Today I Learned
오늘도 pandas 이어서!
내일은 대구 내려가서 TIL 못 쓸 예정!
Pandas
lambda / map / apply
-
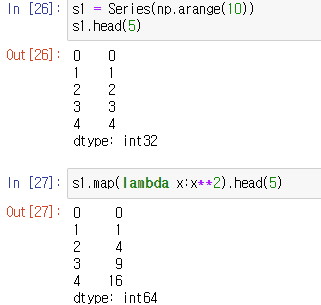
pandas의 series type 데이터에도 map 함수나 람다를 사용 가능하다.
-
funcion 대신에 dict, sequence 자료형 등으로 대체가 가능하다.
없는 값은 NaN이고, 같은 위치의 데이터를 map()으로 전환한다.

-
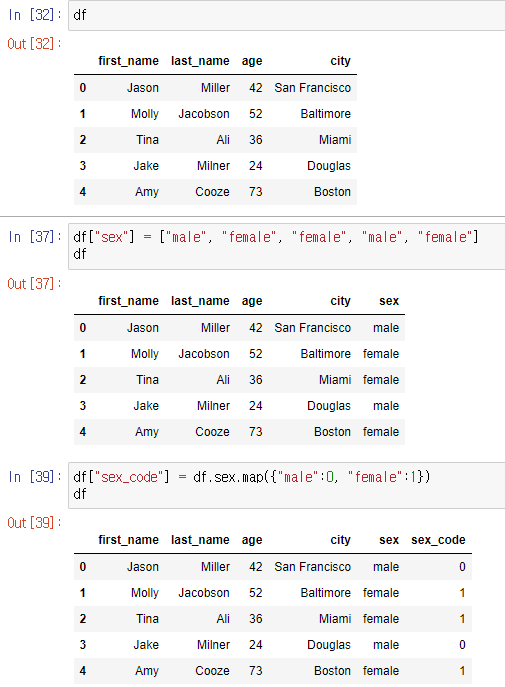
map에 dict를 이용해서 새 column을 생성할 수 있다.
-
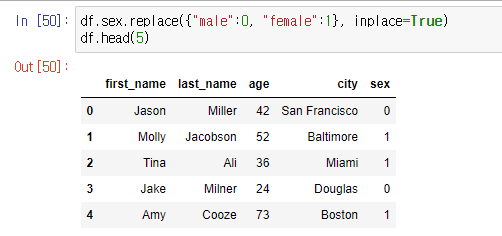
replace 함수를 이용해 데이터를 변환할 수 있다.
기본적으로는 원본 dataframe을 변경하지 않고 복사본을 다루지만, inplace=True 파라미터를 사용하면 원본 자체를 바꾼다.
-
apply()를 사용하면 map과 달리 series 전체(column)에 함수를 적용 가능하다.
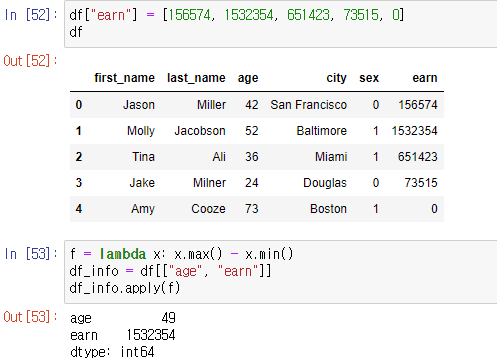
-
element 단위로 함수를 적용시킬 수 있다.
이땐 applymap()을 쓰기도 하나 depreciated되어 apply 사용을 권장한다고 한다.

Built-in functions
-
describe() : numeric type 데이터의 요약 정보를 보여준다.
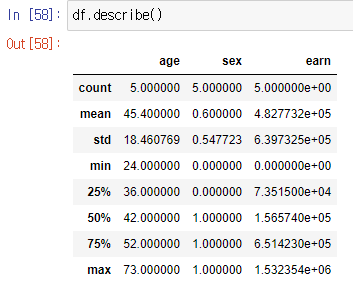
-
unique() : series 데이터의 유일한 값들의 list를 반환한다.
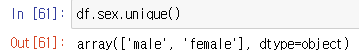
-
sum, sub, mean, min, max, count, median, mad, var 등
기본적인 column별(axis=0), row별(axis=1) 연산을 지원한다.
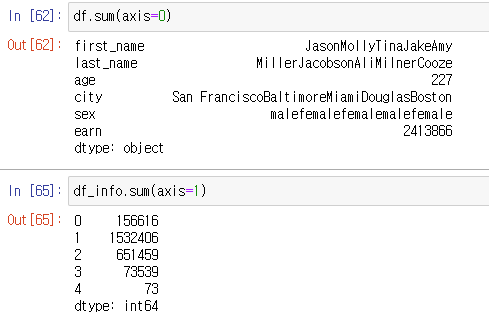
-
isnull() : column이나 row값의 NaN(null)값의 index를 반환한다.
-
sort_values : column을 기준으로 데이터를 sort
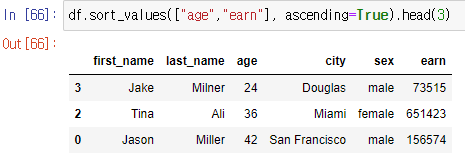
-
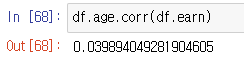
corr, cov, corrwith : 상관계수와 공분산을 구하는 함수