Today I Learned
오늘 배운 내용은 딥러닝!
딥러닝
선형 모델
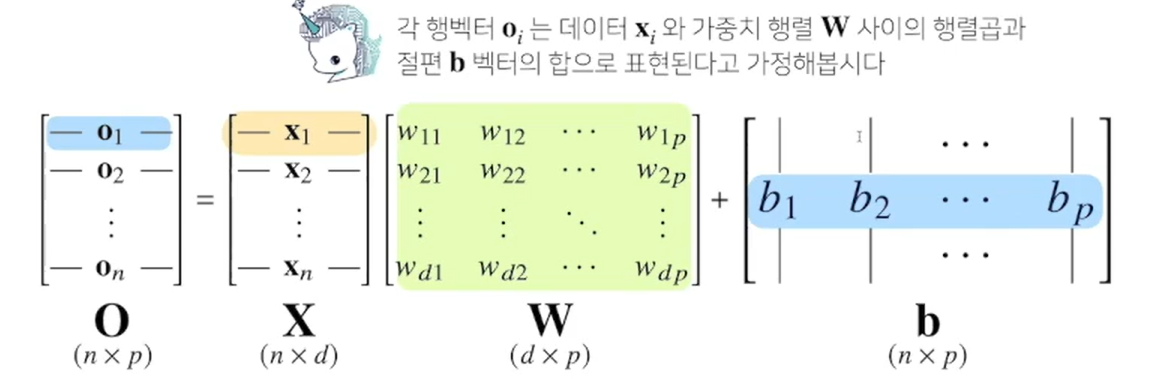
-
X : 각각의 데이터 포인트를 모아놓은 행렬
W : 가중치 행렬. X를 다른 데이터 벡터 공간으로 보내주는 역할
b : Y절편에 해당하는 벡터들을 모든 행에 대해 똑같이 복제한 y절편 벡터(각 행들이 같은 값, 열마다는 다름) -
선형 모델 행벡터 O = X*W+b
-
X가 d 차원이지만 출력 벡터 결과 O의 차원은 p로 바뀌게 된다.
-
분류문제 : 주어진 입력 데이터를 여러 클래스 중 하나로 분류하는 문제
-
분류문제를 풀거나 복잡한 패턴의 문제를 풀때는 선형모델만 가지고는 좋은 결과를 내기 어렵다.
따라서, 비선형 모델이나 선형, 비선형을 결합한 모델을 활용한다.
Softmax 연산
-
Softmax 함수 : 모델의 출력을 확률로 해석할 수 있게 변환해주는 연산
주어진 벡터의 각 요소를 0과 1 사이의 값으로 변환하여 전체 합이 1이 되도록 만드는 함수 -
입력 벡터의 각 요소를 지수 함수로 변환한 후, 모든 요소의 합으로 각 요소를 나누어주는데, 이를 통해 입력 벡터의 각 요소가 클래스에 속할 확률로 해석될 수 있다.
import numpy as np
def softmax(z):
exp_z = np.exp(z - np.max(z)) # 오버플로우 방지를 위해 입력값 중 최댓값을 빼줍니다.
softmax_output = exp_z / np.sum(exp_z, axis=0)
return softmax_output
# 예시 입력 벡터
z = np.array([2.0, 1.0, 0.1])
# 소프트맥스 함수 적용
softmax_output = softmax(z)
# 출력
print("소프트맥스 함수 출력 결과:", softmax_output)
# 소프트맥스 함수 출력 결과: [0.65900114 0.24243297 0.09856589]
print("합계:", np.sum(softmax_output))
# 합계: 1.0
-
분류문제를 풀 때 선형모델과 소프트맥스 함수를 결합해 예측한다.
-
학습할때는 softmax가 필요하지만, 추론단계에선 one-hot 벡터로 최대값을 가진 주소만 1로 출력하는 연산을 softmax 대신 사용한다.
신경망(neural network)
선형모델과 활성함수(activation function)을 합성한 함수
활성 함수
-
신경망에서 각 뉴런의 출력을 결정하는 함수
-
입력 신호의 총합을 계산한 후 이를 활성화 함수에 적용하여 다음 층으로 전달되는 출력을 생성한다.
-
활성화 함수는 비선형 함수로, 신경망이 복잡한 비선형 관계를 모델링할 수 있도록 도와준다.
-
실수값을 입력으로 받아서 실수값을 출력한다.
-
활성함수를 쓰지 않으면 딥러닝은 선형모델과 차이가 없다.
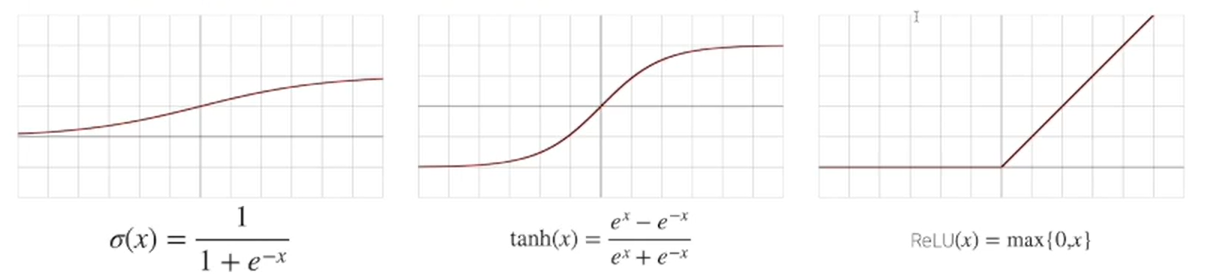
- 전통적으로는 시그모이드나 tanh 함수를 많이 썼지만, 딥러닝에서는 ReLU 함수를 많이 쓰고있다.
다층 신경망(MLP)
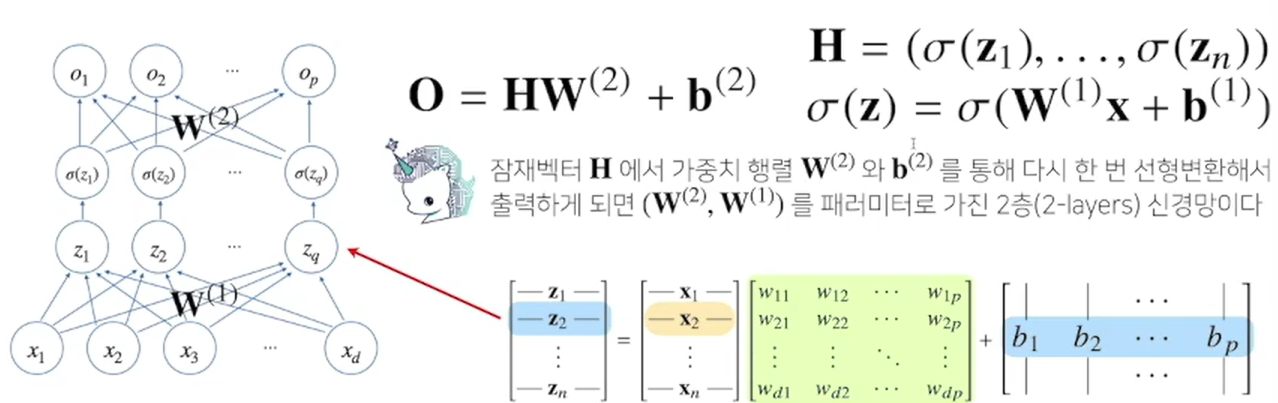
- x를 input으로 선형모델을 적용하면 z(z=xw+b)가 된다. z에다가 활성함수를 적용하면 H(H=σ(z))가 되고, 여기에 다시 선형모델을 적용해 2층 신경망(2-layers)으로 모델을 만들 수 있다.
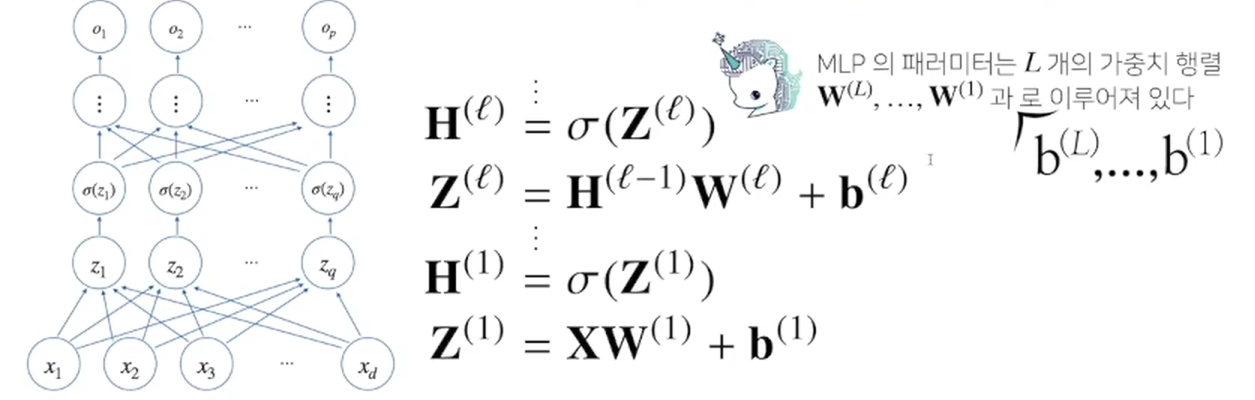
-
다층(multi-layer) 퍼셉트론은 이런 신경망이 여러층 합성된 함수를 말한다.
-
이론적으로는 2층 신경망으로도 임의의 연속함수를 근사할 수 있다.
하지만 층이 깊을수록 목적함수를 근사하는 데 필요한 뉴런(노드)의 숫자가 훨씬 빨리 줄어들어 좀 더 효율적인 학습이 가능하다. -
즉, 좀 더 적은 뉴런을 가지고도 복잡한 패턴을 표현할 수 있기 때문에 여러 층의 신경망을 구성한다.
딥러닝 학습 원리
역전파(backpropagation) 알고리즘
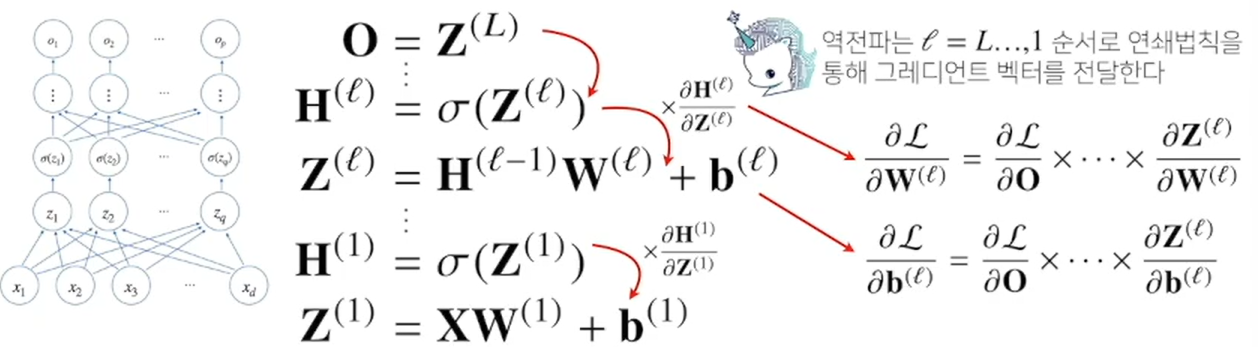
-
각 층 패러미터의 gradient 벡터는 맨 윗층부터 내려가면서 역순으로 계산되며 전달된다.
-
역전파 알고리즘은 합성함수 미분법인 연쇄법칙(chain-rule) 기반 자동 미분(auto-differentiation)을 사용한다.
-
fowardpropagation과 달리 역전파는 각 미분값을 계속 메모리에 저장해야하므로 메모리 사용을 더 잡아먹는다.
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
