데이터 분석 - 정규 분포 활용
데이터 분석 정규 분포 활용
참고
비대칭(skewed) 데이터를 처리하는 3가지 방법 / Skewed Data
[ML] 데이터 스케일링 (Data Scaling) 이란?
[sklearn] 데이터 전처리 - 피처 스케일링 & 정규화
Pandas에서 데이터 정규화 하기
Why Data Normalization is necessary for Machine Learning models
머신 러닝에서 데이터 정규화가 필요한 이유
- 정규화는 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 개념이다.
- 머신 러닝에서 데이터 정규화의 목표는 피처 값 범위의 차이를 왜곡하지 않고 데이터 세트의 숫자 열 값을 공통 척도로 변경하는 것
- 피처의 범위가 다른 경우에 정규화가 필요하다.
### 예시
데이터셋에서 연령,소득범위 피처가 있을 때,
연령 범위는 0–100이고 소득 범위는 0–20,000 이상이다.
소득은 나이보다 약 1,000배 많고 범위는 20,000-500,000가 된다.
따라서 이 두 기능은 매우 다른 범위에 있고 소득이 몇배나 큰 수치이다.
**그런데 이것이 변수로서 소득이 더 중요하다는 것을 의미하지는 않는다.**
하지만, 소득의 값이 크기 때문에
소득이 인해 결과에 본질적으로 더 많은 영향을 미치게된다.
-> 이런경우 정규화가 필요하다. - 즉, 모든 머신 러닝 수행 시에 필요한게 아니다.
피처의 범위를 맞춰주기 위한 정규화
- 판다스 & sklearn 으로 해줄 수 있다.
- 사이킷런에서 제공하는 Normalizer 모듈은 일반 정규화는 약간의 차이가 있다.
- 사이킷런에서의 Normalizer 모듈은 선형대수에서의 정규화 개념이 적용됐으며, 개별 벡터의 크기를 맞추기 위해 변환하는 것을 의미한다.
- 즉, 개별 벡터를 모든 피처 벡터의 크기로 나눠준다.
- 3개의 피처 x,y,z 가 있으면 새로운 데이터는 다음과 같다.
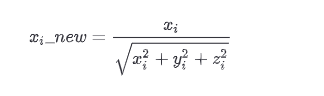
판다스 & sklearn 비교. Dataset 은 House Prices.
데이터셋 House Data
# pandas 로 정규화 해보기
df = train[["SalePrice", "LotArea"]]
pnormal_df = (df - df.mean())/df.std()
print(pnormal_df)
pnormal_df.hist(bins=50, figsize=(20,8))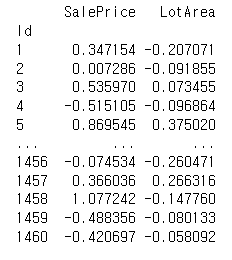
# sklearn 으로 정규화
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit_transform(df)
snormal_df = pd.DataFrame(ss.fit_transform(df_o), columns=["SalePrice_s", "LotArea_s"])
print(snormal_df)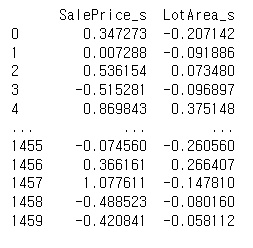
sklearn 의 다른 정규화들
# 가작 작은 값은 0, 가장 큰 값은 1 로 변환
from sklearn.preprocessing import MinMaxScaler
minmax_scaler = MinMaxScaler()
# 각 특성의 절대값이 0 과 1 사이로 만들어줌
from sklearn.preprocessing import MaxAbsScaler
maxabs_scaler = MaxAbsScaler()
# 평균과 분산 대신에 중간 값과 사분위 값을 사용
from sklearn.preprocessing import RobustScaler
robust_scaler = RobustScaler()
# Normalizer 의 경우 각 샘플(행)마다 적용
from sklearn.preprocessing import Normalizer
normal_scaler = Normalizer()실제코드
from sklearn.preprocessing import StandardScaler
# 변형 객체 생성
std_scaler = StandardScaler()
std_scaler.fit_transform(tf)
ss = pd.DataFrame(std_scaler.fit_transform(tf), columns=["std_scaler"])
ss
from sklearn.preprocessing import MinMaxScaler
# 변형 객체 생성
minmax_scaler = MinMaxScaler()
minmax_scaler.fit_transform(tf)
mm = pd.DataFrame(minmax_scaler.fit_transform(tf), columns=["minmax_scaler"])
mm
from sklearn.preprocessing import MaxAbsScaler
# 변형 객체 생성
maxabs_scaler = MaxAbsScaler()
maxabs_scaler.fit_transform(tf)
ma = pd.DataFrame(maxabs_scaler.fit_transform(tf), columns=["maxabs_scaler"])
ma
from sklearn.preprocessing import RobustScaler
# 변형 객체 생성
robust_scaler = RobustScaler()
robust_scaler.fit_transform(tf)
rb = pd.DataFrame(robust_scaler.fit_transform(tf), columns=["robust_scaler"])
rb
from sklearn.preprocessing import Normalizer
# 변형 객체 생성
normal_scaler = Normalizer()
normal_scaler.fit_transform(train[["SalePrice", "LotArea"]])
nm = pd.DataFrame(normal_scaler.fit_transform(train[["SalePrice", "LotArea"]]), columns=["SalePrice_n", "LotArea_n"])
nm
# 데이터 합치기
result = pd.concat([ss,mm,ma,rb,nm], axis=1)
result
# 시각화 해보기
_ = result.hist(bins=50, figsize=(16,12))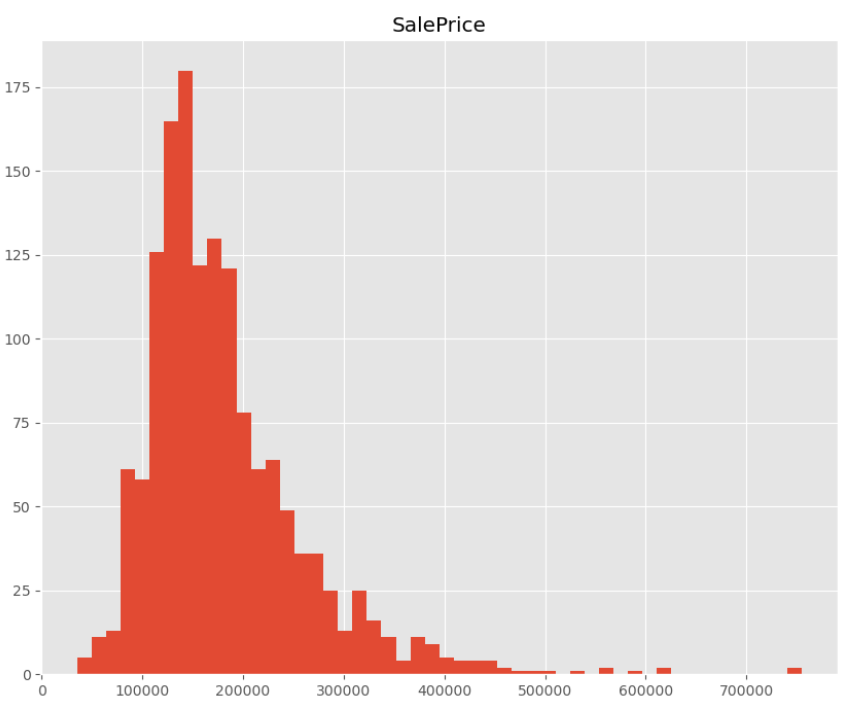
실제 SalePrice
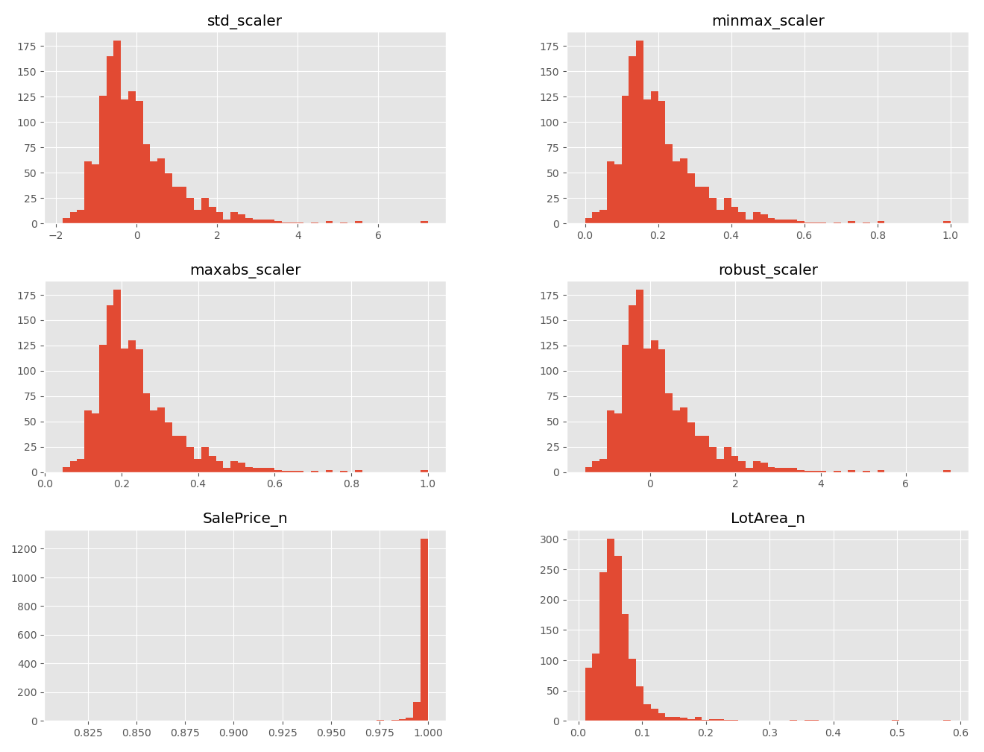
SalePrice 정규화 결과
정규분포를 위한 트랜스포메이션
- 중심 극한 정리 : 표본의 크기가 충분히 크다면 표본 평균의 분포는 정규 분포를 따른다.
- 예측하려는 값이 비교적 매우 작거나 매우 큰 값보단 중간값에 가까운 값일 확률이 높다.
- 즉, 데이터가 정규분포 형태이면 모델 예측 성능이 좋아질 수 있다!
프랜스포메이션 방법 3가지 : 로그, 루트, boxcox
# 원본 데이터
train["SalePrice"]
# 로그 트랜스포메이션
np.log1p(train["SalePrice"])
# 루트 트랜스 포메이션
np.sqrt(train["SalePrice"])
# boxcox 트랜스포메이션
from scipy.stats import norm
from scipy import stats
bc = pd.Series(stats.boxcox(train['SalePrice'])[0])
bc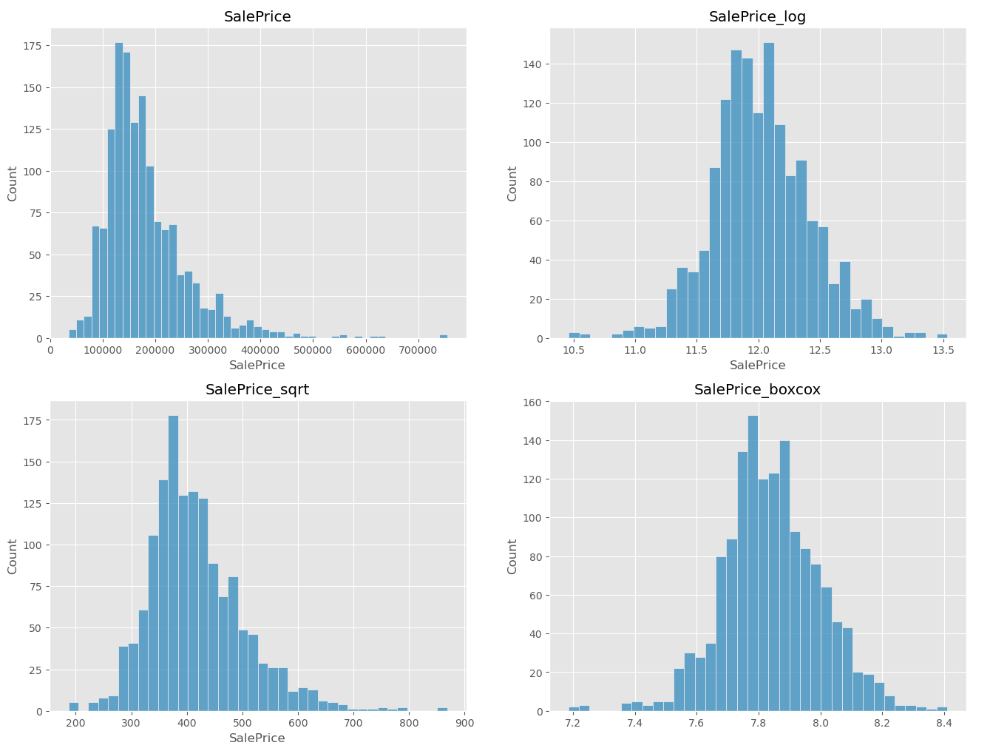
log, boxcox 트랜스포메이션 StandardScaler 적용해보기
- log 트랜스포메이션에 StandardScaler 적용
s_log = pd.DataFrame(np.log1p(train["SalePrice"]))
s_log = pd.DataFrame(StandardScaler().fit_transform(s_log))
print(s_log.std())
_ = sns.displot(s_log)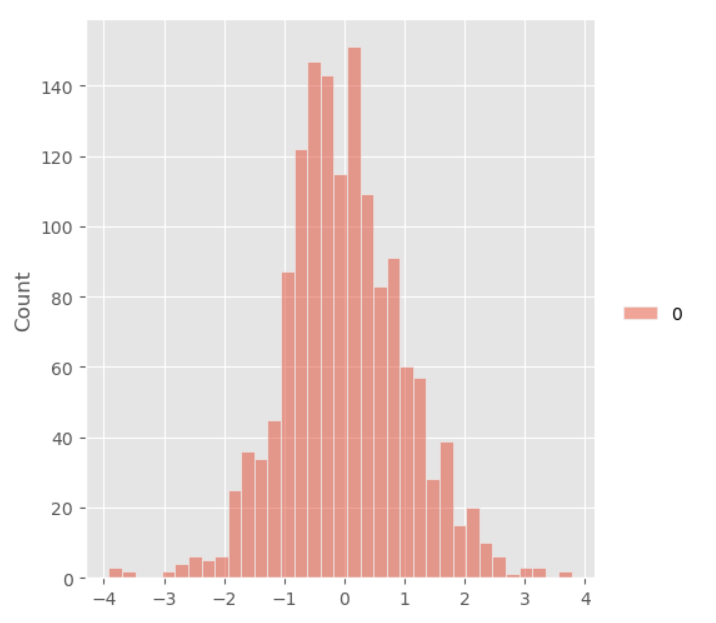
- boxcox 트랜스포메이션에 StandardScaler 적용
pd.DataFrame(bc)
bc_ = pd.DataFrame(StandardScaler().fit_transform(pd.DataFrame(bc)))
print(bc_.std())
_ = sns.displot(bc_)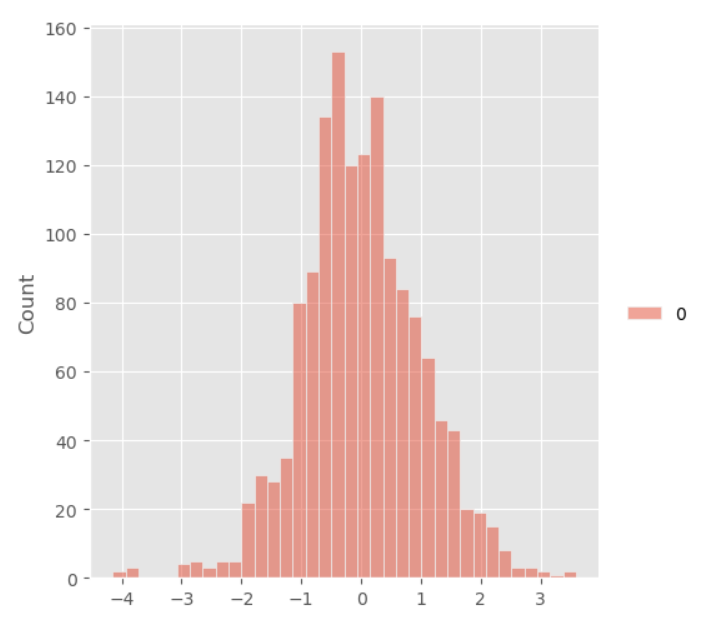

열심히 사는 중