Today I Learned
오늘부터 부스트캠프 AI Tech 시작!
학습 정리를 이 블로그에다 할 생각이다.
이번 주는 pytorch에 대해 배운다!
부스트캠프 진행하는 동안 월~금의 TIL은 학습 정리에 사용할 예정이다.
아래의 내용대로 정리할 예정!
강의 복습 내용
과제 수행 과정 / 결과물 정리
피어세션 정리
학습 회고
강의 복습
PyTorch
Facebook에서 개발한 python 기반의 오픈 소스 딥러닝 프레임워크.
- 딥러닝, 머신러닝을 간편하게 이용할 수 있게 해줘서 실무에서도 많이 사용되는 프레임워크
- 동적 계산 그래프(Dynamic Computation Graph)
런타임에 그래프를 생성하고 수정할 수 있게 동적으로 작동한다. - GPU를 지원해서 대규모 병렬 연산을 빠르게 할 수 있다.
Tensor
Pytorch의 데이터 구조.
Numpy의 ndarray와 유사하다.
언어적, 대수적, 공간, 코드로 표현이 가능하다.
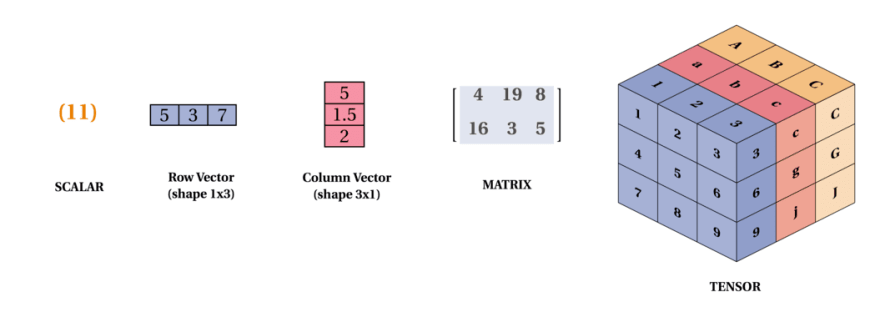
이미지 출처: practicaldev
{kind=link}
- 0-D Tensor : Scalar. 단일 숫자 값.
- 1-D Tensor : Vector. 숫자의 배열.
- 2-D Tensor : Matrix. 2차원 배열. 행과 열로 구성 ex) 그레이 스케일 이미지(흑백)
- 3-D Tensor : 2-D Tensor가 여러개 쌓여 형성. ex) RGB값을 가지는 이미지.
- N-D Tensor : (N-1)-D Tensor가 여러개 쌓여서 형성
import torch
scalar = torch.tensor(1)
vector = torch.tensor([1,2,3,4,5])
matrix = torch.tensor([[1,2],[3,4]])
3dtensor = torch.tensor([[[1,2],[3,4]],[[5,6],[7,8]]])stack(tensors, dim=0)
stack 함수를 통해 여러 텐서들을 합쳐 새로운 차원을 추가할 수 있다.
기본적으로는 0번 축이고 dim=n 파라미터로 새로 추가할 axis를 지정할 수 있다.
matplotlib
파이썬 데이터 시각화 라이브러리
- pyplot 모듈을 이용해 그래프를 그릴 수 있다.
import matplotlib.pyplot as plt로 임포트해 사용.
PyTorch 데이터 타입
Tensor가 저장하는 값의 데이터 유형
| 데이터 타입 | PyTorch dtype | 설명 |
|---|---|---|
| 32-bit float | torch.float32 or torch.float | 기본 부동 소수점 타입 (일반적인 신경망 연산에 사용) |
| 64-bit float | torch.float64 or torch.double | 더 높은 정밀도의 부동 소수점 타입 (과학 계산에 사용) |
| 16-bit float | torch.float16 | 절반 정밀도의 부동 소수점 타입 (메모리 및 연산 최적화에 사용) |
| 8-bit int | torch.int8 | 8-bit 정수 타입 (메모리 절약 및 특정 연산에 사용) |
| 16-bit int | torch.int16 or torch.short | 16-bit 정수 타입 |
| 32-bit int | torch.int32 or torch.int | 32-bit 정수 타입. 대부분 쓰는 int 표준 |
| 64-bit int | torch.int64 or torch.long | 64-bit 정수 타입 |
| 8-bit unsigned int | torch.uint8 | unsigned 8-bit 정수 타입 |
| Boolean | torch.bool | 불리언 타입 (True/False) |
-
tensor에 타입 지정
vector = torch.tensor([1,2,3],dtype=torch.int)
처럼 텐서에 dtype의 파라미터로 타입을 지정할 수 있다.
vector.dtype으로 해당 변수의 타입을 알 수 있다. -
타입캐스팅
float(), int(), double()같은 타입 함수 사용type(): tensor.type(torch.float32) 같이 type 함수 사용to(): tensor.to(dtype=torch.float64) 같이 to 함수 사용. gpu같이 장치 이동에도 쓰인다.
Tensor 함수
| 함수/메서드 | 설명 | 사용 예제 |
|---|---|---|
torch.tensor | 데이터를 기반으로 텐서를 생성 | torch.tensor([1, 2, 3]) |
.shape | 텐서의 차원을 튜플로 반환(모양 확인) | tensor.shape -> ex)torch.Size([2, 2]) |
.dim() | 텐서의 차원의 수(단일 값)을 반환 | tensor.dim() -> ex) 2 |
.numel() | 텐서에 있는 요소의 총 개수 반환 | tensor.numel() |
.dtype | 텐서의 데이터 타입을 반환 | tensor.dtype |
.to() | 텐서를 지정한 데이터 타입이나 장치로 이동 | tensor.to(dtype=torch.float64, device='cuda') |
.mean() , sum() | 텐서의 평균/합계를 계산 | tensor.mean() |
.max(), .min() | 텐서의 최대/ 최소값을 반환 | tensor.max() |
.reshape() | 텐서의 형태를 변경 | tensor.reshape(new_shape) |
.transpose() | 텐서의 차원을 전치 | tensor.transpose(0, 1) |
.unsqueeze() | 텐서에 차원을 추가 | tensor.unsqueeze(0) |
.squeeze() | 텐서에서 차원 크기가 1인 차원을 제거 | tensor.squeeze() |
.stack() | 여러 텐서를 주어진 차원에서 쌓음 | torch.stack([tensor1, tensor2], dim=0) |
.clone() | 텐서의 복사본을 생성 | tensor.clone() |
Tensor 생성
특정 값으로 초기화
.zeros(): 원소가 0으로 초기화된 Tensor 생성
import torch
vector = torch.zeros(3) # [0,0,0]
matrix = torch.zeros([2,4]) # [[0,0,0,0],[0,0,0,0]]
3dtensor = torch.zeros([4,3,2]) # 4개의 3행2열 tensor-
.ones(): 원소가 1로 초기화된 Tensor 생성 -
.zeros_like(t),.ones_like(t)
t와 크기(shape), 자료형(dtype)이 같게 0/1로 초기화한 Tensor 생성
기존 텐서 t는 변함없음
난수로 초기화
-
.rand(): 0~1 사이 연속균등분포의 난수로 초기화한 Tensor 생성
난수는 0~1사이의 모든 값에대해 확률이 같다. -
randn(): 표준정규분포의 난수(중간값 0)로 초기화한 Tensor 생성
지정된 범위 초기화
arange(start=0, end=102, step=3) : 0, 3, 6, ..., 99. 끝값은 미포함
초기화 x
.empty()
명시적인 값 넣지 않고 메모리에 들어있던 임의값으로 임시로 채움 -> 메모리 효율 증대
나중에 .fill(값)으로 특정 값 채울 수 있다.
데이터로 생성
-
.tensor() : 리스트로 생성할때
-
.from_Numpy() : ndarray로 생성할 때
CPU / GPU Tensor
-
기본적으로 텐서는 cpu에서 생성해 RAM에 저장된다.
CPU 사용 시 메모리 접근 속도가 빨라서 복잡한 연산이 필요없으면 CPU가 적합하다. -
GPU는 병렬 처리 능력이 뛰어나 더 복잡하고 큰 계산을 빨리 할 수 있게 해준다.
torch.cuda.is_available()로 cuda 사용여부 알 수 있다. -
torch.tensor([1,2,3])으로 CPU 텐서 생성 후,
.to('cuda')or.cuda()함수를 사용해서 GPU로 이동시킬 수 있다.
.cpu()로 다시 cpu로 이동 가능 -
.device로 cpu/gpu 어디에 있는지 확인 가능
clone / detach 차이
-
둘 다 복제해서 새로운 텐서를 만든다.
-
clone()은 원본의 값을 복사해 완전히 새로운 텐서를 생성한다.
즉, 동일한 데이터지만 메모리에서 독립적(저장된 위치 다름)이다.
원본 텐서의 requires_grad 속성을 유지해 그래디언트 계산 여부는 원본을 따른다. -
detach()는 텐서를 계산그래프에서 분리하고 그래디언트 계산을 방지한다.
파라미터 업데이트에 영향을 주지 않고 텐서 사용시 유용하다.
원본 텐서와 같은 메모리를 공유한다.
Tensor Indexing / Slicing
-
1-D
Numpy와 매우 유사하다.TIL #435참고
왼쪽부터 0,1,2.. 오른쪽은 -1,-2,...부터 접근가능.
a[1:], t[-5:-3] 처럼 접근 가능.
t2[0:10:2] 처럼 0번째부터10번째까지 2개씩 건너뛰며 sub Tensor도 생성 가능 -
2-D~
t[행,열]로 접근 가능하다.
t2[3, 4:] = 3행에서 4번째열부터 끝까지
:만 쓸 경우 해당 axis의 모든 요소를 다 가져온다.
...는 배열의 현재 차원을 그대로 유지하면서 특정 차원을 선택하거나 슬라이스할 수 있게해준다.
- 과제 x
피어세션 정리
- 팀에서 지켜야 될 그라운드 룰!
- ~~님으로 호칭! 처음엔 존대, 친해지면 말 놓기!
- 서로 각 세우지 않기! 둥글게 둥글게!
- 출석은 9시 반에 팀 슬랙에도 따로 체크 후 10시까지 못 오신 분들 챙기기!
- 다음날 참여 못할 경우 전날 자정 전까지 말하기!
- 무단지각 3스택 or 무단불참 시 -> 스벅 아메리카노 tall 쿠폰 1개씩
(기준은 부스트캠프 지각 기준 + 피어세션 기준 - 하루 한 번까지 기록) - 주말에 뭐할지 월, 금마다 일상 공유 가볍게 10분정도 씩!
- 각자 의견 있으면 바로바로 말하기!
회고
-
아직 시작단계라 어려울것은 없는데 numpy랑 pandas는 한번 더 보고 와야겠다.
-
matplotlib 같은 시각화 라이브러리 사용법을 좀 알아봐두면 편할 것 같다.
