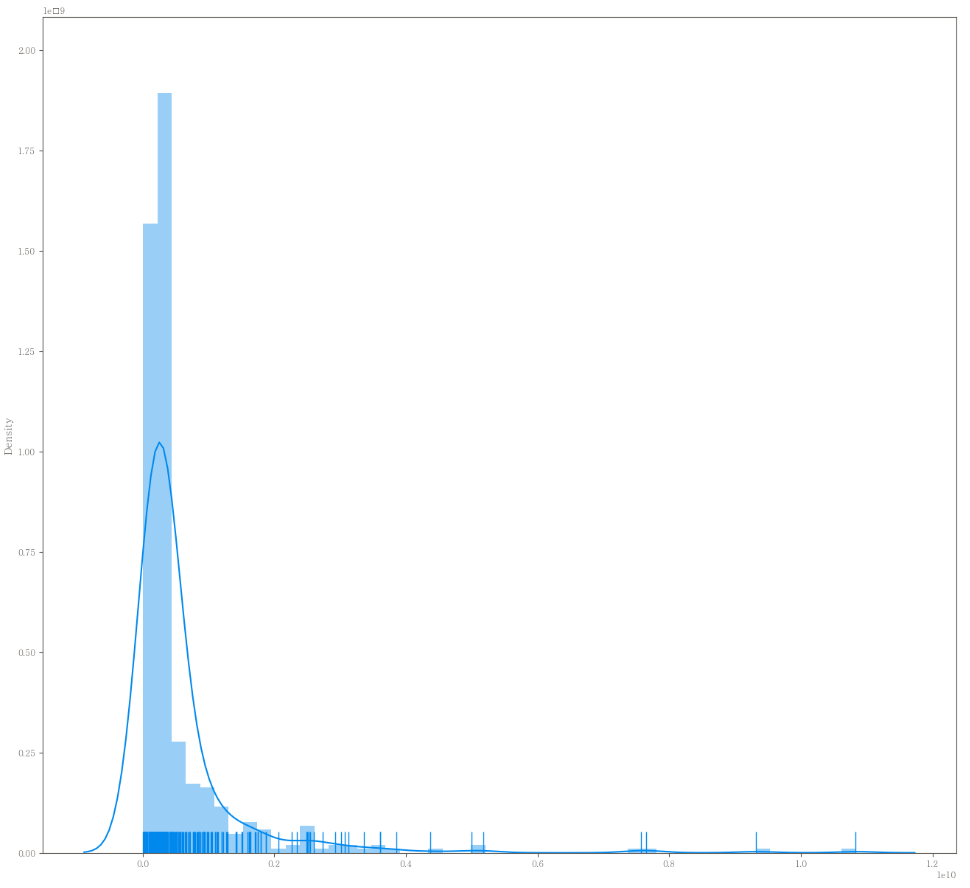
- 왼쪽으로 데이터가 너무 치우쳐져 있다.
이상치 제거 후 distplot 그리기
plt.figure(figsize=(16,15))
sns.distplot(x = df_clean["gamp"], kde=True, rug=True)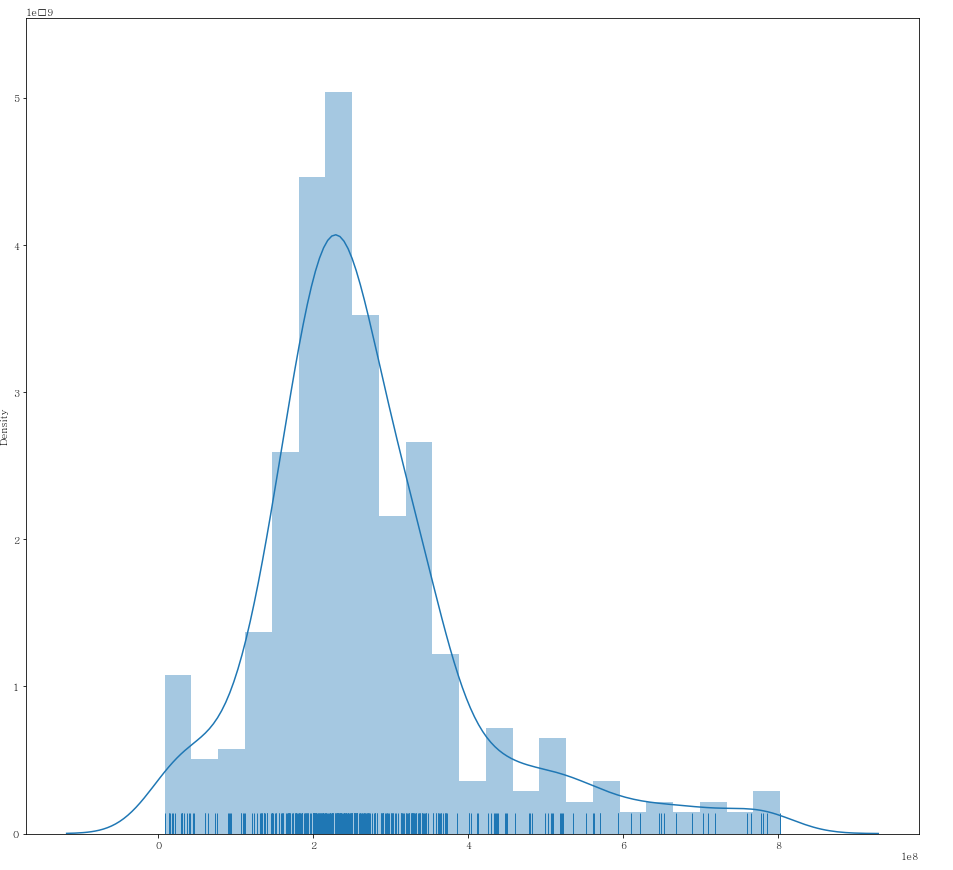
- 정규분포에 가까워 진 것을 확인 할 수 있다.
pandas profiling
!pip install pandas_profiling
from pandas_profiling import ProfileReport
# 이상치 제거 전
profile = ProfileReport(df)
profile.to_file("pandas_profile_report_auction.html")
# 이상치 제거 후
profile = ProfileReport(df_clean)
profile.to_file("pandas_profile_report_auction_clean.html")
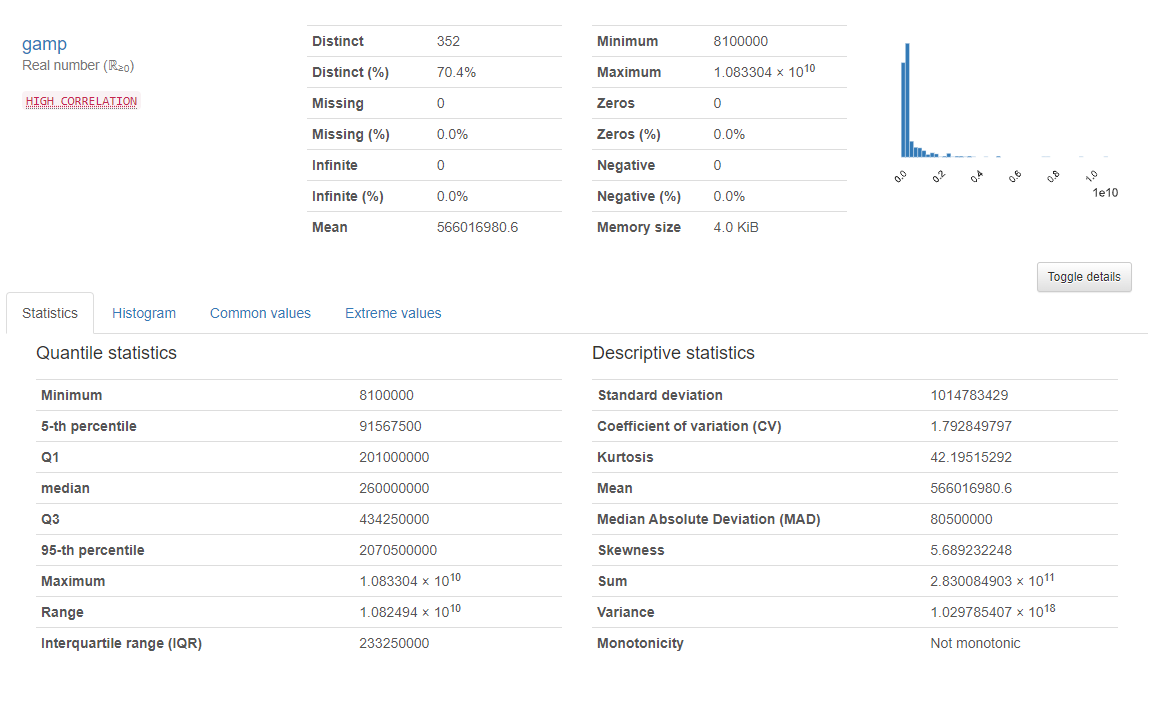
이상치 제거 전
- 왜도(Skewness) : 5.689232248
- 첨도(Kurtosis) : 42.19515292
- 평균(mean) : 566016980.6
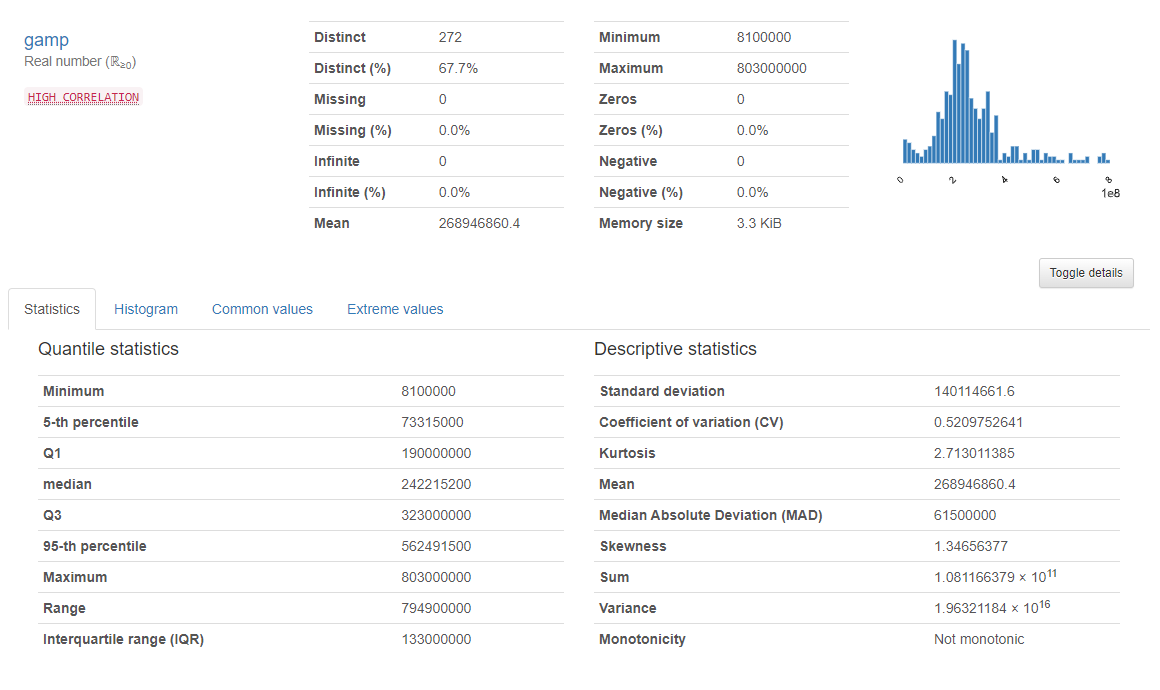
이상치 제거 전
- 왜도(Skewness) : 1.34656377
- 첨도(Kurtosis) : 2.713011385
- 평균(mean) : 268946860.4
왜도도 많이 줄고, 첨도는 기하급수적으로 줄어든 걸 볼 수 있다. 그리고 평균도 반 이하로 낮아졌다.
이상치를 제거 한 이후의 데이터 시각화 결과와 분석이 너무나 달라지는 걸 확인 할 수 있었다.
groupby 로 집계데이터 보기
# e 로 숫자 쓰여지지 않게 설정
pd.options.display.float_format = '{:.5f}'.format
df.groupby(["addr2", "addr3"]).mean()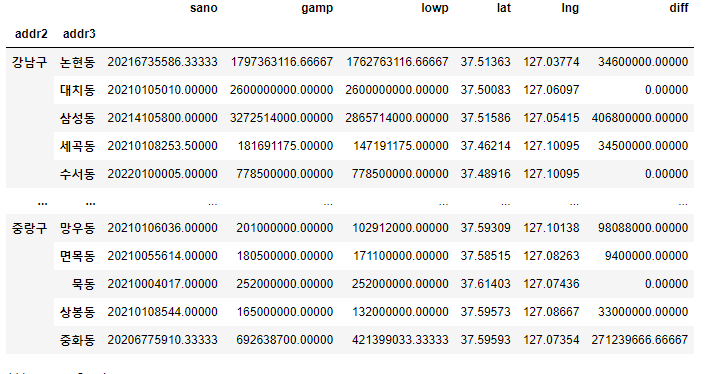
- 각 구 별로 동마다의 수치데이터를 평균낸 값이다.
groupby 로 집계데이터 일 부분만 보기
df.groupby(["yongdo"])["gamp", "lowp", "diff"].mean()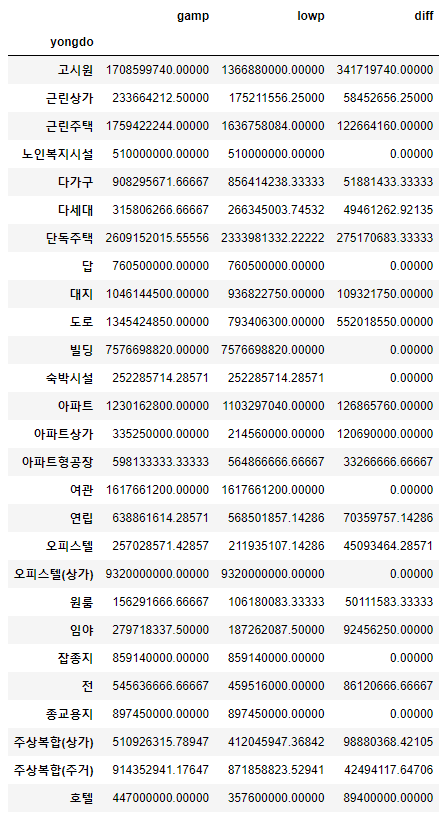
- 용도별로 감정가, 최저가, 차이 를 추출한 데이터이다.
이슈
groupby 를 했는데도 종류가 많아서 알아보기 힘든 문제가 있다.
일부데이터만 추출한 DataFrame 을 만들자!
df_temp = df[df["yongdo"].isin(["다세대","아파트","오피스텔"])]
df_temp = df_temp[df_temp["addr2"].isin(["강남구", "서초구", "관악구", "강서구", "은평구", "금천구"])]
df_temp = df_temp.reset_index(drop=True)
df_temp
# groupby
pd.options.display.float_format = '{:.5f}'.format
df_temp.groupby(["addr2"])["gamp", "lowp", "diff"].mean()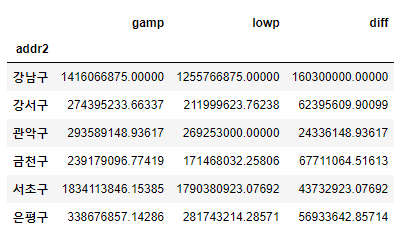
- 용도는 "다세대","아파트","오피스텔" 만 있고, addr2 는 "강남구", "서초구", "관악구", "강서구", "은평구", "금천구" 만 있는 df_temp 데이터 프레임을 만들었다.
- 데이터가 좀더 눈에 들어오는 걸 알 수 있다.
- 원하는 지역의 원하는 용도를 따로 추출하여 데이터를 분석할 수 있어서 좋다.
전체 데이터와 일부 데이터 시각화 차이 비교
지역별 가격 차이를 나타낸 barplot
# 전체
plt.figure(figsize=(16,15))
sns.barplot(data=df_clean, x="addr2", y="diff", ci=None)
# 일부
plt.figure(figsize=(16,15))
sns.barplot(data=df_temp, x="addr2", y="diff", ci=None)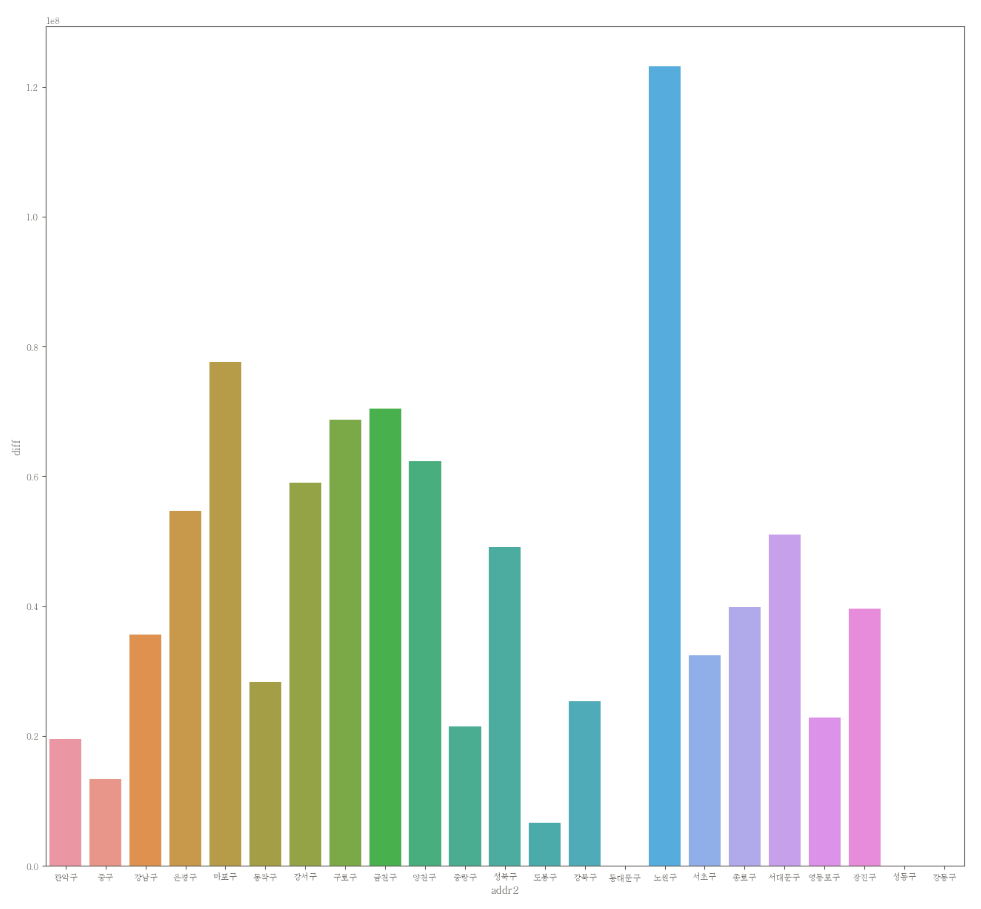
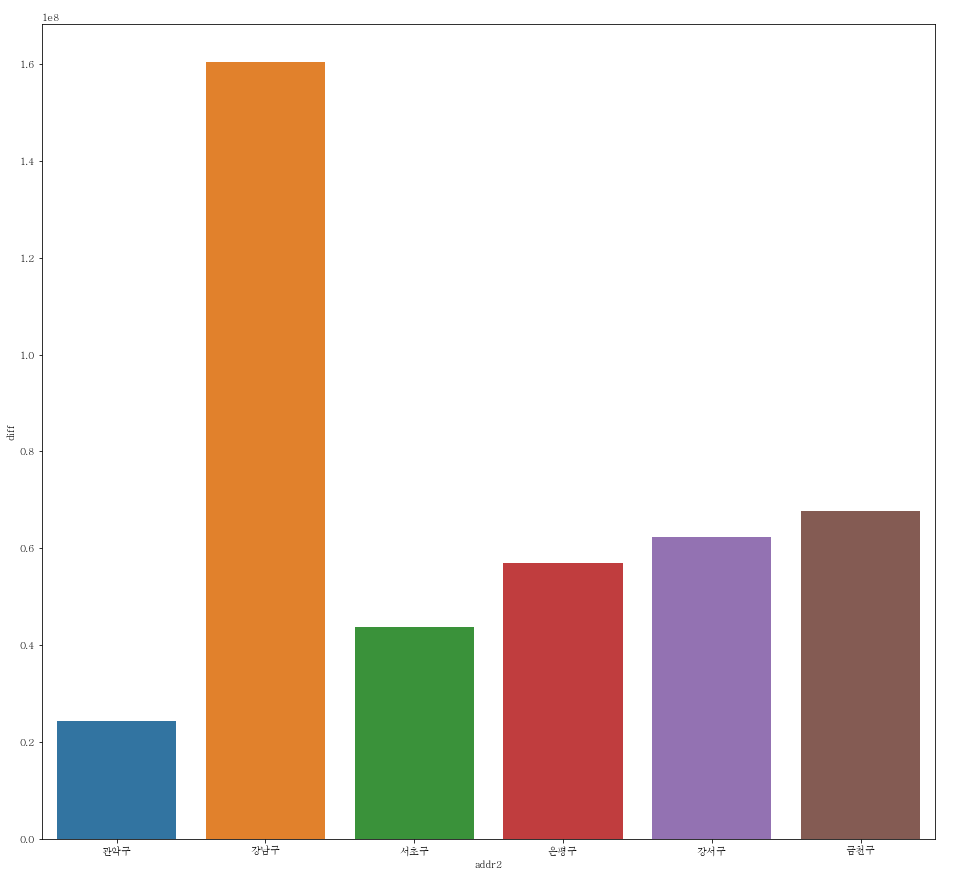
- 비교를 원하는 지역끼리 추출하여 금액 차이가 더 확실하게 와닿는다.
지역별 용도를 나타낸 countplot
# 전체
plt.figure(figsize=(16,15))
sns.countplot(data=df, x="addr2", hue="yongdo")
# 일부
plt.figure(figsize=(16,15))
sns.countplot(data=df_temp, x="addr2", hue="yongdo")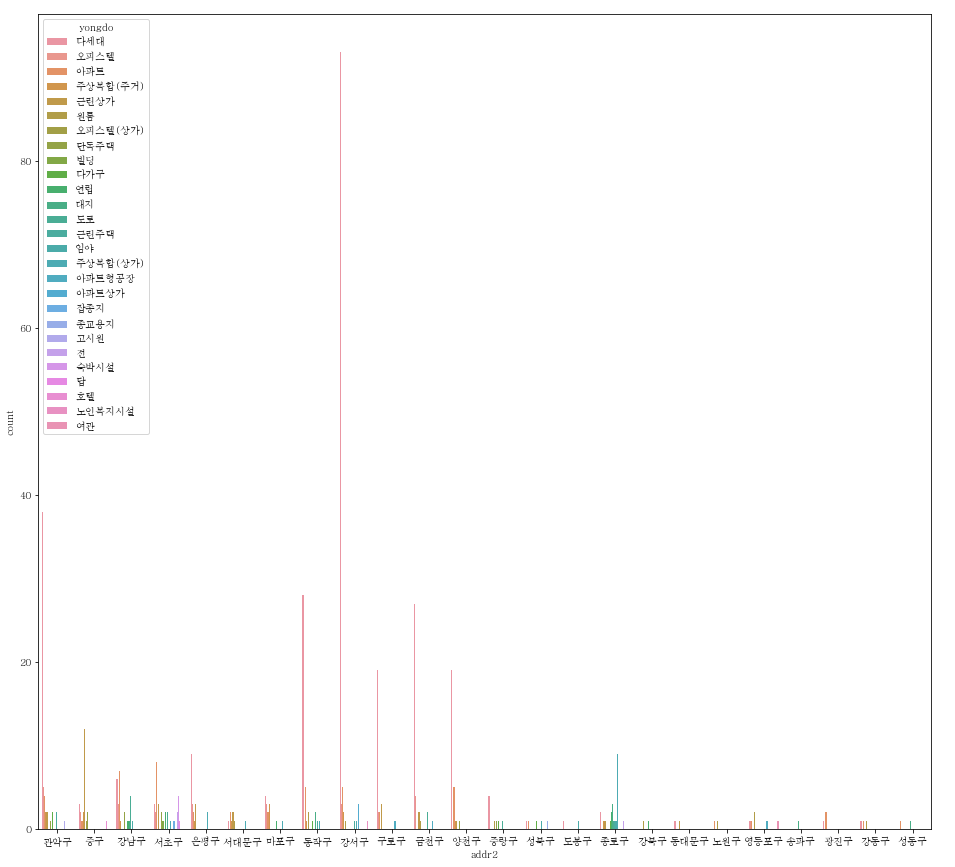
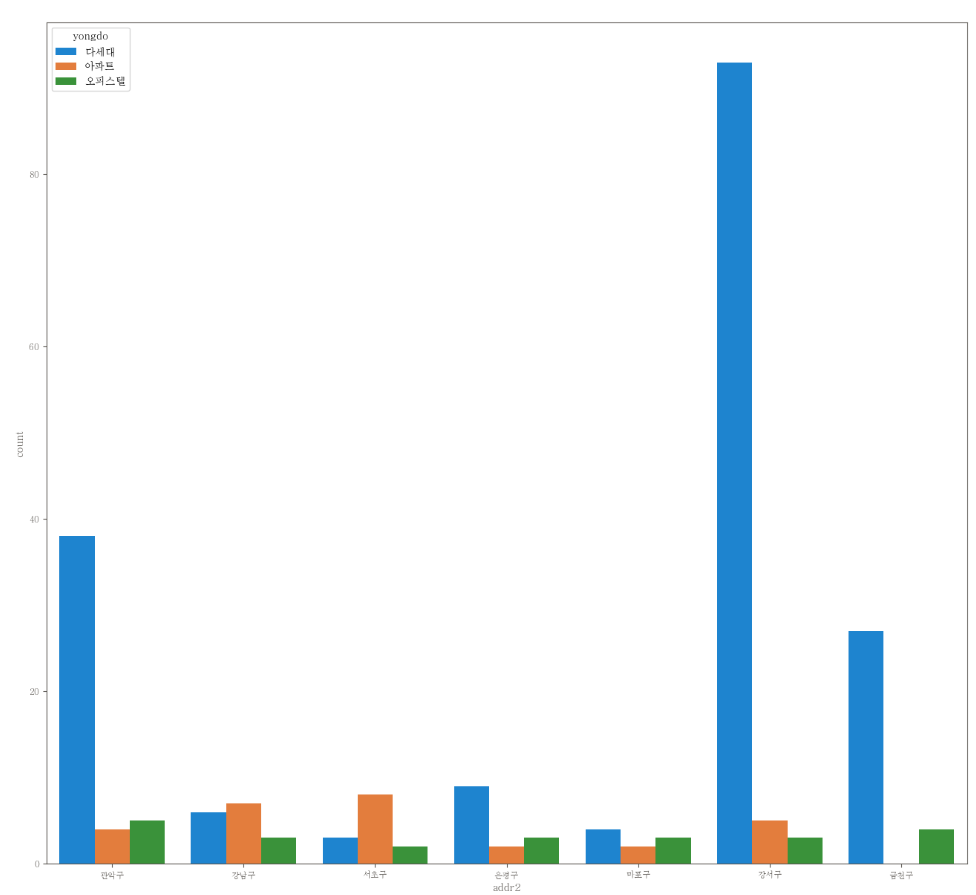
-
전체에서는 각 지역별 용도를 알고 싶지만 용도가 너무 종류가 많아서 확인하기 쉽지 않다.
-
원하는 지역에서 비교하고 싶은 용도만을 비교할 수 있다.
-
대체로 다세대의 비율이 압도적으로 높다.
느낀점
분석관련 느낀점
- 이상치 제거가 데이터 분석에 중요하다.
- 데이터 종류가 너무 많을 경우 일부만 추출하여 시각화 하면 도움이 된다.
EDA 결과 느낀점
- 확실히 강남이 비싸고, 비싼만큼 감정가와 최저가의 차이도 큰편이다.
- 경매로 나오는 매물은 다세대가 많다.

열심히 사는 중