Today I Learned
오늘 배운 내용은 추천시스템의 평가 방법!
RecSys Evaluation
평가 방법
- 추천 시스템의 평가 방법은 사용자 스터디, on-line 평가, off-line 평가로 크게 3가지로 분류할 수 있다.
1. 사용자 스터디
사용자를 직접 모집하여 시스템과 상호작용하게 한 후 피드백을 수집하는 방식
-
적극적인 사용자만 참여하게 되어 편향이 발생할 수 있다.
-
많은 시간과 비용이 소요되어 현실적으로 적용이 어렵다.
2. 온라인 평가
-
실제 서비스 환경에서 A/B 테스트 형태로 진행된다.
-
사용자들의 실제 반응을 수집해 비교 평가한다.
-
개발, 배포에 이르기까지 시간과 트래픽이 많이 요구된다.
3. 오프라인 평가
-
이미 수집된 과거 데이터를 활용하여 알고리즘 성능을 평가
-
RMSE, Precision, Recall, Accuracy 등 정확도 중심의 지표 사용하는데, 실제 추천의 효용을 잘 반영하는가에 대한 논란의 여지는 있다.
-
실제 사용자 트래픽 없이도 테스트 가능한 장점이 있지만, 시간에 따른 선호도 변화를 반영하기 어렵다.
-
실제 서비스 적용 전 기본 성능 검증 용도로 활용된다.
평가 지표
-
Accuracy : TIL #526 참고
광고분야에서는 가격 같은 요소를 추가로 고려해 profit 최대화를 하기도 한다.
하지만 유저가 체감하는 recsys의 실제 효용을 반영하는지 불명확하다. -
Coverage : 추천시스템이 얼마나 다양한 아이템을 추천할 수 있는 지를 나타내는 지표
일반적으로 Accuracy와 trade-off 관계 -
Confidence : 추천 시스템의 신뢰성. 예측 평균이 같더라도 표준편차가 적은 추천시스템이 더 confidence하다
-
Trust : 유저가 추천 결과에 대해 가지고 있는 믿음. explaination이 있으면 더 믿기 쉽다.
-
Novelty : 유저가 잘 모르거나 이전에 몰랐던 새로운 추천을 할 가능성.
-
Serendipity : lucky discovery. novelty(몰랐던것) + 예상치 못함 + 연관성
-
Diversity : 추천 결과가 얼마나 다양한 아이템으로 이루어졌는지 나타냄
-
Robustness : RecSys에 가해지는 적대적인 공격에 대한 견고함
-
Scalability : 대용량의 데이터나 트래픽을 얼마나 효과적으로 처리할 수 있는지 평가
데이터 분할 전략
offline 평가, accuracy 지표 상 실험에서 사용할 수 있는 데이터 분할 전략
-
train / valid / test로 데이터를 겹치지않게 분할해야 한다.
-
추천시스템은 NLP, CV 분야에 비해 데이터 분할 전략이 표준화되어있지 않아 잘 설계해야 한다.
-
결국 예측해야 하는 것은 미래에 사용자가 좋아할 만한 아이템이므로 timestamp를 잘 고려해서 분할해야 한다. 학습시에는 미래 데이터 절대 포함 x
-
분할 전략에 따라 모델 성능이 변한다.
Leave One Last
-
시간순서대로 나열 후 마지막을 test, 마지막 직전을 valid, 나머지를 train으로 분할
-
train은 최대화되지만 test가 하나밖에 없어 성능 평가가 충분히 되지 않을 수 있다.
Temporal Split
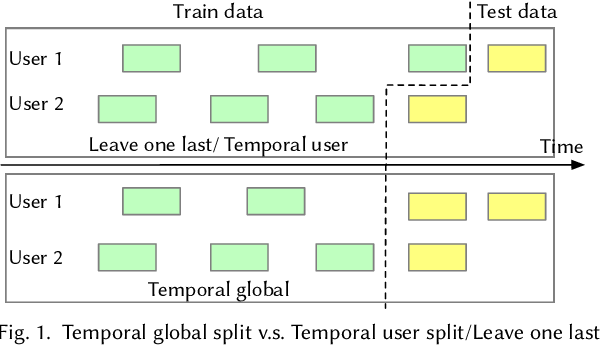 이미지 출처 : Exploring Data Splitting Strategies for the Evaluation of Recommendation Models
이미지 출처 : Exploring Data Splitting Strategies for the Evaluation of Recommendation Models
-
현실과 비슷하지만 학습에 사용되는 데이터가 적다.
-
user split : 유저별 시간 순서에 따라 interaction 나열하고 8:1:1 같은 일정 비율로 분할
-
global split: 유저별 시간 순서에 따라 interaction 나열하고 고정된 시점 이후를 test, 나머지를 일정비율에 따라 train과 valid로 구분.
현실적인 평가를 위해 최근에 많이 쓰이는 방법
Random Split
-
각 유저별로 interaction을 random하게 시간을 고려하지 않고 분할
-
사용하기 쉽고 학습데이터가 많지만 재현이 불가능할 수 있다.
User Split
-
시간별 아이템이 아니라 사용자를 train/valid/test로 분할하는 방법
-
cold-start 문제에 대처가 가능하다. 하지만 학습된 모델이 새로운 유저에 대해 추천 결과를 생성할 수 있을 때만 평가가 가능해 많이 사용하지는 않는다.
