Today I Learned
오늘은 종로 네이버 스퀘어에서 오프라인으로 나와서 팀원들과 같이 공부했다.
- Embedding?
주어진 데이터를 저차원의 벡터로 만들어 표현하는 방법
sparse embedding은 원핫인코딩 같은거고, dense하면 벡터 길이를 압축해서 표현한것
- Word Embedding?
텍스트 분석을 위해 단어를 벡터로 표현한 방법. 비슷한 의미를 가진 단어는 임베딩 벡터에서 가까운 위치에 분포한다.
Word2Vec
구글에서 2013년 발표한 NLP모델. 단어를 의미있는 벡터로 변환하는 단어 임베딩 알고리즘
-
기본 아이디어는 주변 단어를 통해 해당 단어를 예측할 수 있다는 가정
-
얕은 신경망(shallow NN)을 사용해 대규모 텍스트 데이터에서 단어의 의미를 학습한다.
-
수백차원의 벡터공간에서 각 단어를 벡터로 표현한다. 의미가 비슷한 단어는 벡터공간에서 가깝게 위치한다.
-
벡터 공간에서 단어 간 벡터의 덧셈과 뺄셈이 의미를 보존할 수 있어 "King - Man + Woman = Queen"과 같은 관계를 나타낼 수 있다.
학습방법
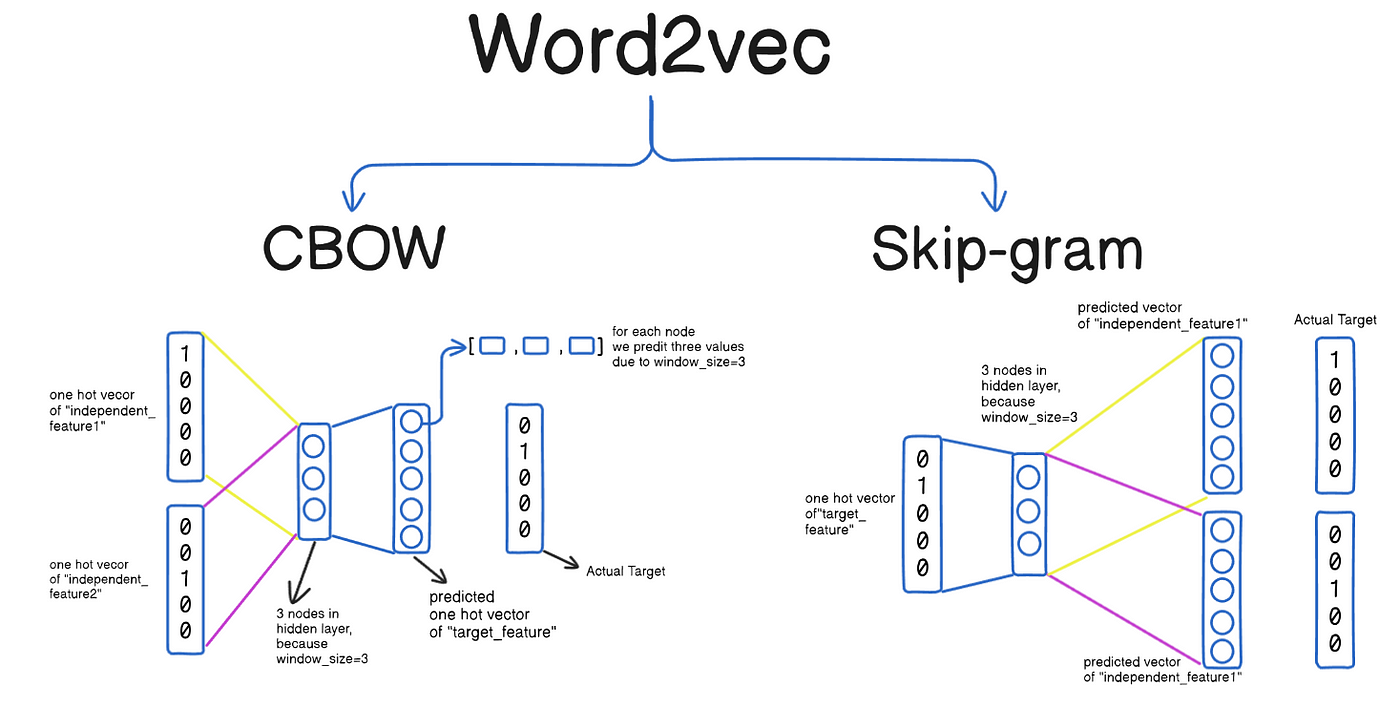 이미지 출처 : medium.com
이미지 출처 : medium.com
-
CBOW
주변 단어들로 중심단어를 예측하는 방법 -
Skip-gram
중심단어로 주변의 단어들을 예측. CBOW보다 계산은 더 필요하지만 성능(표현력)이 좋은편.
 이미지 출처 : jynee
이미지 출처 : jynee
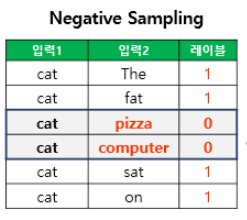
SGNS
기존 Skip-Gram 모델의 계산 효율성을 개선한 방식으로, 전체 단어집합이 아닌 일부 단어집합에만 집중하여 학습하는 방법.
중심단어와 주변에 있으면 1(positive), 관계가 없으면 0으로 binary classification 문제로 바뀐셈이다.
positive 1개당 negative k개가 필요한데, 학습데이터가 크면 2~5, 적으면 5~20을 쓴다.
중심단어를 기준으로 주변 단어들과 내적의 sigmoid를 예측값으로해서 0,1을 분류하고 역전파를 통해 최종 워드 임베딩 2개가 나오는데 선택하거나 평균내서 쓴다.
Item2Vec
Word2Vec의 SGNS개념을 상품(아이템) 추천 시스템에 적용한 알고리즘
-
도메인별로 문장과 단어에 매칭시킬 것들은 세세하겐 다르긴하지만 아래의 패턴이다.
문장 => 유저별 아이템 소비 이력 / 단어 => 아이템 -
유저-아이템 관계를 사용하지 않고 유저별, 세션별 아이템 집합을 사용하기 때문에 유저 식별자가 없어도 세션으로 사용가능하다.
-
집합을 사용하기때문에 시간/공간적 정보는 없다. 그러므로 {a,b,c}라고 치면 모든 부분 조합에 대해 레이블을 만든다.
ANN
Approximate Nearest Neighbor. 대규모 데이터셋에서 효율적으로 최근접 이웃을 찾기 위한 근사 알고리즘
-
brute-force knn방식은 나머지 모든 벡터와 유사도를 비교해야하니 비용이 너무 많이 든다. 그래서 실제 프로덕트 서빙에서 활용하기 힘들다.
-
ANN은 정확한 최근접 이웃을 찾는 대신, 약간의 정확도를 포기하고 검색 속도를 매우 크게 향상시키는 방법. 일반적으로 search space를 줄여 속도를 올리는 방식이다.
-
ANNOY, HNSW, IVF, PQ(Product Quantization), IVF-PQ 등 여러 라이브러리가 있고, acc-speed tradeoff 관계를 생각해서 고르면 된다.
ANNOY
-
Spotify에서 개발한 근사 최근접 이웃 검색 라이브러리
-
랜덤 프로젝션을 사용한 이진 트리 구조 기반
주어진 벡터를 여러 subset으로 나눠서 tree형태로 구성해 탐색한다. -
그렇게되면 리프 노드에 실제 데이터 포인트가 subset의 형태로 저장되어있고, 이를 찾는 데는 O(log N)이면 된다. 같은 subset 안에 속한 벡터들끼리 유사도 계산을해서 최근접 데이터를 찾으면 된다.
-
근접 데이터가 다른 subset에 있는 경우 정확도가 떨어지는데, 트리를 여러개 만들어서 탐색하거나, 근처의 다른 subset까지 탐색하는 방식으로 시간을 좀 소모해서 정확도를 올릴수도 있다.
-
다른 ANN에 비해 가볍고 빠른 구축, 메모리 효율적인 장점이 있지만, gpu연산이 안되고 새로운 데이터를 추가하는 동적 업데이트가 불가능한 단점이 있다.
