여기서 데이터 수집을 할거다.
https://opengov.seoul.go.kr/civilappeal/list
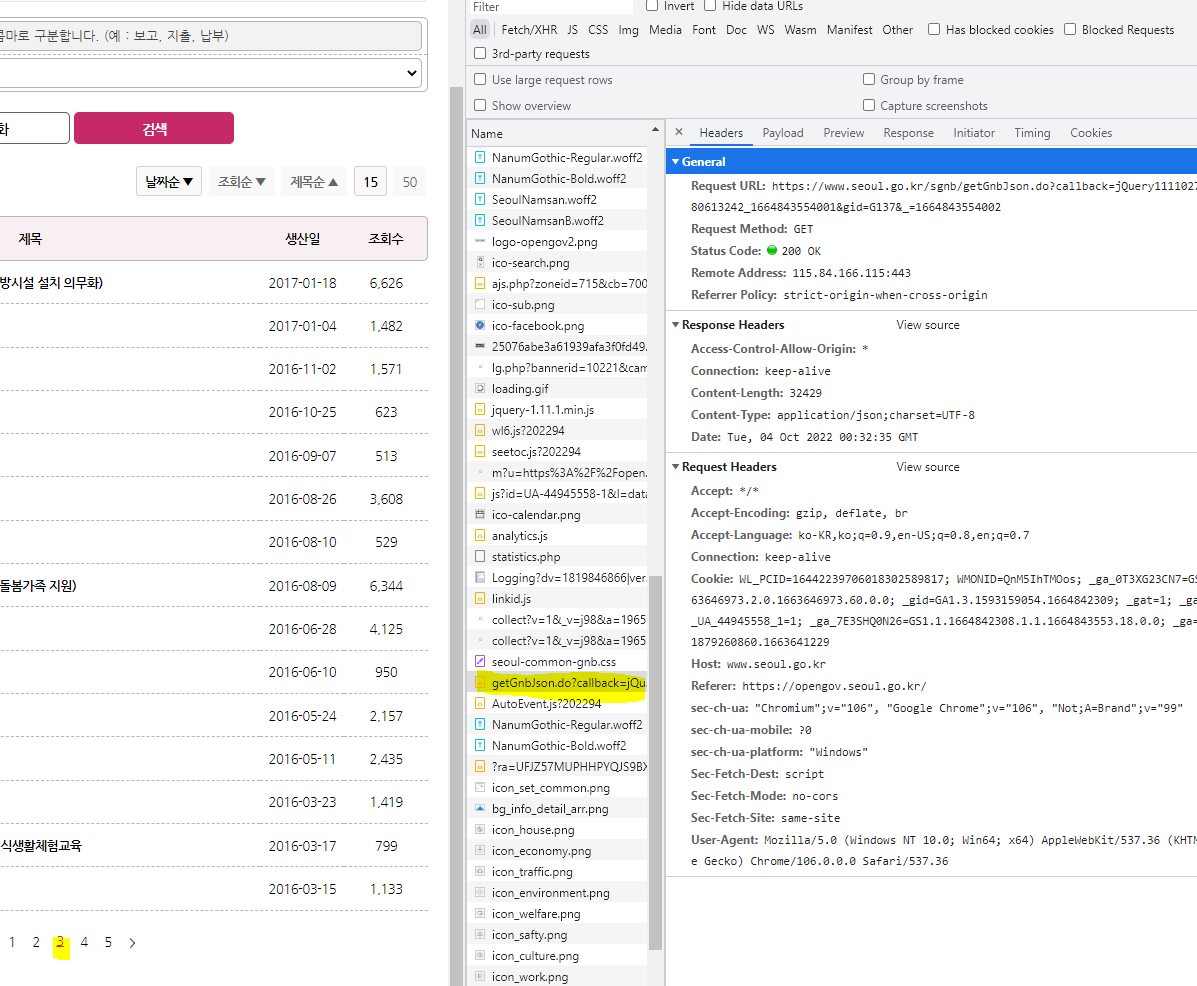
링크를 추출 할 수 있다.
https://www.seoul.go.kr/sgnb/getGnbJson.do?callback=jQuery111102710161880613242_1664843554001&gid=G137&_=1664843554002
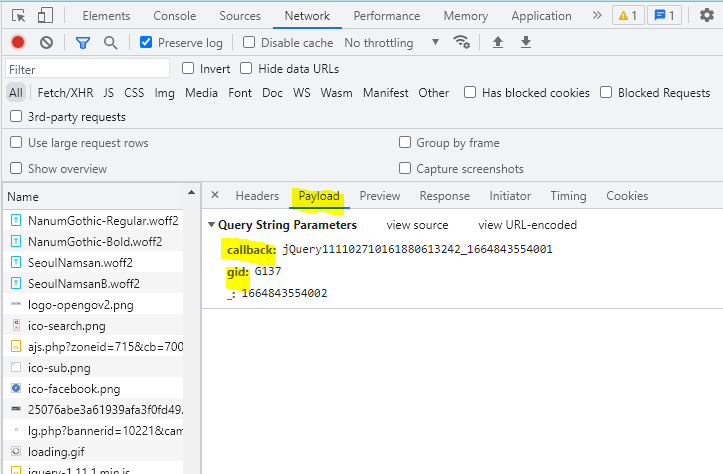
payload 페이지에서 보이는 데이터들을 지워주고 url 을 보내도 된다.
https://www.seoul.go.kr/sgnb/getGnbJson.do
with urlopen('')
as response:
soup = BeautifulSoup(response, 'html.parse')with 구문은 사용이 끝나면 메모리에서 지워주는 기능이다. 파일을 불러 올 때는 with를 사용한다.
-
tqdm 은 진행상태를 표시해준다.
-
robots.txt 알아보기
네이버 증권 게시판에 글을 쓰면
데이터베이스권은 네이버에 있으며 저작권은 글쓴이에게 있습니다.
수도코드 작성해보기!!
중요하다.
**120 주요질문의 특정 페이지 목록을 수집할 때!**
1. page_no 마다 url 이 변경되게 f-string 을 사용해 만든다.
2. requests 를 사용해서 요청을 보내고 응답을 받는다.
3. pd.read_html 을 사용해서 table tag 로 게시물을 읽어온다.
4. 3번 결과에서 0번 인덱스를 가져와 데이터 프레임으로 목록의 내용을 만든다.
5. html tag 를 parsing 할 수 있게 bs 형테로 만든다.
6. 목록 안에 있는 a tag 를 찾는다.
7. a tag 안에서 string 을 분리해서 내용번호만 리스트 형태로 만든다.
8. 4의 결과에 "내용번호"라는 컬럼을 만들고 a tag 의 리스트를 추가한다.
라이브러리 설정
import pandas as pd
import numpy as np
import requests
from bs4 import BeautifulSoup as bs
import time
# 끝 페이지가 어디인지 모르기 때문에 tqdm 을 쓸 수 없다.
# from tqdm import tqdmread_html 로 불러오기
# 120 다산 콜센터의 첫 페이지를 먼저 불러와 크롤링할 내용을 봅니다.
base_url = "https://opengov.seoul.go.kr/civilappeal/list?items_per_page=50&page=1"
# 그냥 하면 한글이 깨지기 때문에 encoding 을 해줘야 한다.
table = pd.read_html(base_url, encoding = "utf-8")
table[0]
여기까지는 목록만 불러 올 수 있다. 근데 상세정보 링크가 없다!
a tag 의 링크 수집하기
태이블로 읽어 올 수 없는 데이터라서 requests 요청을 보내야 한다.
response = requests.get(base_url)
# html 태그를 파싱해 올 수 있도록 합니다.
html = bs(response.text)
# a 태그
a_list = html.select("td.data-title.aLeft > a")
# 데이터 하나로 원하는 데이터를 추출 할 수 있는지 확인 먼저 해보자. 유효한 코드일 때 다음으로 넘어가기
a_list[1]["href"].split("/")[-1] # -> '25670204'
# href 의 뒤 숫자만 모아서 list 로 만든다.
a_link_no = []
for a_tag in a_list:
a_link_no.append(a_tag["href"].split("/")[-1])
# 목록 테이블에 추가해준다.
table[0]["내용번호"] = a_link_no
전체 함수로 만들어보기
def get_one_page(page_no):
# 1. page_no 마다 url 이 변경되게 f-string 을 사용해 만든다.
base_url = f"https://opengov.seoul.go.kr/civilappeal/list?items_per_page=50&page={page_no}"
# 2. requests 를 사용해서 요청을 보내고 응답을 받는다.
response = requests.get(base_url)
# 3. pd.read_html 을 사용해서 table tag 로 게시물을 읽어온다.
table = pd.read_html(base_url, encoding = "utf-8")
# 4. 3번 결과에서 0번 인덱스를 가져와 데이터 프레임으로 목록의 내용을 만든다.
df = table[0]
# 5. html tag 를 parsing 할 수 있게 bs 형테로 만든다.
html = bs(response.text)
# 6. 목록 안에 있는 a tag 를 찾는다.
a_list = html.select("td.data-title.aLeft > a")
# 7. a tag 안에서 string 을 분리해서 내용번호만 리스트 형태로 만든다.
a_link_no = []
for a_tag in a_list:
a_link_no.append(a_tag["href"].split("/")[-1])
# 8. 4의 결과에 "내용번호"라는 컬럼을 만들고 a tag 의 리스트를 추가한다.
df["내용번호"] = a_link_no
## 7, 8번을 코드를 작성 할 수 있다.
df["내용번호"] = [a_tag["href"].split("/")[-1] for a_tag in a_list]
return df없는 페이지를 요청하면 오류가 난다.
# 없는 페이지도 확인
get_one_page(page_no=500)
table[0]가 데이터가 없어서 오류가 난다.
html 에 table 이 없기 때문에 parsing 할 수 없다.
오류처리
try:
어쩌구
except:
return 어쩌구
# 아니면 오류를 보낼 수도있다.
raise Exception(f"{page_no}페이지를 찾을 수 없습니다.")중간에 오류가 발생해도 다음 코드를 실행해야 할 때는 예외 메시지만 출력하도록 하는 방법도 있다.
예외처리
# 테이블 길이로 문제가 되는 부분을 확인 할 수도 있다.
if table[0].shape[0] == 0:
return f"{page_no}페이지를 찾을 수 없습니다."원하지 않는 상황이 발생했을 때를 체크해서 return 해준다.
게시물이 없을 때 까지 수집하기
page_no = 1
table_list = []
while True:
print(page_no, end=",")
df_temp = get_one_page(page_no)
if type(df_temp) == str :
print("수집이 완료되었습니다.")
break
table_list.append(df_temp)
page_no += 1
time.sleep(0.01)return type 으로 마지막 페이지를 확인 할 수 있다.
전치행렬 transpose
table 을 읽어 온 이후 원하는 형태로 변형해서 dataFrame 으로 만들 수 있다.
url = "https://opengov.seoul.go.kr/civilappeal/view/?nid=23194045"
response = requests.get(url)
table = pd.read_html(response.text)[-1]
table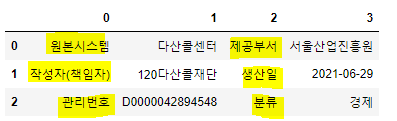
웹에서 제공하는 table 은 이런식으로 데이터를 제공하고 있다.
데이터 분석을 위해서 0,2 컬럼의 series 가 컬럼이 되는게 좋아서 전치를 해서 dataFrame 을 만들려고 한다.
컬럼으로 해주고 싶은 열을 index 로 지정해준다.
# 0을 index 로 만든다.
table[[0,1]].set_index(0)
# 행과 열을 바꿔준다.
tb01 = table[[0,1]].set_index(0).T
tb01
# 2를 index 로 만든다.
table[[2,3]].set_index(2)
# 행과 열을 바꿔준다.
tb02 = table[[2,3]].set_index(2).T
tb02
# 두 DataFrame 을 합치기 위해서 index를 동일하게 맞춰준다.
tb02.index = tb01.index
tb = pd.concat([tb01, tb02], axis = 1)
tb
