Today I Learned
오늘은 RecSys와 관련된 주요 연구들에 대해 공부했다.
RecSys 주요 연구
State-of-the-Art(SOTA) 연구의 근간이 되는 중요 논문
Matrix Factorization Revisited
Collaborative Filtering for Implicit Feedback Datasets
-
Implicit Feedback을 위한 MF
-
TIL #481 참고
BPR
-
사용자가 선호하지 않는 아이템과 아직 접하지 않은 아이템이 둘다 0으로 섞여버리는 문제를 해결
-
implicit feedback을 활용해 사용자의 아이템 선호도를 순위로 예측한다.
-
사용자의 아이템 선호도를 두 아이템간 pairwise-ranking 문제로 바꿔서 사용자가 아이템 i를 아이템 j보다 선호하는 확률을 모델링한다. 이 확률은 시그모이드 함수를 이용해 계산한다. 관측되지 않은 아이템에도 정보를 부여해 순위를 추론할 수 있다.
-
사용자 별 positive와 negative 아이템 간의 compatibility 차이를 계산해 개인화된 pairwise(2 items) ranking을 찾는다.
FPMC
Factorizing Personalized Markov Chains
-
MF에 MC(마르코프체인)을 결합한 모델. 마르코프 체인은 시퀀스 데이터에서
바로 직전 상태에만 영향을 받는성질을 가진다. -
유저-아이템 관계 f(u,i)와 아이템-(바로 이전)아이템 관계 f(i,)도 모델링한다. MF를 통해 유저-아이템 간 장기적 선호도를 추정하고, MC를 통해 아이템 간 전이 관계를 모델링해 바로 직전 아이템기반의 추천을 모델링한다.
-
각 유저별로 개인화된 형태의 MC가 있다.
ex) 명수는 코메디 다음 판타지를 볼 확률이 높고, 재석은 코메디 다음 코메디를 계속 볼 확률이 높다. -
f(i|u,j) = u와 i의 compatibility + i와 j의 compatibility (+ u와 j의 compatibility이긴한데 최적화 과정에서 사라짐)
u=유저 / i=지금 아이템 / j=이전 아이템
PRME
Personalized Ranking Metric Embedding
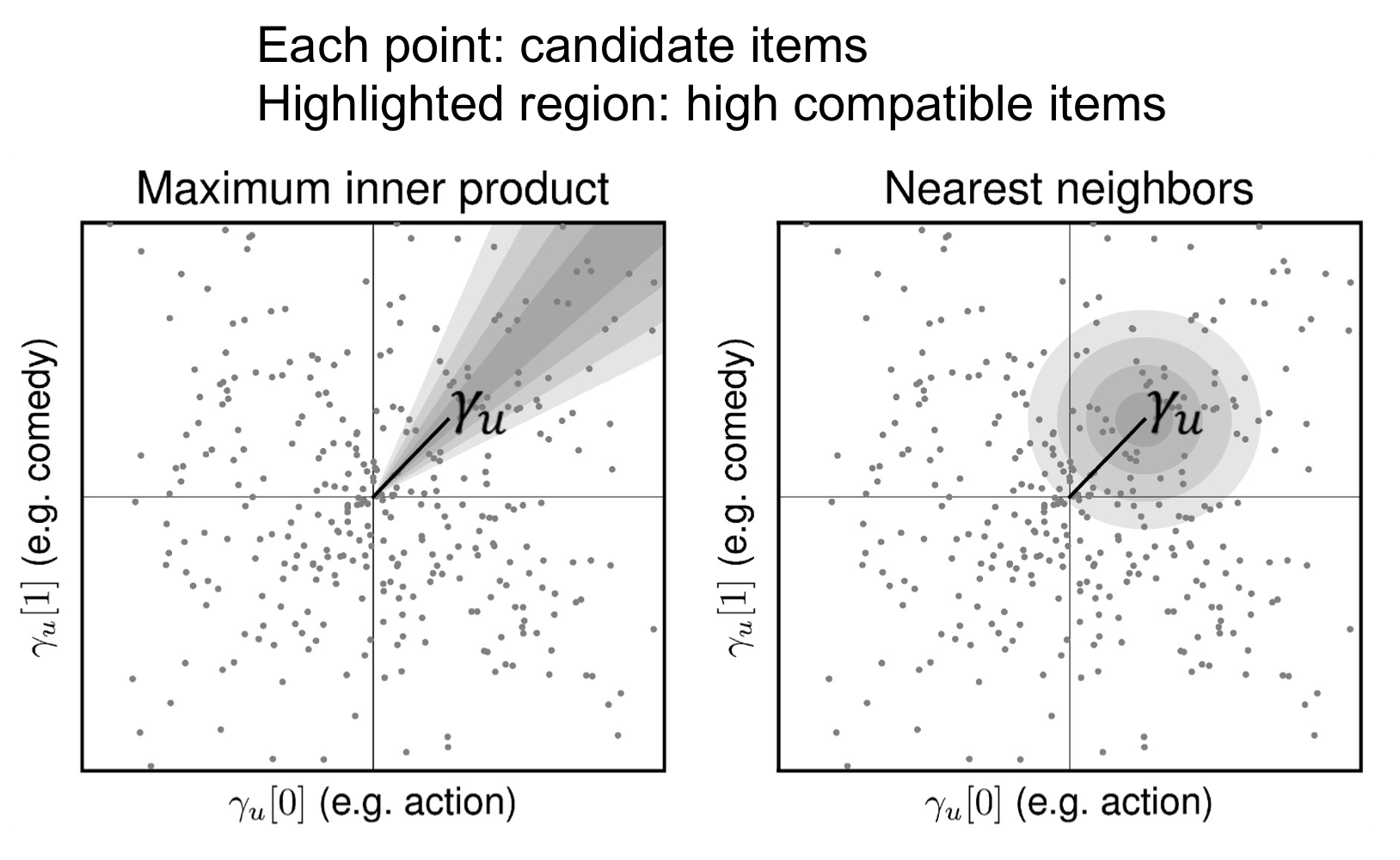 이미지 출처 : 논문
이미지 출처 : 논문
-
FPMC와 유사하지만 compatibility function으로 내적을 사용하지 않고 distance metric을 사용한다. 유저와 아이템을 저차원 유클리디안 공간에 임베딩하는 방식을 사용.
-
유저의 장기적 선호도를 표현하는 공간과 아이템간 순차적 관계를 표현하는 전이공간 2가지로 공간을 임베딩한다. 두 공간에서 거리를 결합해 최종 선호조 점수를 계산한다. 가중치 파라미터 α로 두 공간의 중요도를 조절한다.
-
파라미터 수가 적어 학습이 효율적이며 계산 복잡도가 낮다. 직관적인 기하학적 해석이 가능하고 일반화 성능이 좋다.
-
위의 그림에서 처럼 내적방식은 방향이 비슷하면 그 극한까지 추천하는 반면, 거리기반은 방향을 고려한 상황에서 거리를 찾으므로 취향과 비슷하게 추천이 가능하다. 이러한 특징 때문에 지도 추천, 음악 추천 같은 곳에서도 잘 쓰인다.
RecSys 평가 지표
-
Rating Prediction 문제는 일반적으로 explicit feedback을 예측하므로 명시적인 정보가 있어 RMSE 같은 명확한 real-value 기반의 지표를 사용한다.
-
반면에 top-k ranking 문제는 0/1의 binary로 이뤄진 implicit feedback을 예측하므로 사용자의 선호에 대해 모호한 정보만 제공된다.
-
top-k ranking문제 관련 지표는 TIL #526 참고
RecSys 학회
-
RecSys 관련 Major Conferences: RecSys, KDD, WWW, WSDM, ICDM, CIKM, SIGIR, AAAI, IJCAI, ICML, NeurIPS, ICLR
-
일반적인 AI/ML 학회 이외에도 web이나 data mining 학회에서도 RecSys는 연구결과가 나오기도 한다.
RecSys Datasets