Today I Learned
오늘은 CV에 대해 공부했다!
주간학습정리
학습 정리로 월~금 동안 매일
복습, 과제, 피어세션, 회고 정리했고 아래 링크 달았습니다.
CV
Computer Vision. 컴퓨터가 디지털 이미지와 비디오를 통해 시각적 세계를 이해하고 해석할 수 있도록 하는 인공지능의 한 분야
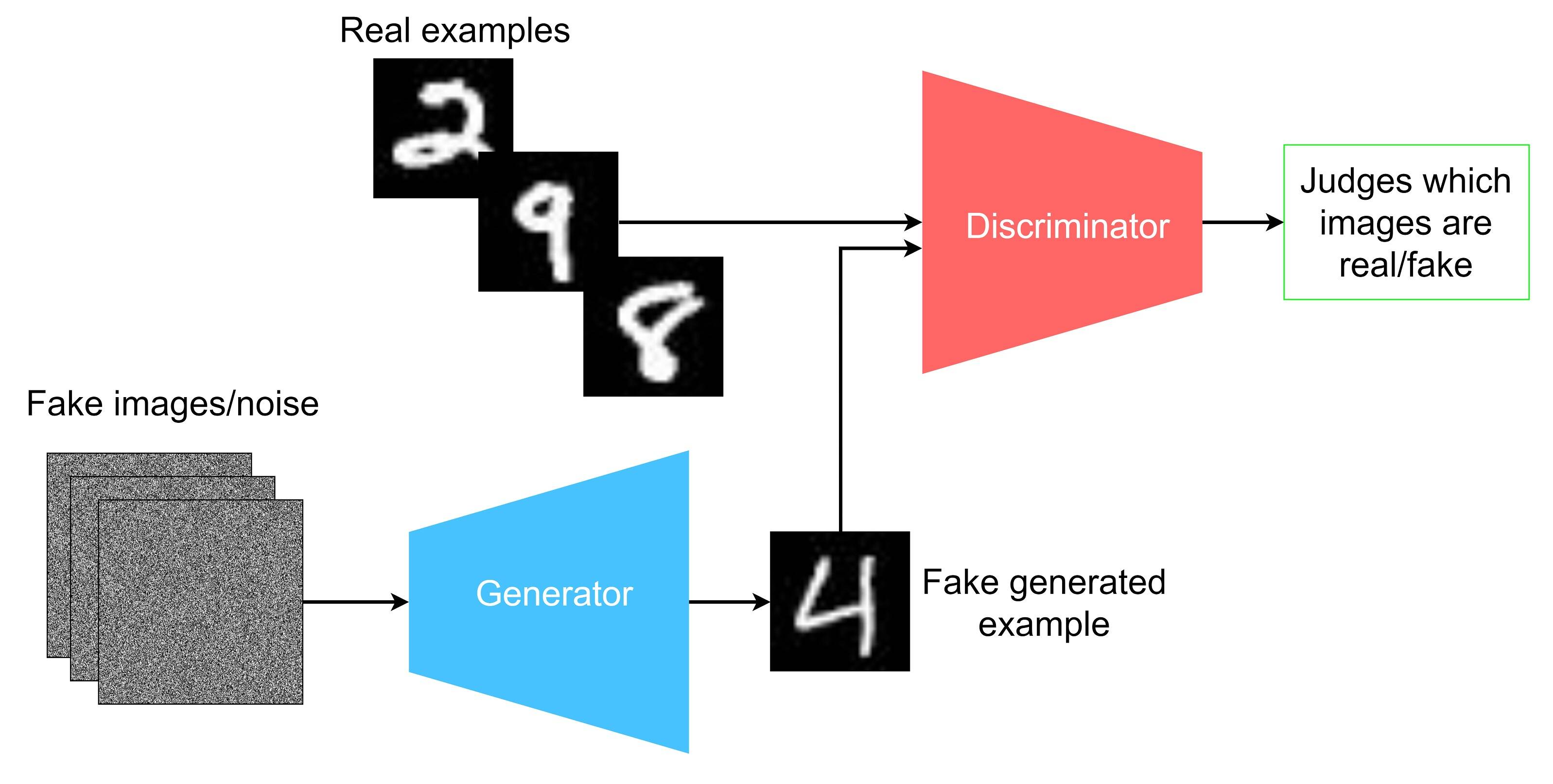
GANs
Generative Adversarial Networks.
생성자와 판별자, 두개의 적대적 신경망을 이용해 이미지를 생성하는 모델
 이미지 출처 : ibm
이미지 출처 : ibm
-
Generator: 생성자. 잠재 변수 z를 입력으로 받아 학습 데이터의 분포에 가까운 이미지를 생성
Discriminator: 판별자. 입력된 데이터가 실제인지 가짜인지 구별하는 역할
두 신경망이 서로 경쟁하면서 발전하는 구조 -
Generator 목적함수 : minimization
-
Discriminator 목적함수 : maximization
-
전체 목적함수 : min G max D
-
장점
실제 데이터와 유사한 이미지 생성이 가능하다.
적은 데이터로도 좋은 성능을 얻을 수 있다.
다양한 종류의 데이터를 생성할 수 있다. -
단점
학습이 불안정하고 수렴하지 않는 경우가 많다.
두 신경망 간의 균형을 잡기가 어렵다.
결과물의 다양성이 부족하거나 특정 패턴에만 치우치는 현상이 발생한다.
하이퍼파라미터에 매우 민감하고 구현과 학습과정이 복잡하다.
종류
cGAN
-
conditional GAN. 기존 GAN에 조건부 정보를 추가한 모델.
-
G와 D에 추가정보 y를 입력으로 넣는다.
-
목적함수 : x 대신 조건부 x|y를 사용
Pix2Pix
-
이미지를 다른 형태의 이미지로 변환하는 GAN의 한 종류
-
입력 이미지를 받아 다른 도메인의 이미지로 변환한다.
-
기존 GAN과 달리 노이즈 벡터를 사용하지 않는다.
대신 서로 매칭되는 paired image가 학습에 필요하기 때문에 이미지 확보가 어렵다.
CycleGAN
-
pix2pix가 paired image가 필요한 단점을 개선
-
cycle consistency loss를 제안했다.
consistency - 결과물의 일관성 / contrastive - 다른 결과물과 멀어지도록 하는 것 -
unpaired image를 학습하기 위해 두개의 G와 D를 학습에 사용한다.
StarGAN
-
cycleGAN은 도메인 별 생성모델이 많이 필요해 학습 효율성이 떨어지는데, 이를 개선하기 위해 단일 생성모델만으로도 여러 도메인을 반영할 수 있는 StarGAN이 등장
-
기본 GAN 함수, 도메인 판단함수, cycle consistency loss까지 3가지 목적함수를 사용한다.
ProgressiveGAN
-
고해상도 이미지를 만들기 위해 저해상도 이미지 생성 구조부터 단계적으로 증강하는 모델
-
적은 비용으로도 빠른 수렴이 가능하다.
StyleGAN
-
ProgressiveGAN에서 style을 주입하는 방법
-
잠재공간 z를 바로 사용하지 않고 mapping network인 f를 사용해 변환된 w를 입력으로 쓴다.
Autoencoder
 이미지 출처 : dataplay
이미지 출처 : dataplay
-
인코더(g)와 디코더(f)로 구성되어 입력 이미지를 다시 복원하도록 학습하는 모델
-
인코더 : input을 저차원 잠재 공간(latent space)으로 매핑해 잠재변수 z로 변환
(z는 반드시 입력데이터 x보다 차원이 낮아야한다)
디코더 : z를 입력으로 사용해 원본 이미지를 복원 -
목적 함수 : 원본과 재구축본의 차이를 최소화하는 reconstruction loss. 주로 MSE나 MAE를 사용한다.
(는 g의 파라미터, 는 f의 파라미터) -
장점
입력 데이터를 압축하고 재구성하는 비지도 학습 방식이라 레이블이 없어도 학습 가능
자동으로 특징을 추출해서 학습
비선형 특징 추출 가능
데이터 압축과 특징 추출을 동시에 수행 -
단점
과적합 위험이 있고 모델 해석이 어렵다.
새로운 데이터에 대한 일반화 능력이 제한적이다.
데이터 압축 과정에서 정보 손실이 발생할 수 있다.
종류
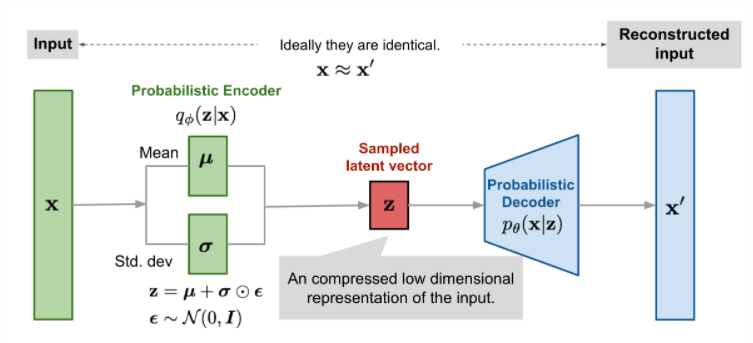
VAE
 이미지 출처 : gaussian37
이미지 출처 : gaussian37
-
Variational Autoencoder.
-
AE와 동일하게 인코더 디코더로 구성되어있지만, 잠재공간의
분포(일반적으로 가우시안)를 가정해서 학습한다. 잠재공간 z가 가질 수 있는 평균, 분산, 편차(noize)를 학습한 다음 z를 샘플링해서 그걸 토대로 디코더가 이미지를 생성. -
이를 위해 KL divergence를 함께 정의한다.
VQ-VAE
-
Vector Quantized-Variational Autoencoder
-
기존 VAE에서 연속적인 잠재공간이 아니라 이산적인 잠재공간을 가정해서 학습에 사용한다.
-
인코더: 입력 데이터를 잠재 벡터로 변환
코드북: 이산적인 코드 벡터들의 집합. 코드북도 학습이 된다.
디코더: 양자화된 벡터를 원본 데이터로 복원 -
이산적인 잠재공간은 이미지, 텍스트, 음성같은 데이터에 적합하다.
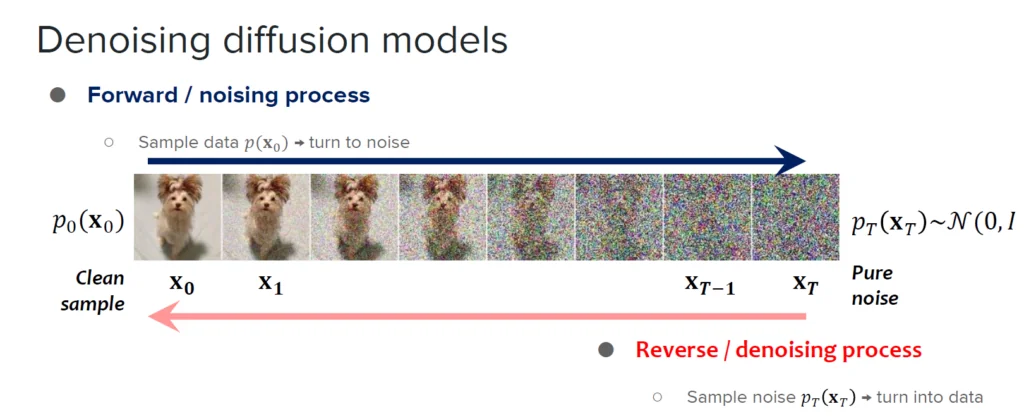
Diffusion Models
데이터에 점진적으로 노이즈를 추가하고 제거하는 과정을 통해 새로운 데이터를 생성하는 생성 모델
-
순방향 과정 (Forward Process)
실제 데이터에 점진적으로 노이즈를 추가
데이터가 순수한 노이즈로 변환될 때까지 진행 -
역방향 과정 (Reverse Process)
노이즈로부터 원본 데이터를 단계적으로 복원
신경망을 통해 노이즈를 점진적으로 제거 -
장점
고품질의 이미지 생성 가능
GAN보다 안정적인 학습 과정
다양한 출력 생성 가능
모드 붕괴(Mode Collapse) 문제 해결 -
단점
이미지 생성에 많은 시간 소요
높은 컴퓨팅 리소스 요구
학습과 생성 과정이 복잡
종류
DDPM
-
Markov Chain을 기반으로 한 확률 모델
-
가우시안 노이즈를 사용하여 데이터를 점진적으로 변형
-
신경망을 통해 노이즈 제거 과정을 학습
DDIM
-
Denoising Diffusion Implicit Models
-
DDPM에서 process 단계는 step 수가 많아 이미지 생성에 시간이 많이 걸리지만, DDIM은 이를 개선해 확률적 process를 Deterministic sampling process로 non-Markovian diffusion process을 일부 과정에서 도입해 속도를 개선했다.
CFG
-
Classifier Guidance는 GAN보다 더 나은 fidelity(데이터 품질)을 얻기위해 모델 구조를 업데이트하고 DDIM에 Classifier Guidance를 활용해 SOTA 달성
-
backward process에 데이터에대한 likelihood가 높아지는 방향을 제시한다. class y를 조건부로 주입한다.
-
모든 스텝에 classifier가 필요하고 복잡해지는 단점이 있다.
-
그래서 등장한 것이 Classifier-free Guidance.
classifier에 대한 학습 없이 class에 대한 guidance를 가중치 w로 조정한다.
