Today I Learned
오늘 배운 내용은 드디어 협업 필터링!
Collaborative Filtering
협업 필터링. 사용자들의 과거 행동 패턴(평점, 구매 이력 등)을 기반으로 비슷한 취향을 가진 사용자들의 선호도를 활용하여 추천하는 방식
-
비슷한 취향을 가진 유저들은 비슷한 아이템을 선호할 것이다라는 기본 가정에 기반
-
아이템이 가진 속성은 사용하지 않고도 추천이 가능하다.
유사도 측정법
-
일반적으로는 거리의 역수를 유사도로 사용한다. 그러므로 거리를 어떻게 측정하냐에따라 유사도 측정이 달라진다.
-
어떤 방법을 사용할지는 데이터의 특성, 실험 결과에 따라 달라진다.
-
MSD 유사도(Mean Squared Difference similarity)
두 유저나 아이템간 평점 차이를 기반으로 유사도 측정. 평점의 scale을 고려해 계산한다.
추천시스템 도메인에서만 자주 사용하는 측정법. 코사인유사도에서 발생하는 scale무시 문제 해결.
아래의 MSD(u,v)를 통해 평균제곱차이를 구해서 유사도의 분모로 넣어 차이가 적을수록 유사도는 1에 가까워진다. -
코사인 유사도(Cosine Similarity)
두 벡터가 이루는 각도의 코사인 값을 계산하여 유사도를 측정, 가장 흔하게 사용되는 방법
계산이 쉽고 희소데이터에서도 효과적임. 평점의 scale을 고려하지 않고 사용자의 평점 경향을 반영하지 못한다. 음수값이 있으면 해석이 어려울 수 있다.
방향이 완전히 같으면 1, 직각이면 0, 정반대면 -1 -
피어슨 유사도(Pearson Correlation Coefficient)
두 변수 간의 선형 상관관계를 측정하는 방법
각 벡터를 표본평균으로 정규화한 뒤에 코사인 유사도를 구한 것.
각 유저의 평점 평균을 중심으로 한 편차를 고려하여 -1에서 1 사이의 값을 가진다.
유저의 평점 경향(rating bias)을 고려하고 스케일에 영향을 받지 않지만, 비선형관계는 잘 파악하지 못하며 계산 복잡도가 코사인 유사도보다 높다. -
자카드 유사도(Jaccard Similarity)
두 집합 간의 유사도를 측정하는 방법. 두 집합의 교집합 크기를 합집합 크기로 나누어 계산한다.
0에서 1 사이의 값을 가지며, 1에 가까울수록 두 집합이 유사하다. 두 집합이 같은 아이템을 얼마나 공유하는지를 계산한다.
길이(차원)이 달라도 계산이 가능하며 계산이 단순하고 이진or집합 데이터에 효과적이다.
공통요소가 없으면 항상 0이며 값의 크기나 가중치를 고려하지 않는다.
ex) 유저의 구매 목록, 4점이상 평점을 준 영화, 좋아요 한 기사 등의 집합으로 계산
Rating Prediction
위의 방식들로 유사한 유저 or 아이템을 찾았으면 그걸 토대로 어떻게 타겟 유저의 rating을 예측하는 지에 대한 방법.
-
아래는 UBCF(유저기반)의 유저-아이템 평점의 예시지만, 반대로 하면 IBCF(아이템기반)의 평점도 구할 수 있다.
-
prediction이 아니라 추천문제면 아래의 과정으로 구한 평점을 정렬해 상위 k개만 추천하면 된다.
Absolute
-
평균 기반(average)
(i에대한 평가가 있는) 유사한 k명의 유저가 준 평점의 단순 평균 -
가중 평균 기반(weighted average)
유사도를 가중치로 사용해 유사한 유저의 평점에 더 높은 가중치를 부여해서 평균.
Relative
위의 방식들은 유저의 개인별 평점 경향(rating bias)을 고려하지 못한다.
상대적(relative) 평점방식은각 유저의 평균 평점으로부터의 편차(deviation)를 구해 평균에서 얼마나 잘 주는지를 따져서 평점 경향을 고려한다. 최종적으로는 유저 평균 평점에 예측한 편차를 더해 rating.
- 이 방식도 평균기반과 가중평균 기반 방식을 사용할 수 있다.
NBCF(Neighborhood-based CF)
이웃 기반 Collaborative Filtering.
memory-based Collaborative Filtering라고도 불린다.
-
구현이 간단하고 이해가 쉬운 장점이 있다.
-
Sparcity(희소성 문제)
실제 데이터에서 대부분의 유저-아이템 행렬은 비어있다(희소 행렬)
데이터가 충분하지 않으면 유사도 계산이 부정확해 추천 성능이 떨어진다. + cold start 문제.
Sparcity ratio(행렬중 비어있는 비율)가 99.5%를 넘지 않아야 NBCF가 유효하다. -
Scalability(확장성 문제)
아이템과 유저가 늘어나면 오히려 확장성이 떨어진다. 특정 아이템을 평가한 모든 유저와 유사도를 구해야하는데 유저가 많아지면 연산이 계속 늘어나기 때문이다.
-
KNN CFNBCF에서 이웃 선정 방법으로 KNN 알고리즘을 사용해 가장 유사한 이웃 k개를 예측에 활용하는 방법. k는 하이퍼파라미터로 일반적으로 k=25~50 정도를 활용한다.
-
UBCF(User-based CF)비슷한 선호도를 가진 유저들을 찾아 그들이 좋아한 아이템을 추천.
타겟 유저와 유사도가 높은 유저들이 선호하는 아이템을 추천한다. -
IBCF(Item-based CF)아이템간 유사도를 계산해 유저가 선호한 아이템과 비슷한 아이템을 추천.
타겟 아이템과 유사도가 높은 아이템 중 선호도가 큰 아이템을 추천한다.
MBCF(Model-Based CF)
머신러닝 알고리즘을 이용해 유저-아이템 매트릭스의 패턴을 모델링하는 방식
-
단순히 항목간 유사성을 비교하는것이 아니라 데이터에 잠재된 유저-아이템 관계의 패턴을 찾아 추천하는 방식
-
대규모 추천 시스템에서 많이 사용되며, 확장성과 성능 면에서 NBCF보다 우수한 성능을 보인다.
-
MF, SVD, 신경망기반, 결정트리기반 등이 있다.
NBCF와 비교한 특징
-
NBCF의 sparsity, scalability 문제를 해결하기 위해 등장.
sparsity ratio가 99.5%가 넘어도 사용이 가능하며, 대규모 데이터셋에서도 효율적으로 작동해 유저와 아이템이 늘어나도 성능이 좋다. -
NBCF가 유저-아이템 벡터를 계산된 형태로 memory에 저장하는 방식이라면, MBCF의 유저-아이템 벡터는 학습을 통해서 변하는 파라미터 형태이다.
-
유저-아이템 데이터는 학습에만 사용되어 모델에 압축된 형태로 반영된다. 그래서 서비스단에서는 이 모델을 그대로 활용하면 되기 때문에
서빙 속도가 빠르다!. 즉, 실시간 추천에 적합하다. -
다만 모델학습에 많은 리소스가 필요하며, 복잡한 모델은 해석이 어렵고, (nbcf에 비해 일반화되긴 했지만) 여전히 과적합 위험이 있다.
-
cold start 문제는 여전히 존재한다.
관련 개념
-
Explicit Feedback : 유저의 선호도를 직접 알 수 있는 데이터
-
Implicit Feedback : 클릭여부처럼 유저의 선호도를 간접적으로 알 수 있는 데이터
Explicit Feedback보다 데이터가 훨씬 많지만 해석이 어렵다.
상호작용이 있으면 1, 없으면 0의 이진 데이터의 행렬로 표현이 가능하다. -
Latent Factor Model (잠재요인 모델)
요즘엔 Embedding이라는 표현으로 많이 사용한다. 유저와 아이템 관계를 잠재 요인을 통해 표현하는 방식. 유저와 아이템을 동일한 차원의 벡터로 표현해 이 벡터의 내적을 통해 평점을 예측한다. 같은 벡터 공간에서 유저와 아이템벡터가 유사하게 임베딩되면 추천될 확률이 높다. 다만 잠재요인이므로 벡터공간의 각 차원이 뭘 의미하는지는 해석하기 어렵다.
SVD (Singular Value Decomposition)
유저-아이템 평점 행렬을 잠재요인을 포함할 수 있는 행렬로 분해하는 모델
선형대수학의 차원 축소 기법을 추천시스템에 적용한 것
Trucnated SVD
특이값이 큰 상위 K(하이퍼파라미터)개만 선택하는 방식. 대표값으로 사용될 것만 사용한다.
fully SVD는 중간행렬 Σ이 mxn이지만, 여기선 k개만 사용하므로 mxk행렬이다.
k의 의미는 latent factor이므로 유추는 가능해도 정확히 알 수 없다.
R을 가장 중요한 정보는 남겨서 요약한 을 만든다.
행렬 분해
- (mxn의 유저-아이템 평점 행렬) = U × Σ × V^T 형태로 분해
- : 유저의 잠재요인 행렬. mxm으로 유저 m명을 k차원으로 분해한 행렬
- : kxk. 잠재요인의 중요도를 나타내면서 특이값을 대각원소로 가지는 행렬. 대각선빼고는 다 0
- : 아이템의 잠재요인 행렬. kxn으로 아이템n개를 k차원 벡터로 분해한 행렬
특징
-
데이터 압축, 계산효율성 향상, 노이즈 제거가 장점
-
결측치를 0이나 평균으로 대체해야되기 때문에 예측이 왜곡되어 sparsity 문제 있음. 새로운 유저-아이템 처리가 어렵다.
MF (Matrix Factorization)
유저-아이템 평점 행렬을 저차원의 두 행렬로 분해하는 기법
- SVD와 비슷하지만 관측된 선호도(평점)만 모델링에 활용한다.
-
P는 유저 matrix, Q는 아이템 matrix. 그안의 벡터들은 모두 학습가능한 parameters로
SGD(확률적 경사하강법)을 통해 오차가 최소화 된다. -
사용자 u의 아이템i에 대한 예측 평점 두 잠재요인 벡터의 내적으로 구한다.
-
Objective Function
학습데이터의 실제 와 두 잠재요인 벡터 내적 의 차이에 L2-정규화를 적용해서 더한 함수를 최소화 한다.
Biased MF
MF에 전체 평균(, 학습x), 유저/아이템의 bias(학습 O)를 추가해 예측 성능을 높인다.
+Confidence
신뢰도를 의미하는 추가. 평점이 정확하지 않거나, 데이터가 implicit feedbacks이면 신뢰도를 추가한다. 신뢰도가 높으면 모델의 파라미터에 더 학습되고, 신뢰도가 낮으면 덜 학습된다.
+Temporal
시간에 따라 변화하는 유저, 아이템의 특성을 반영.
아이템은 시간 지나면 인기가 떨어지고, 유저는 평점 기준이 엄해진다.
학습 파라미터가 시간을 반영할 수 있도록 모델을 설계한다.
MF with Implicit Feedback
-
상세한 논문 요약은 TIL #481 참고
-
ALS(Alternative Least Square)
유저(P)와 아이템(Q) 행렬을 번갈아가면서 두 행렬중 하나를 상수로 두고 다른걸 least square로 업데이트하는 방식. sparse한 데이터면 SGD보다 더 Robust하고, 병렬처리가 가능해 학습이 빠르다.
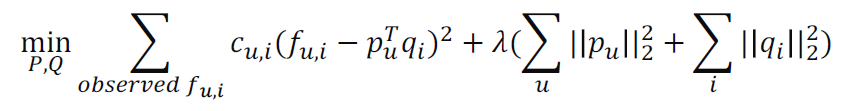
BPR(Bayesian Personalized Ranking)
사용자의 선호도를 직접적인 점수가 아닌, 아이템 간의 상대적인 순위로 학습하는 방식
-
기본 가정
유저는 상호작용한 아이템을 상호작용하지 않은 아이템보다 선호한다
각 유저는 모든 아이템에 대해 자신만의 전체 순위를 가지고 이는 개인화되어있다. -
위의 가정으로 유저가 아이템 A를 아이템 B보다 선호/비선호의 관계를 학습
클릭, 구매와 같은 암묵적 피드백(implicit feedback) 데이터를 활용해 아이템간 선호도를 도출한다. -
MAP를 통해 사후확률(prior)을 최대화하는 파라미터를 찾는데, Bootstrap기반의 LEARNBPR라는 SGD로 파라미터를 업데이트한다.
