MLP의 한계
공간정보 손실
Spatial Information의 손실
2차원 구조의 영상을 1차원으로 변환하여 입력
픽셀간의 공간적 관계 정보가 완전 소실됨
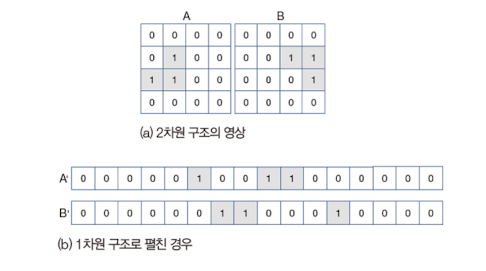
이미지 내 물체의 위치 정보를 반영하지 못하기 때문에, 이미지의 어디에 대상이 있는지 모르는 상황에서 분류 성능이 크게 저하됨
변환 불변성
Translation Invariance
위치 이동에 취약함 - 이미지의 작은 변형에도 민감하게 반응
MLP는 각 픽셀을 개별 노드로 학습(절대적 위치에 의존)하기 때문에, 같은 패턴이라도 위치가 달라지면 다른 데이터로 취급

예를들어 고양이가 이미지의 왼쪽 상단에 있을 때는 분류에 성공하지만, 오른쪽 하단으로 이동하면 같은 고양이라도 분류 실패할 수 있음
FC층의 과다한 파라미터
(Full Connected층)
데이터 크기 증가에 따른 학습 한계
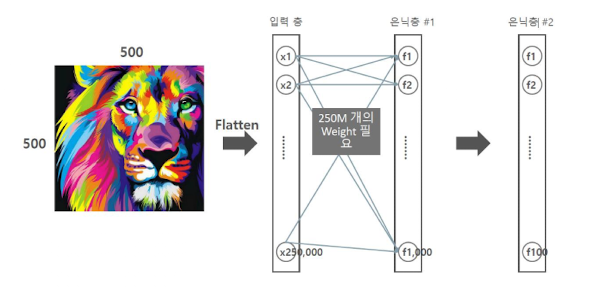
Local Feature Extraction의 부재
전역 학습
단순히 학습된 가중치로만 정보를 이해
모든 픽셀이 각각의 가중치에 연결되기 때문에, 부분적인 특징을 추출하지 못하고 전체적으로 해석
인간의 시각정보처리
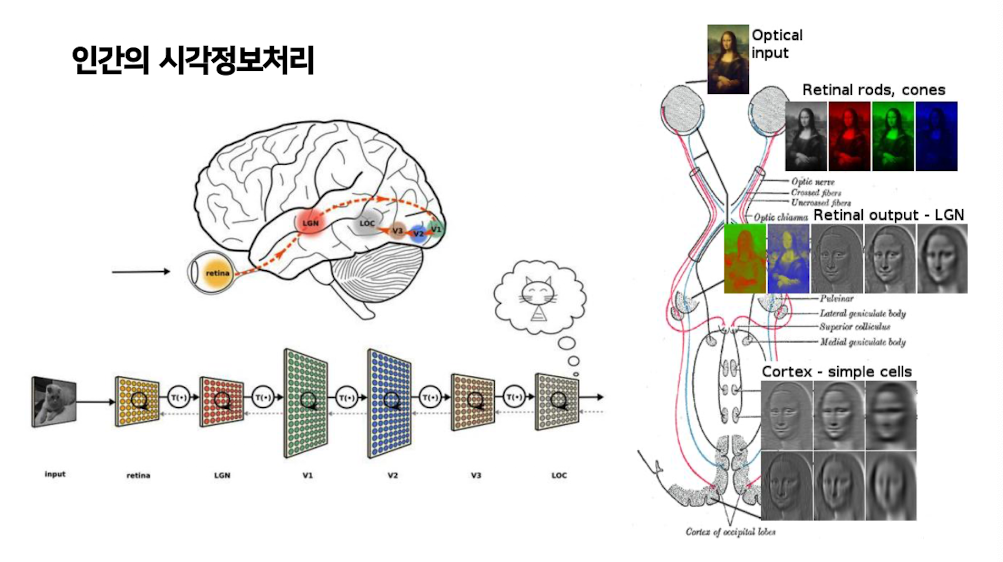
CNN 등장
인간의 시각을 모방한 컨볼루션 신경망 CNN 등장
CNN
동물의 시각피질의 구조에서 영감을 받아 만들어진 딥러닝 신경망 모델
딥러닝 성공에 가장 기여한 모델
✔️ 다양한 응용
CV- 분류, 검출, 분할, 추적 등의 문제 해결
비디오 게임 AI- 화면 장면 분석
알파고- 19x19 바둑판 형세 판단
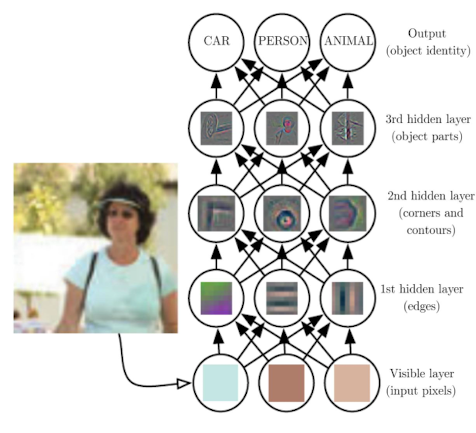
CNN은 동물의 계층적 특징 추출과 시각인식체계를 참조하여 만들어진 모델
CNN 특징
📍 공간 정보 보존
MLP처럼 이미지 전체를 펼치지 않고, 작은 영역을 슬라이딩하면서 처리하기 때문에 위치 정보 보존 가능
📍 파라미터 수
Weight Sharing과 Local Receptive Field를 통해 학습 파라미터 수 감소
📍 위치 변화
Pooling Layer를 통해 Translation Invariance 확보
이미지가 약간 이동하거나 왜곡되어도 여전히 같은 특징 잡아낼 수 있음
📍 특징 추출
Feature Extraction
Convolutional Filter를 통해 이미지의 Low-level(에지, 색상)에서 High-level(객체, 윤곽) 특징을 자동으로 학습
📍 과적합
Overfitting
Regularization 기법(Dropout, Batch Normalization)을 쉽게 적용할 수 있어 과적합에 강함
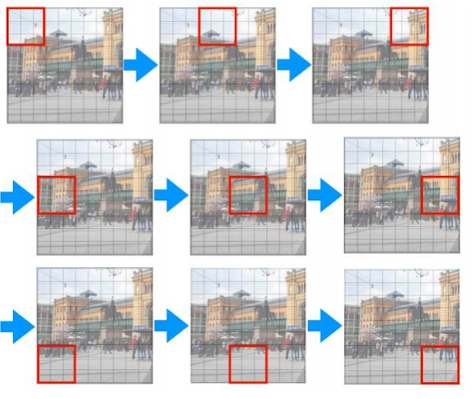
Local receptive Field
CNN에서 각 뉴런이 입력 데이터에서 관찰할 수 있는 국소적인 영역
CNN의 필터나 커널은 입력 이미지의 일부 영역만 집중적으로 학습
Local Receptive Field 확장 : Receptive Field
단일 필터가 보는 영역은 작지만, Layer가 깊어지면 그 필터가 간접적으로 보는 영역이 확장됨
➡️ CNN이 깊어질수록 Local Receptive Field의 영향이 누적되어 더 넓은 영역 학습 가능
ex) 첫번째 Layer의 3x3 필터가 보는 영역이 Local Receptive Field라면, 두번째 Layer에서는 이전 Layer의 Feature Map이 다시 Conv되므로 더 넒은 시야를 가지게 됨
CNN 역사
CNN의 간단한 역사
- 1980- 네오코그니트론
- 1998- 르쿤의 LeCun1998: LeNet-5를 구현하여 수표 자동 입력 시스템 구현
- 2010- ImageNet dataset 탄생: 1400만개 영상이 21841개 클래스로 레이블링
- 2010- ILSVRC 대회 시작: 1000클래스, 120만 훈련셋, 5만 검증셋, 15만 테스트셋
- 2012- AlexNet이 Top-5 15.3% 오류율로 우승 (관심증가)
- 이후 층이 깊어진 VGGNet, GoogLeNet, ResNet 등이 우승
- 물체 검출, 분할, 추적, 자세 추정 등의 다양한 CNN 기반 모델 등장
- 2014- 생성 모델 GAN 등장
- 알고리즘 발전
ReLU 등 활성 함수
Cross Entropy 등 손실 함수
Dropout 등 정규화 기법
Adam 등 옵티마이저
