22.11.14 701 실습
히스토그램
_ = test.hist(figsize=(20,16), bins=50)
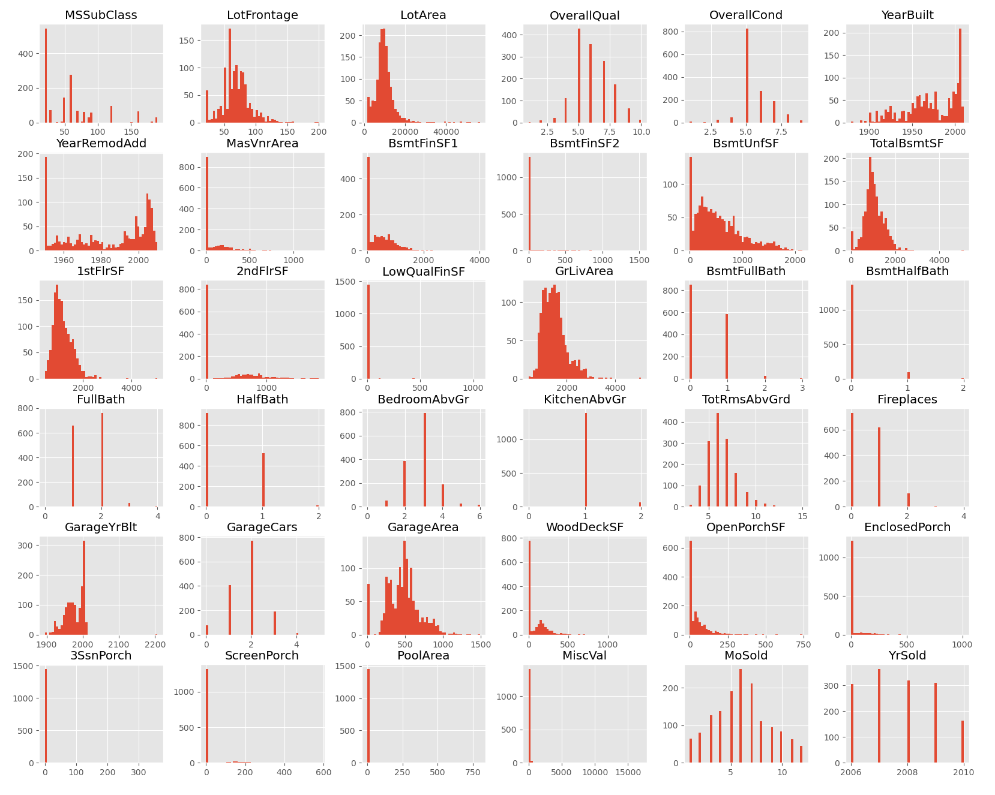
- histogram 의 목적
- 수치데이터의 분포 확인
- 왜도 -> 너무 한쪽이 치우쳐져 있지는 않은지 확인
- 첨도 -> 한쪽에 데이터가 너무 몰려있지 않는지 확인
- 막대가 떨어져 있다면 수치 데이터가 아니라 범주형 데이터가 아닌지 확인
이상치
_ = sns.scatterplot(data=train, x=train.index, y="SalePrice")
plt.axhline(500000, c="k", ls=":")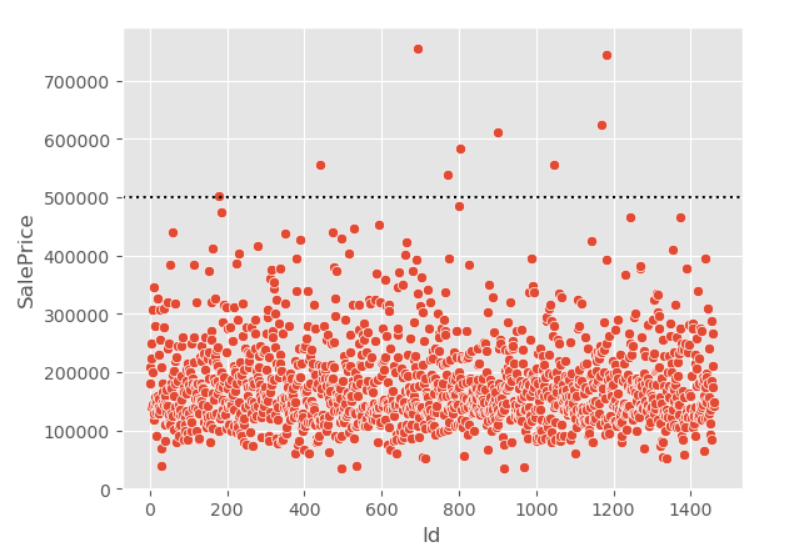
- 이상치는 어떻게 처리 해야 할까?
- 이상치를 평균이나 중앙값으로 대체하면 데이터에 왜곡이 될 수 있다.
- 이상치가 이상치인 이유가 있을 수도 있다.
희소값
- 범주형 데이터 중에서 빈도가 적게 등장하는 값이 희소값이다.
- One-Hot-Encoding 을 했을 때 희소값도 피처로 만들어 주면 연산에 시간이 더 오래 걸릴 수도 있다.
- 오버피팅(과대적합)의 문제도 있을 수 있다.
- 희소값은 어떻게 처리를 할 수 있을까??
- 기타로 묶는 방법, 아예 결측치로 처리하기.
# 범주형 데이터중에 가짓수가 많은것들 확인
train.select_dtypes(include="object").nunique().nlargest(10)
# value_counts 로 각 얼마나 있는지 확인
train["Neighborhood"].value_counts()피쳐 스케일링
- 트리계열 모델에서는 사실 필요하지는 않다.
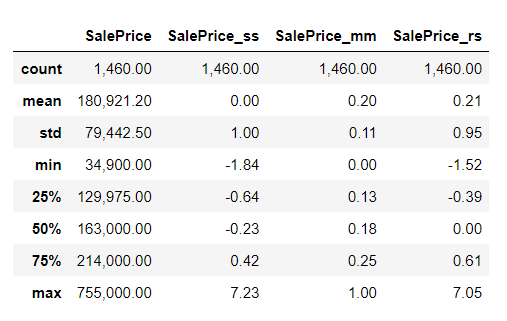
inverse_transform으로 원래 값으로 되돌릴 수 있다.
트랜스폼
- 트리계열에서도 트랜스폼을 해주면 성능이 좋아진다.
- 너무 한쪽에 몰려있거나 치우쳐져 있을 때보다 고르게 분포되어 있다면 데이터의 특성을 더 고르게 학습 할 수 있기 때문이다.
- 만약 음수값이 너무 크다면, 최솟값이 +1 이 되도록 값을 더해준다. 그다음에 로그변환 해준다.
그렇지 않으면 numpy 에서 결측처리해버린다. - np.exp로 원래 값으로 되돌릴 수 있다.
이산화
- 연속된 수치 데이터를 구간화 하는 방법
- 이 방법음 RFM 기법에서도 종종 사용되는 방법으로 비즈니스 분석에서 다룰 예정이다.
- Recency, Rrequency, Monetary => 고객이 얼마나 최근에, 자주, 많이 구매했는지를 분석하는 기법
- 머신러닝 알고리즘에 힌트를 줄 수 있다.
- 트리모델이라면 너무 잘게 데이터를 나누지 않아서 일반화 하는데 도움이 될 수 있다. (즉 나누는 기준이 중요!)
- EDA를 통해 어떻게 나누는게 도움이 될지 예측한다.
오히려 잘못나누면 성능이 떨어 질 수 있다.
pd.cut: 절대평가 같다. 점수기준으로 나누는 것.pd.qcut: 상대평가 같다. 분포기준으로 나누는 것.
인코딩
LabelEncoder, OrdinalEncoder 의 차이는?
- Ordinal Encoding은 Label Encoding과 달리 변수에 순서를 고려한다는 점에서 큰 차이를 갖는다. Label Encoding이 알파벳 순서 혹은 데이터셋에 등장하는 순서대로 매핑하는 것과 달리 Oridnal Encoding은 Label 변수의 순서 정보를 사용자가 지정해서 담을 수 있다.
- LabelEncoder 입력이 1차원 y 값, OrdinalEncoder 입력이 2차원 X값이다.
- 원핫인코딩 했을 때는 train, test 피처의 수가 같은지 꼭 확인해야한다.
Q.
y값, X값으로 다른게 뭔지 이해가 안갑니다,,A.
X => 독립변수, 시험의 문제, 2차원 array 형태, 학습할 피처
y => label, target, 정답, 시험의 답안, 1차원 벡터X는 feature, 독립변수, 2차원 array 형태, 학습할 피처, 예) 시험의 문제
y는 label, 종속변수, target, 정답, 1차원 벡터, 예) 시험의 정답
X는 보통 2차원으로 대문자로 표기하고 y는 소문자로 표기하는것이 꼭 그렇게 써야된다는 아니지만 관례처럼 사용하고 있습니다.
다항식 전개
- 구분이 잘 안되는 값에 차이를 보고싶어서 제곱을 해주는 방식이다.
Q.
구분이 잘 안 되는 값에 대해 power transform 을 해주기도 하는데 반대로 너무 차이가 많이 나는 값을 줄일 때 사용할 수 있는 방법은?
A.
꼭 정답이 있다기 보다는 EDA를 해보고 어떤 스케일링을 하면 머신러닝 모델이 값을 학습하는데 도움이 될지 고민해 보면 좋다.
root, log transform 도 해볼 수 있지만 변환이 정답은 아니다. 성능이 올라가고 안 올라가고는 EDA 등을 통해 확인해 보고 왜 점수가 오르고 내리는지 확인해 보는 습관을 길러보는게 좋다.
특성 선택
value_counts(1): 갯수가 아닌 비율을 보여준다.- 너무 치우쳐져 있는 값들은 예측에 도움이 안 될 수 있기 때문에 어떤 값이 얼마나 치우쳐져 있는지 파악해보자.
- 이런 값들은 드랍을 하고 사용하지 않는 것도 방법이다.
for col in train.select_dtypes(include="O").columns:
print("-----",col,"--------")
print(train[col].value_counts(1) * 100)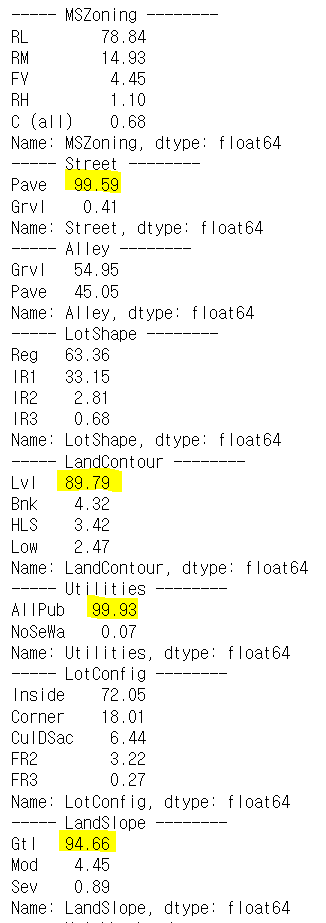
File vs SQL
- 아카이빙할 데이터는 대부분 파일로 저장
- 실시간으로 보여주어야 하는 현재 status 값만 DB에 저장해서 사용
지표
- DAU : Daily Active User 하루에 몇 명이 접속하는지(혹은 로그인 하는지)
- AARRR, Funnel : 분석을 통해 얼마나 많은 사람이 와서 물건을 살펴보고 거기서 회원가입 구매전환 친구 추천 혹은 재구매로 이어지는지
- Churn : 얼마나 사람들이 어느 페이지에서 이탈하는지? 퍼널, AARRR 과 함께 볼 수 있는 지표
- 702
정답값 보기
- displot
_ = sns.displot(data=df, x="SalePrice", aspect=3, rug=True, kde=True)- aspect 는 너비, 가로 길이를 의미한다.
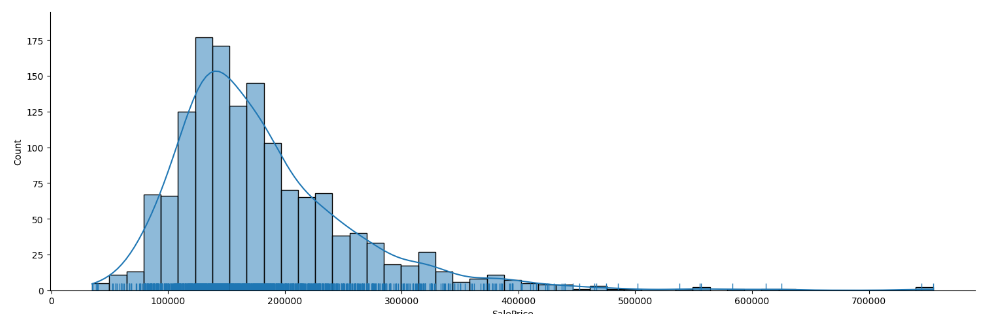
- aspect 는 너비, 가로 길이를 의미한다.
- histplot
_ = sns.histplot(data=df, x="SalePrice", bins=50, kde=True)
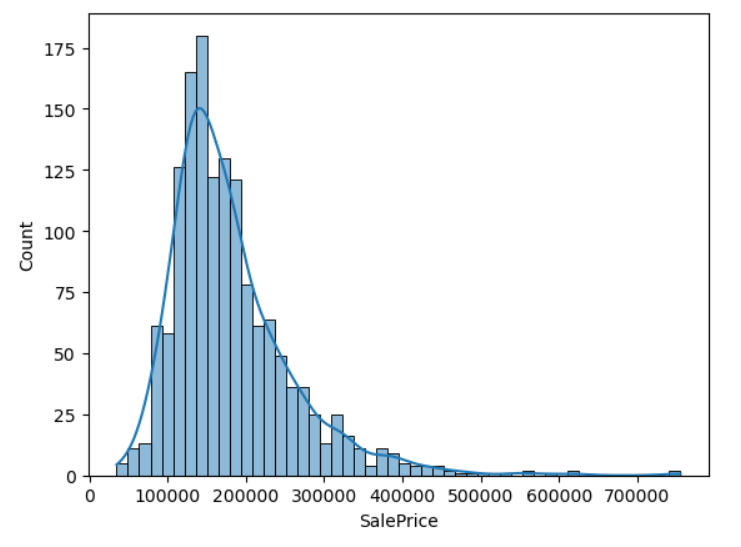
- kdeplot
_ = sns.kdeplot(data=df, x="SalePrice", shade="fill")
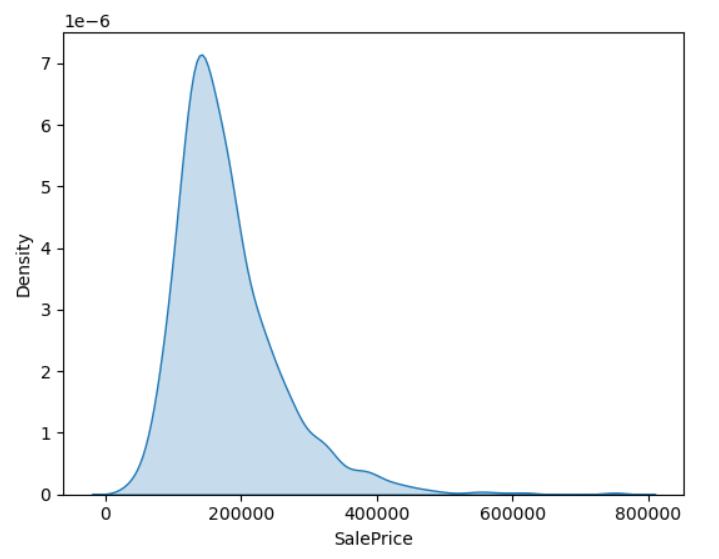
print("왜도(Skewness):", train["SalePrice"].skew())
print("첨도(Kurtosis):", train["SalePrice"].kurtosis())
>>> 왜도(Skewness): 1.8828757597682129
>>> 첨도(Kurtosis): 6.536281860064529왜도
- 변수의 확률 분포 비대칭성을 나타내는 지표
- 왜도가 음수일 경우 오른쪽에 더 많이 분포한다.
- 왜도가 양수일 때는 자료가 왼쪽에 더 많이 분포한다.
- 평균과 중앙값이 같으면 왜도는 0이 된다.
첨도
- 확률분포의 뾰족한 정도를 나타내는 지표
- Fisher의 정의를 사용
- 첨도값(K)이 0에 가까우면 산포도가 정규분포에 가깝다.
- 0보다 작을 경우에는(K<0) 정규분포보다 더 완만하게 납작한 분포로 판단할 수 있으며,
- 첨도값이 0보다 큰 양수이면(K>0) 산포는 정규분포보다 더 뾰족한 분포로 생각할 수 있다.
log 트랜스폼을 한 후 결과를 보자
# log 변환
train["SalePrice_log1p"] = np.log1p(train["SalePrice"])
print("왜도(Skewness):", np.log1p(train["SalePrice"]).skew())
print("첨도(Kurtosis):", np.log1p(train["SalePrice"]).kurtosis())
>>> 왜도(Skewness): 0.12134661989685333
>>> 첨도(Kurtosis): 0.809519155707878- 시각화도
fig, axes = plt.subplots(2, 2, figsize=(18,14))
_ = sns.kdeplot(data=train, x=train["SalePrice"], shade="fill", ax=axes[0][0]).set_title("SalePrice")
_ = sns.kdeplot(data=train, x=np.log1p(train["SalePrice"]), shade="fill", ax=axes[0][1]).set_title("SalePrice_log")
_ = sns.histplot(data=train, x=train["SalePrice"], kde=True, ax=axes[1][0]).set_title("SalePrice")
_ = sns.histplot(data=train, x=np.log1p(train["SalePrice"]), kde=True, ax=axes[1][1]).set_title("SalePrice_log")
plt.show()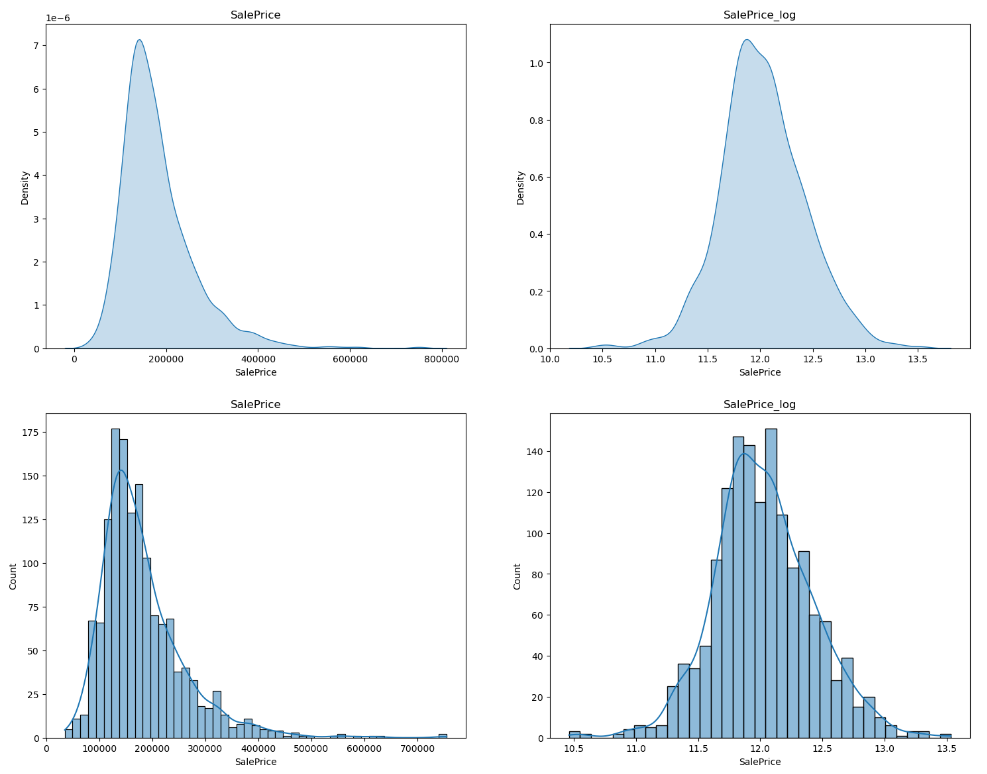
nlargest
nlargest(n=5, columns=None, keep='first')
- n : Number of rows to return. 출력할 행의 수
- columns : label or list of labels. 정렬의 기준이 되는 열
- Column label(s) to order by.
- keep : {‘first’, ‘last’, ‘all’}, default ‘first’. 동일한 값일 경우 어느 행을 출력해야 할지 정하기.
- Where there are duplicate values:
first: prioritize the first occurrence(s)last: prioritize the last occurrence(s)all: do not drop any duplicates, even it means selecting more than n items.
heatmap 의 mask 를 그리는 두가지 방법
# 1
mask = np.zeros_like(df.corr())
mask[np.triu_indices_from(mask)] = True
# 2
mask = np.triu(np.ones_like(df.corr()))최빈값으로 결측치 채우기
# 내가 한 방법
fill_mode = ['MSZoning', 'KitchenQual', 'Exterior1st', 'Exterior2nd', 'SaleType', 'Functional']
print(df[fill_mode].isnull().sum())
print(df[fill_mode].describe().T["top"])
df[fill_mode] = df[fill_mode].fillna(df[fill_mode].describe().T["top"])
print(df[fill_mode].isnull().sum())
# 강사님 방법
print(df[fill_mode].isnull().sum())
df[fill_mode] = df[fill_mode].fillna(df[fill_mode].mode().loc[0])
print(df[fill_mode].isnull().sum())아래는 다 같은 값이다.
df[fill_median].mode().loc[0]
df[fill_median].describe().loc["top"]
df[fill_median].describe().T["top"]- loc 에 대해서 내가 잘 몰라서 T 를 써서 값을 가져온듯하다.
데이터타입 바꾸기
- 수치형 데이터 중 카테고리형 변수를 Object 타입으로 변경한다. One-Hot-Encoding 을 하기 위해서!!
num_to_str_col = ["MSSubClass", "OverallCond", "YrSold", "MoSold"]
df[num_to_str_col].nunique()
df[num_to_str_col] = df[num_to_str_col].astype(str)
df[num_to_str_col].dtypes
열심히 사는 중