241101 TIL #530 AI Tech #63 11주차 주간학습정리 / RecSys with DeepLearning - 1
TIL : Today I Learned
Today I Learned
오늘 배운 내용은 추천 시스템에 딥러닝을 적용한 논문들을 공부했다.
11주차 주간학습정리
일일 학습 정리로 매일 복습, 과제, 피어세션, 회고 정리했고 아래 링크 달았습니다.
팀회고
RecSys with DL
RecSys with MLP
Multi-Layer Perceptron. 여러층의 퍼셉트론으로 이루어진 layer를 이어놓은 feed-foward NN.
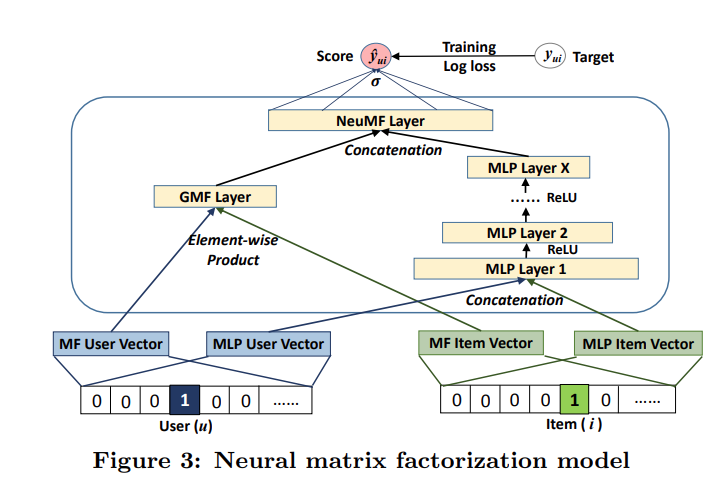
NCF(Neural Collaborative Filtering)
-
MF가 가진 선형결합의 한계를 극복하고자 MLP를 도입.
MLP 층
- input layer : one-hot 인코딩된 유저(아이템)
- Embedding layer : 유저(아이템)의 dense한 latent 벡터
- Neural CF layer : 유저와 아이템 임베딩 레이어를 concat해서 첫 레이어 생성. 그 후 계속해서 feed-foward NN로 x개의 층을 쌓는다.
 이미지 출처 : 위 논문
이미지 출처 : 위 논문
모델
MF층과 MLP층을 각각 만들고 진행시킨 다음 최종 결과물을 concat해서 nueMF 층을 만들고 이를 토대로 나온 예측값 과 타겟(정답) 과의 loss를 줄이기위해 역전파로 파라미터들을 train 한다.
Deep Neural Networks for YouTube Recommendations
-
유튜브 추천 문제의 특징
엄청난 scale, 실시간 추천, 많은 implicit feedbacks, 최신성(freshness) 고려 -
모델보다 데이터 엔지니어링을 통한 도메인 지식을 결합한 부분이 두드러 지는 논문
프로덕트 서빙까지 상세히 설명되어 있다. -
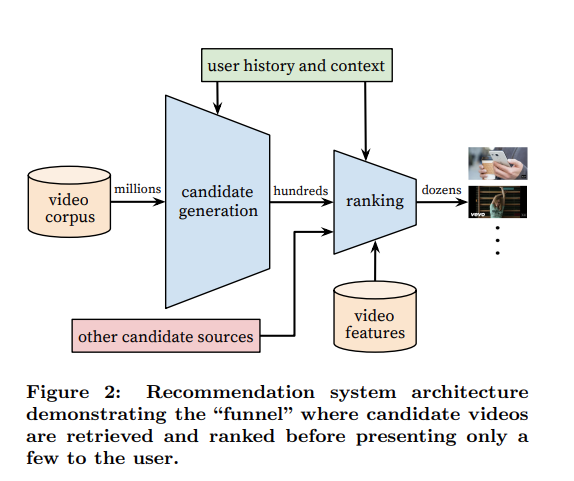
딥러닝 기반 2단계 추천 시스템을 처음으로 제안했다.
 이미지 출처 : 위 논문
이미지 출처 : 위 논문
핵심 아키텍처
-
Candidate Generation
사용자의 시청 기록을 입력으로 받아 수백만개의 영상 중 수백개의 Top N 후보 아이템 생성. 이 과정에서 annoy, faiss같은 ANN 라이브러리를 사용한다. high recall을 목표로 CF를 딥러닝으로 구현했다.
-
Ranking
1에서 만들어진 후보 영상들의 세부 피처와 유저 피처를 좀 더 풍부하게 사용해서 최종 순위 결정한다. 클릭 확률을 구하는 문제기 때문에 logistic 회귀를 사용한다. 하지만 단순 클릭이 아닌 시청시간을 가중치로 한 loss function을 사용한다.
RecSys with AE
Auto Encoder
입력 데이터를 압축(인코딩)했다가 다시 복원(디코딩)하는 비지도 학습 신경망
-
입력 -> 인코더 -> 잠재공간(latent space) -> 디코더 -> 복원
-
데이터의 중요 특성을 자동으로 학습한다.
-
차원 축소와 특성 추출에 활용한다.
-
Denoising Auto Encoder(DAE)
input에 일부러 random noise나 dropout을 넣어서 학습하면, noisy한 input을 더 잘 복원할 수있게 학습되어 robust한 모델이 된다.
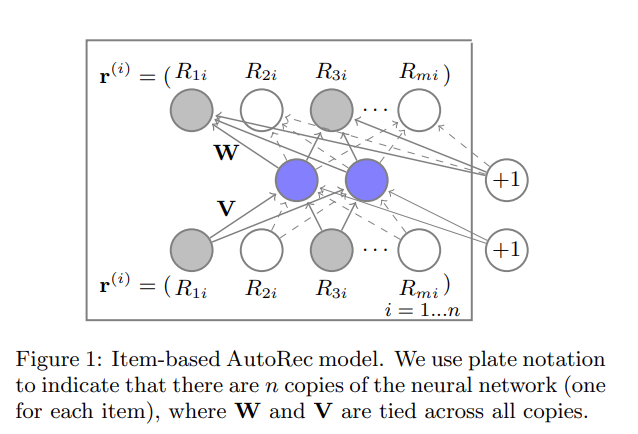
AutoRec
-
AE를 CF에 적용해 CF의 한계를 딥러닝으로 해결하고자 한 논문
-
유저-아이템 Rating 행렬을 입력으로 받아 비선형 변환을 통해 잠재 특성을 학습하고, 이를 통해 누락된 평점을 예측하는 방식
-
MF와 달리 non-linear Activation Function을 사용해 더 복잡한 학습이 가능하다.
-
유저-아이템 평점 벡터가 인코더에 들어가서 가중치 행렬 V와 계산되어 latent vector가 되고, 다시 디코더에 들어가서 가중치 행렬 W와 계산되어 복원된다. 이 과정에서 비선형적인 activation function이 적용된다.
-
기존의 rating과 예측값의 RMSE를 최소화하는 방향으로 학습하면서 역전파를 수행해 파라미터를 업데이트 한다.
CDAE
-
DAE를 CF에 도입해서 Ranking을 통해 Top-N을 추천하는 모델
(AutoRec은 Rating Prediction 모델) -
input으로 유저-아이템 rating이 아니라 preference를 사용하고, q의 확률에 의해서 input의 일부를 dropout해서 0으로 만들어 noise를 추가한다.
-
그리고 개별 유저에 대한 특징 를 파라미터가 추가로 학습한다.
