221116
-
802 실습 : 다른 트리모델도 사용해보는게 목표
- DecisionTreeRegressor
- RandomForestRegressor
- GradientBoostingRegressor
- ExtraTreesRegressor (전처리를 덜해줘도 성능이 잘 나오는 편)
먼저 y 값의 이상치를 확인해보자.
sns.scatterplot(data=train, x=train.index, y="y")
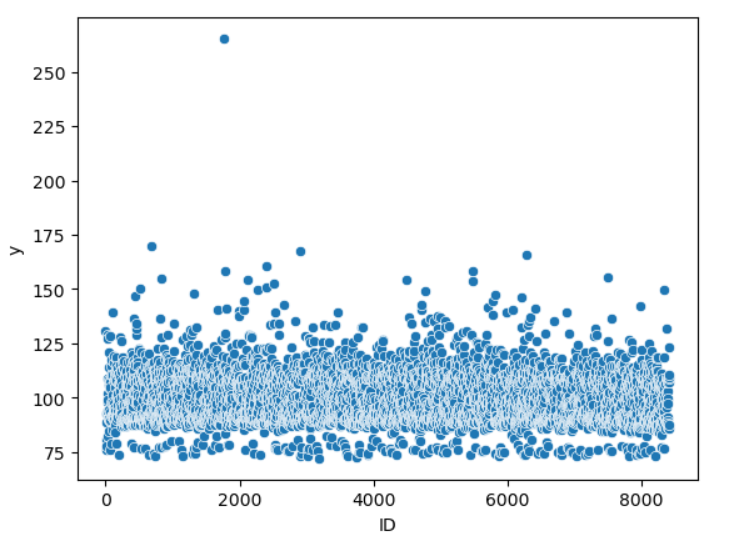
- 굉장히 동떨어진 값이 있다!
- 회귀는 이상치에 영향을 많이 받는다.
- 저친구를 제거를 해보자!!
# 200 이상인거 하나밖에 없으니까 200이하만 취해서 복사하기
train = train[train["y"] < 200].copy()
train.shapeHold-out-validation
- 너무 큰 데이터 셋의 경우 cross-valid 를 할 시간이 없을 수 있다.
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.1, random_state=42)
X_train.shape, X_valid.shape, y_train.shape, y_valid.shape
>>> ((3787, 919), (421, 919), (3787,), (421,))부스팅 (Boosting)
-
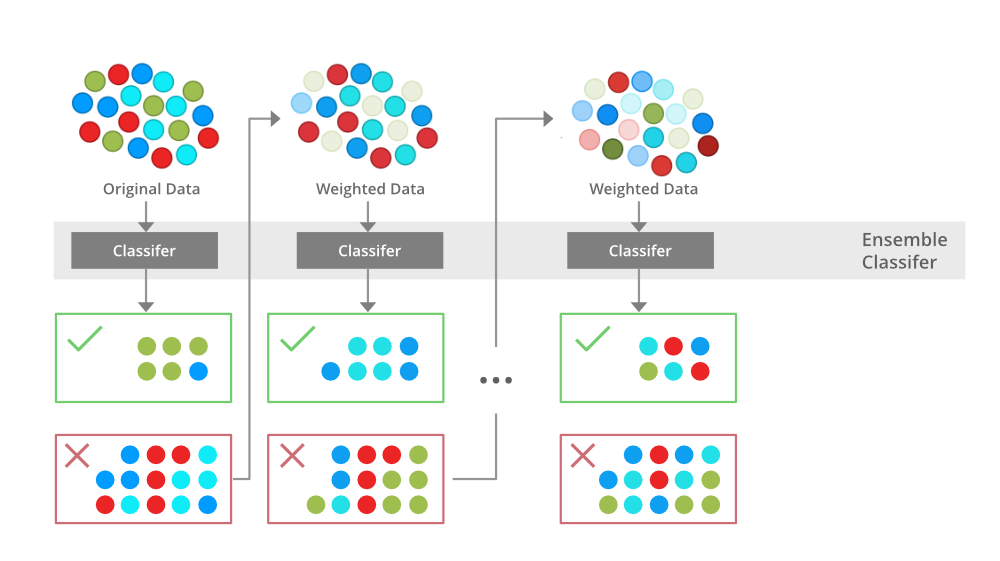
부스팅은 약한 모델을 여러개 연결해서 강한 모델을 만들어 내기 위한 앙상블 방식이다.
-
부스팅의 아이디어는 앞의 모델들을 보완해 나가면서 일련의 모델들을 학습시켜 나가는 것이다.
- 에이다 부스트는 앙상블에 이전까지의 오차를 보정하기위해 샘플의 가중치를 수정할 수 있도록 모델을 순차적으로 추가한다.
- 그래디언트 부스팅은 에이다 부스트와 달리 샘플의 가중치를 수정하는 대신 이전 모델이 만든 잔여 오차에 대해 새로운 모델을 학습시키게 된다.
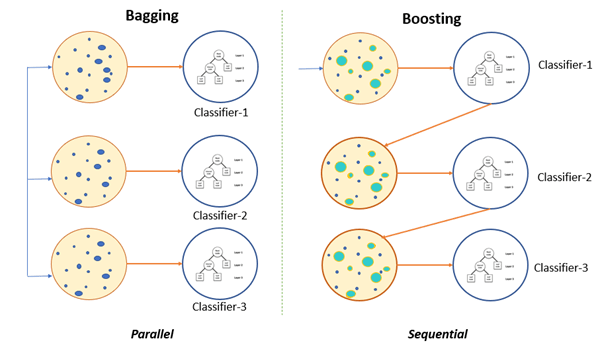
Bagging 과 Boostring
- 배깅 방식은 부트스트래핑을 해서 트리를 병렬적으로 여러 개 만들기 때문에 오버피팅 문제에 좀 더 적합하다.
- 개별 트리의 낮은 성능이 문제일 때는 이전 트리의 오차를 보완해 가면서 만들기 때문에 부스팅이 좀 더 적합하다.
경사하강법(gradient descent)
손실함수 그래프에서 값이 가장 낮은 지점으로 경사를 타고 하강한다. 머신러닝에서 예측값과 정답값간의 차이가 손실함수인데 이 크기를 최소화시키는 파라미터를 찾기 위해 경사 하강법을 사용한다.
예측값과 정답값 사이에 손실이 최소화될수록 좋은 모델이고, 손실이 가장 작은 지점을 찾기 위해서(기울기가 0인 지점을 찾기 위해서) 경사를 점점 내리는 것을 경사하강법이라고 한다.
따라서 경사하강법의 목적은 손실함수가 가장 작고, 예측을 잘 하는 모델의 파라미터를 찾기 위함이다.
Gradient Boosting

- 부스팅 트리에서 n_estimators 는 몇 번째 트리인지를 의미한다.
- 트리의 갯수를 의미하는게 맞긴 한데, 몇번째 학습인지를 의미한다.
- epoch == n_estimators 와 같은 개념이다.
- epoch 학습 횟수
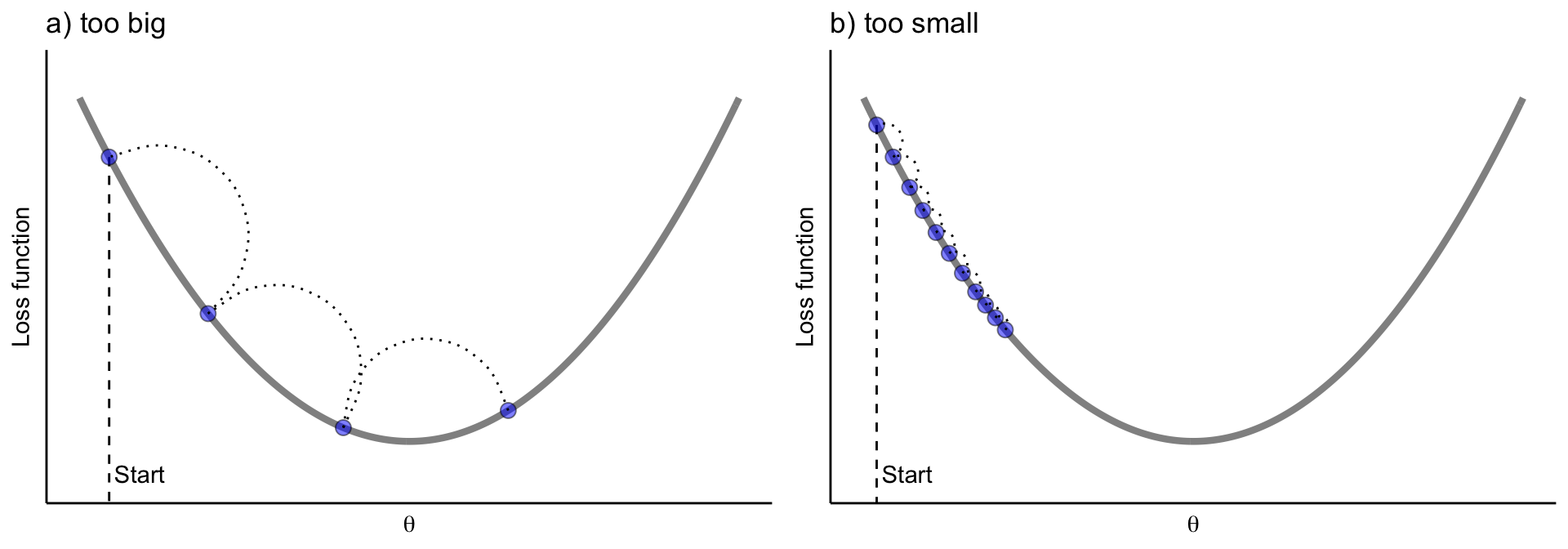
- learning_rate 는 학습률을 의미하는데 보폭이라고 번역하기도 한다. 보폭이 너무 크면 대충 찾기 때문에 최소점을 지나칠 수도 있다. 그래서 위의 그래프처럼 발산을 하기도 한다.
- learning_rate, 학습률, 보폭 보통 같은 의미로 쓰입니다.
성능에 고려 없이 GBM 에서 훈련시간을 줄이려면? => 보폭을 크게 하면 훨씬 빨리 학습하게 된다. 그렇기 때문에 learning_rate 를 올리면 학습시간은 줄어들지만 제대로 된 loss(손실)가 0이 되는 지점을 제대로 찾지 못할 수도 있다.
Residual : 잔차
GBM 은 왜 랜덤 포레스트와 다르게 무작위성이 있을까?
- 이전 오차를 보완해서 순차적으로 만들기 때문에 무작위성이 없다.
손실함수로 absolute loss 는 지원은 하지만 squared loss 를 더 많이 사용하는 이유는?
- absolute loss 같은 경우에는 기울기가 같아서 미분을 했을 때 방향에 따라 같은 미분값이 나와서 기울기가 큰지, 작은지 비교할 수 없다. 그래서 squared loss 를 더 많이 사용한다.

Q. 왜 부스팅 계열 모델이 설치가 잘 되기도 하지만 설치에 실패하는 경우가 생길까?
A. 구동하려면 다른 언어 환경이 함께 필요한 경우가 많다. 기존에 다른 도구를 설치하다가 해당 언어 환경 도구를 설치해 놨다면 비교적 잘 설치가 되지만, 처음 설치할 때는 실패하는 경우가 많다.
conda 는 비교적 패키징이 잘 되어 있어서 관련된 환경을 잘 구성해 준다. 그래서 되도록이면 conda 로 설치해야 좋다.
XGBoost (Extreme Gradient Boosting)
XGBoost 파라메터 참고
https://xgboost.readthedocs.io/en/stable/parameter.html
https://xgboost.readthedocs.io/en/stable/python/index.html
https://for-my-wealthy-life.tistory.com/35?category=950145
LightGBM
참고
LIGHTGBM 이란?
- XGBoost 보다 빠르다.
- Light GBM은 큰 사이즈의 데이터를 다룰 수 있고 실행시킬 때 적은 메모리를 차지한다.
- 단, 과적합(overFitting)되기 쉬움. 즉, 작은 데이터셋에 사용하는 것은 좋지 않다.
- 10000row 이상에서 사용하는걸 추천
