Physical Intelligence의 open-source VLA 모델 논문 π0 : A Vision-Language-Action Flow Model for General Robot Control (2024) 읽어보기
I. INTRODUCTION
1. 연구 배경
-
Specialization to Versatility
현재의 AI 시스템은 단백질 구조 예측이나 이미지 생성 등 특정 영역에서는 인간을 뛰어넘지만, 인간 지능의 핵심인 물리적 세계에서의 범용성(Versatility)은 여전히 부족하다.LLM이나 VLM이 보여준 혁신은 웹 규모의 거대한 데이터로 사전 학습(Pre-training)을 수행한 덕분이었다. 본 논문은 로봇 또한 추상적인 설명이 아닌, 실제 로봇(Embodied agent)으로부터 얻은 방대한 데이터로 학습해야만 진정한 물리적 상호작용 능력을 갖출 수 있다고 주장한다.
2. 핵심 철학
본 논문은 로봇 학습에서 사전 학습(Pre-training)이 왜 중요한지를 다음과 같이 비유한다.
"새를 인식하는 모델을 만들 때, 처음부터 새 사진만 가지고 학습하는 것보다 다양한 이미지로 사전 학습된 모델을 가져와서 새 인식용으로 미세 조정(Fine-tuning)하는 것이 훨씬 효율적이다."
이와 마찬가지로, 특정 로봇 작업을 수행할 때 바닥부터(Scratch) 가르치는 것보다, 다양한 로봇과 작업 데이터로 사전 학습된 '일반화된 모델'을 기반으로 시작하는 것이 데이터 부족과 일반화(Generalization) 문제를 해결하는 열쇠다.
3. 제안 방법론
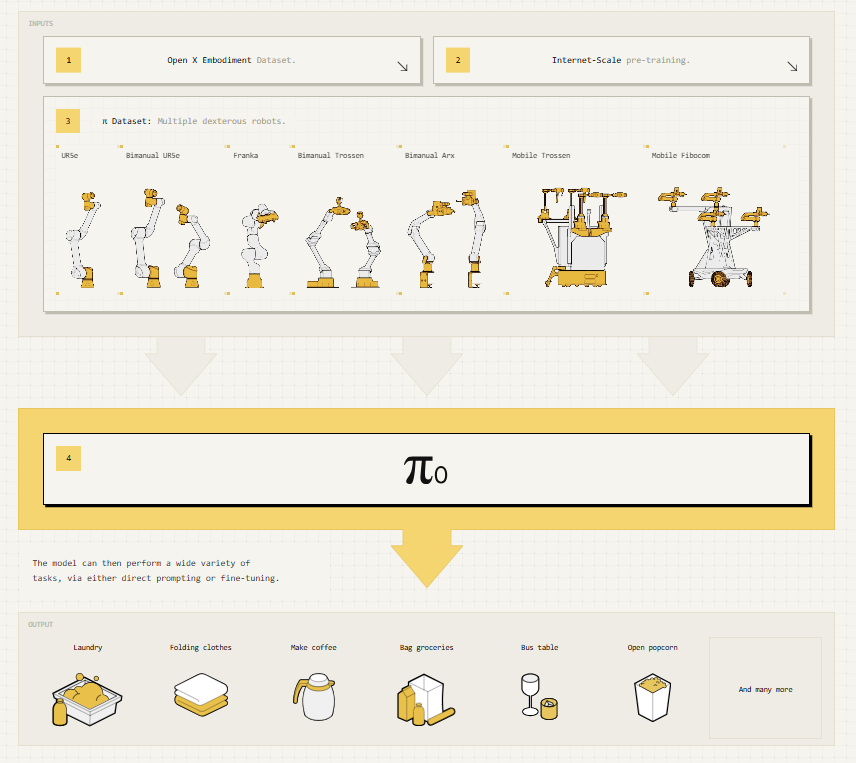
본 논문은 로봇 학습의 3가지 병목(규모, 아키텍처, 학습 레시피)을 해결한 로봇 파운데이션 모델, 를 제안한다.
-
Architecture: 사전 학습된 VLM 백본 위에 플로우 매칭(Flow Matching) 기반의 액션 전문가(Action Expert) 모듈을 결합했다. 이를 통해 인터넷의 방대한 의미론적 지식을 상속받으면서도, 50Hz의 고속 로봇 제어를 실현한다.
-
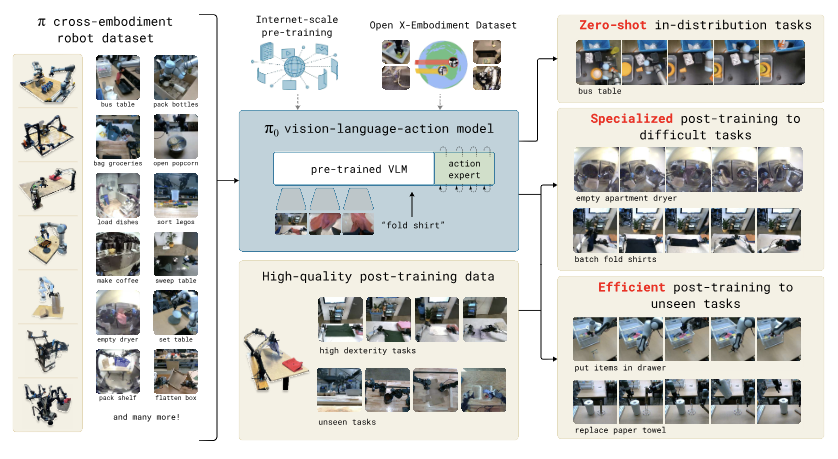
Cross-Embodiment Data : 단일 로봇 팔, 양팔 로봇, 모바일 매니퓰레이터 등 7가지의 서로 다른 로봇 형태(Embodiment)에서 수집한 데이터를 통합하여 학습한다.
-
Training Recipe : LLM 학습처럼 '사전 학습(Pre-training)'과 '사후 학습(Post-training)' 단계를 명확히 분리하여 적용한다.
Training Strategy : 왜 사전 학습과 사후 학습을 나누는가?
단순히 데이터를 많이 섞는 것이 능사가 아니다. 본 논문은 데이터의 질(Quality)과 다양성(Diversity)에 따른 상충 관계(Trade-off)를 해결하기 위해 단계를 분리한다.
- 고품질 데이터만 학습 시: 모델이 성공하는 경로만 보게 되므로, 실수했을 때 복구(Recovery)하는 방법을 모른다.
- 저품질(다양한) 데이터만 학습 시: 다양한 상황 대처 능력은 생기지만, 동작이 비효율적이거나 굼뜬 움직임을 보인다.
- 결합의 시너지: 따라서 는 다양한 데이터로 진행하는 사전 학습을 통해 '실수 회복 능력(Robustness)'을 배우고, 고품질 데이터로 진행하는 사후 학습을 통해 '숙련된 기술(Dexterity)'을 입히는 전략을 취한다.
II. RELATED WORK
본 섹션에서는 가 기존 로봇 학습 방법론들과 차별화되는 세 가지 핵심 축(모델링 방식, 아키텍처 통합, 데이터 규모 및 복잡성)에 대해 설명한다.
1. 기존 VLA 모델과의 차별점
이산화(discretization)에서 연속체(continuous)로 !
기존 VLA 모델(RT-2, OpenVLA 등)은 로봇 제어 방식에 근본적인 한계가 있었다.
-
기존 접근법 (Autoregressive)
: 로봇의 행동(Action)을 언어처럼 이산적인 토큰(Discrete Tokens)으로 취급하여, 다음 행동을 단어 예측하듯이 생성하는 자기회귀(Autoregressive) 방식을 사용했다. -
의 혁신 (Flow Matching)
: 반면 는 행동을 연속적인 값(Continuous Values)으로 처리한다. 이를 위해 확산 모델(Diffusion)의 진화형인 플로우 매칭(Flow Matching) 기법을 도입했다. 이로써 이산화 과정에서의 정보 손실을 없애고, 기존 모델들이 어려워했던 50Hz의 고주파 제어(High-frequency control)와 미세하고 정교한 조작(Dexterous tasks)을 가능하게 한다.
2. Diffusion 기반 정책과의 통합
기존의 Diffusion Policy은 행동 생성 능력은 탁월했으나, 대규모 언어 모델의 지식을 활용하지 못하는 단점이 있었다.
-
의 접근
: 는 사전 학습된 거대 VLM 백본(Backbone) 위에 플로우 매칭(Flow Matching) 헤드를 결합하는 하이브리드 방식을 취한다. -
기술적 특징 (Transfusion의 응용)
: 이미지/텍스트 생성 모델의 최신 기법인 Transfusion(트랜스퓨전)을 로봇 제어에 맞게 변형하였다. 특히, 텍스트 처리와 달리 로봇 액션 처리를 위해 별도의 가중치 집합인 '액션 전문가(Action Expert)'를 두어, VLM의 의미론적 지식과 로봇의 운동 제어 능력을 동시에 확보했다. 이는 고주파 액션 청크(Action Chunks)를 생성하는 최초의 VLA 모델이다.
Transfusion이란?
→ Transformer와 Diffusion을 합침 ! (Transformer + Diffusion) [논문]
1. 핵심 아이디어
- 목적 함수의 이원화 (Hybrid Objectives)
기존 멀티모달 모델들은 텍스트와 이미지를 억지로 동일한 방식으로 학습시키려 했다. 그러나 Transfusion은 "모달리티마다 최적의 학습 방식이 다르다"는 점을 인정하고, 단일 트랜스포머(Transformer) 아키텍처 내에서 각 데이터 특성에 맞는 최적의 목적 함수(Objective)를 병렬적으로 적용한다.
- 텍스트 (Discrete): 다음 토큰을 예측하는 자기회귀(Autoregressive) 방식과 Cross-Entropy Loss를 사용한다.
- 이미지 (Continuous): 노이즈를 제거하며 원본을 복원하는 확산(Diffusion) 방식과 Diffusion Loss를 사용한다.
2. 주요 특징 (Key Features)
- 통합 시퀀스 처리 (Integrated Sequence Processing): 텍스트 토큰과 이미지 패치를 하나의 긴 시퀀스로 연결하여 처리한다. 이때 어텐션 메커니즘(Attention Mechanism)을 통해 모달리티 간 정보 흐름을 정교하게 제어함으로써, 상호작용(Interaction)을 학습하면서도 각 모달리티의 고유한 특성(Independence)을 유지한다.
- 트랜스포머 내부의 확산 (Diffusion in Transformer): 별도의 확산 모델(UNet 등)을 두지 않고, 트랜스포머가 직접 이미지의 노이즈 제거 과정을 수행하도록 통합했다. 이는 이미지 데이터를 벡터화(Vector Quantization 등)하여 처리하되, 생성 과정은 반복적인 디노이징(Iterative Denoising)을 따르게 한다.
3. 기존 방법론과의 비교 (Comparison)
Transfusion은 기존의 두 가지 주류 접근법이 가진 한계를 극복하고 장점만을 취합한 중간 지점(Middle Ground)에 위치한다.
- vs. 통합 모델 (예: Chameleon): 모든 모달리티에 'Next-token prediction'을 적용하면 구현은 단순하나, 이미지 생성 품질이 확산 모델에 비해 떨어진다.
- vs. 앙상블 모델 (Ensemble): LLM과 확산 모델을 각각 학습시켜 붙이면 성능은 좋으나, 모델 크기가 비대해지고 모달리티 간의 심층적인 상호작용을 학습하기 어렵다.
→ Transfusion: 단일 모델의 효율성과 모달리티별 최적화(Diffusion)를 통한 고품질 생성을 동시에 달성한다.
4. 학습 및 추론 과정 (Training & Inference)
학습 (Training): 입력 시퀀스 내에서 데이터의 종류(텍스트 vs 이미지)를 구분한다. 텍스트 부분은 LM Loss, 이미지 부분은 Diffusion Loss를 계산한 뒤, 두 손실 함수를 가중 합산(Weighted Sum)하여 모델 전체를 End-to-End로 학습시킨다.
추론 (Inference): 생성 시에는 모달리티에 따라 작동 모드를 전환한다. 텍스트는 순차적으로 생성(Autoregressive)하고, 이미지는 노이즈를 점진적으로 제거(Denoising)하며 생성한다.
5. 의의 (Significance)
Transfusion은 이질적인 데이터(텍스트, 이미지, 오디오, 비디오 등)를 억지로 하나의 방식에 끼워 맞추지 않고도, 단일 아키텍처에서 효과적으로 통합할 수 있음을 증명했다. 이는 향후 진정한 의미의 범용 멀티모달 파운데이션 모델(General-purpose Multimodal Foundation Model)을 구축하는 데 있어 중요한 방향성을 제시한다.
3. 데이터 규모와 작업의 복잡성 (Scale & Complexity)
단순히 데이터 양만 늘린 것이 아니라, 해결하고자 하는 문제의 난이도를 획기적으로 높였다.
-
기존 데이터셋의 한계
: 초기 연구는 단순한 '집기(Grasping)'나 '밀기(Pushing)'에 그쳤고, 최근의 Open X-Embodiment (OXE) 데이터셋 또한 다양한 로봇을 포함하지만 주로 낮은 난이도의 작업 위주였다. -
압도적인 규모
: 본 연구는 약 10,000시간 분량의 데모 데이터를 사용하여, 정교한 조작(Dexterous manipulation)을 위한 역사상 최대 규모의 로봇 학습 실험을 수행했다. -
조합적 복잡성 (Combinatorial Complexity)
: 단순히 손놀림만 좋은 것(예: 신발 끈 묶기)을 넘어, 세탁물 접기(Laundry folding)나 테이블 치우기(Table bussing)처럼 긴 시간 동안 판단과 정교한 동작이 복합적으로 요구되는 장기 작업(Long-horizon tasks)을 수행한다는 점에서 기존 연구들을 뛰어넘는다.
III. OVERVIEW
본 섹션에서는 모델의 전체적인 학습 프레임워크와 데이터 구성 전략을 개괄한다. 본 연구의 접근 방식은 인간의 학습 과정과 유사하게, '광범위한 기초 교육(Pre-training)'과 '전문화된 직무 교육(Post-training)'의 2단계로 나뉜다.
1. Two-Stage Training Framework
: LLM의 성공 방정식을 로봇 학습에 적용하여, 모델의 일반화 능력과 전문성을 동시에 확보한다.
-
1단계: 사전 학습 (Pre-training)
- 목표: 특정 작업을 완벽하게 해내는 것보다, 다양한 환경과 로봇 형태를 경험하며 폭넓은 일반화(Generalization) 능력과 기초적인 물리 법칙을 습득하는 데 초점을 둔다.
- 데이터: 자체 수집한 데이터와 오픈 소스 데이터(OXE)를 혼합한 거대한 '사전 학습 혼합물(Pre-training Mixture)'을 사용하여 세상에 대한 전반적인 이해도를 높인다.
-
2단계: 사후 학습 (Post-training)
- 목표: 사전 학습된 '일반형 두뇌'를 바탕으로, 세탁물 접기나 상자 포장 등 특정 작업(Target Task)에 대해 전문성(Specialization)을 갖추도록 튜닝한다.
- 데이터: 해당 작업에 대해 고품질로 엄선된(Curated) 데이터만을 사용하여 미세 조정(Fine-tuning)을 수행, 동작의 유려함과 성공률을 극대화한다.
2. 데이터 구성 전략 (Data Composition)
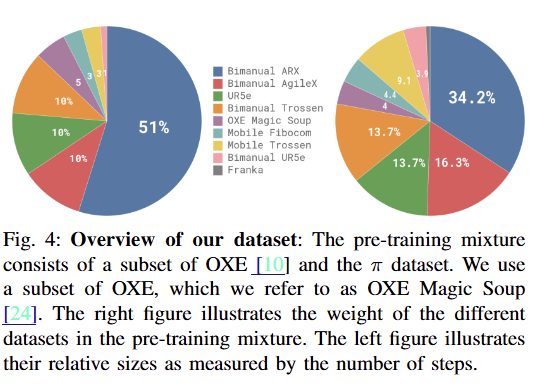
학습에는 로봇 학습 역사상 최대 규모인 약 10,000시간 분량의 데이터가 투입되었다. 이는 크게 오픈 소스와 자체 수집 데이터로 나뉜다.
-
오픈 소스 데이터 (약 9.1%):Open X-Embodiment (OXE) 데이터셋 등을 포함한다. 주로 2~10Hz의 저주파(Low-frequency) 제어 데이터로, 간단한 이동(Pick & Place) 작업 위주라 복잡한 동작을 배우기에는 한계가 있다.
-
자체 수집 데이터 (약 90.9%): Physical Intelligence 사에서 직접 수집한 데이터로, 약 9억 3백만(903M) 타임스텝에 달하는 압도적인 비중을 차지한다.
- 특징: 단일 로봇 팔, 양팔 로봇, 모바일 매니퓰레이터 등 7종의 로봇에서 수집되었으며, 50Hz의 고주파 제어를 통해 섬세하고 정교한 조작(Dexterous manipulation)을 학습할 수 있다.
- 데이터 밸런싱 (Data Balancing): 데이터 불균형 문제를 해결하기 위해, 샘플 수 에 대해 의 가중치를 적용하는 리샘플링 전략을 취했다. 이는 데이터가 많은 작업(예: 세탁물 접기)에 과적합(Overfitting)되는 것을 방지한다.
3. 모델 구조 및 계층적 제어 (Model & High-level Policy)
-
기반 모델 (Base Model)
: 구글의 PaliGemma (3B) 비전-언어 모델(VLM)을 백본으로 사용한다. 여기에 이미지/텍스트 입력에 따른 행동 생성을 위해 플로우 매칭(Flow Matching) 기반의 액션 헤드를 결합하여 를 완성했다. -
상위 레벨 정책 (High-level Policy)
: "테이블을 치워라(Bussing)"와 같은 복잡하고 긴 호흡의 작업(Long-horizon tasks)은 가 한 번에 처리하기 어렵다.이를 해결하기 위해, 별도의 고성능 VLM을 '작업 관리자(Planner)'로 둔다. 이 VLM이 큰 명령을 "냅킨을 집어라", "쓰레기통에 버려라"와 같은 구체적인 하위 작업(Sub-tasks)으로 쪼개어 에게 전달하는 계층적(Hierarchical) 구조를 채택했다.
IV. THE MODEL
본 섹션에서는 거대 언어 모델의 '의미론적 추론 능력'과 로봇의 '정교한 운동 제어 능력'을 결합한 의 독창적인 아키텍처를 상세히 설명한다. 핵심은 '액션 전문가(Action Expert)'를 통한 구조적 분리와 '플로우 매칭(Flow Matching)'을 통한 효율적 생성이다.
1. 기본 구조: VLM backbone + Action Expert
단순히 VLM 전체를 미세 조정하는 것이 아니라, 로봇 제어를 전담하는 별도의 모듈을 장착하여 전문가 혼합(Mixture of Experts, MoE)과 유사한 구조를 취한다.
-
VLM Backbone
:구글의 PaliGemma 3B 모델을 기반으로 한다.인터넷 데이터로 사전 학습된 강력한 지식과 시각적 이해력을 담당한다. 주로 이미지와 텍스트 토큰을 처리한다. -
Action Expert
:로봇 데이터 처리를 위해 약 3억(300M) 개의 파라미터로 구성된 별도의 신경망(Weights)을 추가했다. (전체 3.3B 중 약 10%)뇌의 언어 중추와 운동 중추가 따로 있듯, 로봇의 관절 상태(Proprioceptive state)와 행동(Action) 토큰은 오직 이 '액션 전문가'만이 처리한다. 이를 통해 VLM의 일반 상식을 해치지 않으면서 운동 능력만 집중적으로 학습시킨다.
2. 행동 생성
조건부 플로우 매칭 (Conditional Flow Matching)는 행동을 뚝뚝 끊기는 텍스트 토큰이 아니라, 연속적인 수치(Continuous Values)로 생성하기 위해 플로우 매칭(Flow Matching) 기법을 도입했다.
[Diffusion vs. Flow Matching]
논문에서는 로봇의 연속적인 행동 생성을 위해 기존의 확산 모델(Diffusion) 대신 플로우 매칭(Flow Matching) 기법을 도입했다. 데이터(행동)를 생성하는 과정을 '출발지(노이즈)에서 목적지(정답 행동)로 가는 여정'에 비유하여 비교하면 다음과 같다.
| 구분 | 확산 모델 (Diffusion) | 플로우 매칭 (Flow Matching) |
|---|---|---|
| 핵심 비유 | 술 취한 사람의 귀가 | 직선 도로 주행 |
| 이동 경로 | 확률적 미분 방정식(SDE)을 따라 비틀거리며 이동 (Stochastic) | 노이즈와 데이터 사이를 잇는 최적의 직선 경로(Vector Field)를 학습 |
| 경로 특징 | 경로가 꼬불꼬불하고 무작위성이 있음 | 경로가 직선에 가까워 군더더기가 없음 (Deterministic, ODE) |
| 효율성 | 목적지 도달까지 많은 단계(Step)가 필요함 | 적은 단계(Step)로도 빠르고 정확하게 도달 |
| 적용 | 고속 제어(50Hz)를 위한 추론 속도 확보가 어려움 | 단 10 Step의 적분만으로 고품질 행동 생성 가능 |
[기술적 정의 및 작동 원리]
플로우 매칭은 연속적인 시간(Continuous Time) 상에서 확률 분포를 변환하는 ODE(상미분 방정식) 기반의 생성 모델이다.
-
벡터 필드 학습
: 노이즈로부터 목표 행동 분포로 데이터를 이동시키는 '속도와 방향(Velocity Vector)'을 직접 학습한다. -
액션 청킹 (Action Chunking)
: 부드러운 움직임을 위해 한 번에 한 스텝만 예측하지 않고, 미래의 행동 덩어리(Action Chunk, )를 통째로 예측한다. -
손실 함수 (Loss Function)
: 모델은 다음 수식을 최소화하는 방향으로 훈련된다.(여기서 는 행동 청크, 는 이미지/텍스트 등의 관측값, 는 목표 속도 벡터를 의미한다.)
3. 추론 효율성 및 최적화 (Inference & Efficiency)
-
적분 방식 (Integration)
: 학습된 벡터 필드를 따라 실제 행동을 생성할 때는 순방향 오일러(Forward Euler) 적분법을 사용하며, 단 10단계()만 거치면 고품질의 행동을 생성할 수 있다. -
KV 캐싱 (KV Caching)
: 매 스텝마다 거대한 VLM을 전부 연산하는 것은 비효율적이다. 따라서 이미지나 텍스트 같은 관측값()의 특징(Key, Value)은 최초 1회만 계산하여 저장(Caching)해 두고, 반복되는 적분 과정에서는 가벼운 '액션 전문가' 부분만 연산하여 추론 속도를 획기적으로 높였다.
4. 베이스라인 모델 (-small)비교
실험을 위해 VLM 사전 학습(Pre-training)이 없는 4억 7천만(470M) 파라미터 크기의 -small 모델을 별도로 개발했다.
이는 거대 모델의 '사전 지식'이 로봇 제어 성능에 실제로 얼마나 기여하는지를 객관적으로 검증하기 위함이다.
V. DATA COLLECTION AND TRAINING RECIPE
본 섹션에서는 모델을 완성하기 위한 데이터 구성 전략과 단계별 학습 철학을 설명한다. 핵심은 데이터의 양뿐만 아니라, '데이터의 성격에 따른 역할 분담'에 있다.
- 데이터 수집
: 사전 학습 혼합물 (Pre-training Mixture) - 는 약 10,000시간 분량의 방대한 데이터로 사전 학습되었다. 이는 크게 두 가지 소스(오픈 소스+자체 수집)로 구성된다.
- 데이터 구성 (Data Composition)
- 오픈 소스 데이터 (약 9.1%): OXE(Open X-Embodiment) 데이터셋의 일부를 사용한다. 주로 2~10Hz의 저주파 데이터이며 동작이 단순하지만, 다양한 환경과 물체 정보를 제공한다.
- 자체 수집 데이터 (약 90.9%): Physical Intelligence 사가 직접 수집한 약 9억 3백만(903M) 타임스텝의 데이터다. 7종의 로봇 플랫폼에서 50Hz 고주파 제어로 수집되었으며, 정교한 조작(Dexterous manipulation)이 가능하다.
-
데이터 밸런싱 (Weighting)
특정 작업(예: 세탁물 접기) 데이터가 지나치게 많은 불균형을 해소하기 위해, 각 작업-로봇 조합의 샘플 수 에 대해 의 가중치를 적용하여 학습 비중을 균등하게 맞췄다.
-
작업(Task)의 재정의
기존 연구가 "컵 집기" 같은 단순 명사-동사 조합을 작업으로 본 것과 달리, 본 논문은 "테이블 치우기(Bussing)"처럼 여러 물체를 복합적으로 처리하는 포괄적인 행위를 하나의 작업으로 정의하여 동작의 다양성을 확보했다.
-
학습 레시피: 2단계 접근법 (Two-Stage Approach)
모델의 능력을 극대화하기 위해 LLM의 학습 방식(Pre-training → Fine-tuning)을 로봇에 적용했다.
-
1단계: 사전 학습 (Pre-training)
- 데이터: 품질이 섞여 있는 대규모의 다양한 데이터.
- 목표: 광범위한 물리적 상식과 일반화 능력을 배운다. 특히, 완벽하지 않은 데이터도 포함되어 있어 모델이 실수했을 때 복구(Recovery)하는 능력(Robustness)을 기르는 데 핵심적인 역할을 한다.
-
2단계: 사후 학습 (Post-training)
- 데이터: 특정 작업을 위해 전문적으로 큐레이팅된 고품질(SFT) 데이터.
- 목표: 특정 작업(Downstream task)을 능숙하고 유려하게(Fluent) 수행하도록 만든다. 사전 학습된 '복구 능력' 위에 '최적의 기술'을 입히는 과정이다.
-
언어 및 상위 레벨 정책 (Hierarchical Policy)
복잡하고 긴 호흡의 작업(Long-horizon tasks)을 해결하기 위해, 혼자 모든 것을 처리하지 않고 역할을 분담한다.
-
상위 레벨 VLM (High-level Planner)
: "테이블을 치워라"와 같은 추상적 명령을 받으면, 이를 "냅킨을 집어라", "쓰레기통에 버려라"와 같은 구체적인 하위 작업(Sub-tasks)으로 분해하여 지시한다. -
(Controller)
: 상위 VLM의 구체적 지시를 받아 실제 로봇 팔의 정교한 움직임을 제어한다.
-
로봇 시스템 상세 (Robot System Details)
다양한 로봇 형태(Cross-embodiment)를 하나의 모델로 처리하기 위해, 입력 벡터의 크기를 가장 큰 로봇(18차원)에 맞춰 제로 패딩(Zero-padding)하여 통일했다.
- 싱글 암 (Single Arm): UR5e, Franka (7~8 자유도)
- 양팔 로봇 (Bimanual): UR5e, Trossen, ARX/AgileX (14 자유도)
- 모바일 매니퓰레이터 (Mobile Manipulator): 바퀴 달린 베이스 + 로봇 팔. 이동과 조작을 동시에 수행 (16~17 자유도)
요약하자면, 시스템은 대규모 데이터로 '기초 체력(Pre-training)'을 다지고, 고품질 데이터로 '숙련도(Post-training)'를 연마하며, 똑똑한 두뇌(High-level VLM)가 지휘하는 구조로 완성되었다.
VI. EXPERIMENTAL EVALUATION
본 섹션에서는 모델의 성능을 4가지 핵심 질문을 통해 검증한다. 실험에는 OpenVLA(7B), Octo(93M)와 같은 기존 파운데이션 모델과 ACT, Diffusion Policy 등의 전문화된 정책이 비교군(Baseline)으로 사용되었다.
기본 모델 성능 평가 (Out-of-box Evaluation)
-
추가 학습(Fine-tuning) 없이, 사전 학습된 '기초 체력'만으로 얼마나 다양한 작업을 수행할 수 있는가?
-
실험 설정
: 셔츠 접기, 테이블 치우기, 식료품 담기, 토스터에서 빵 꺼내기 등 5가지 일상 작업

- 결과:
는 모든 작업에서 비교 모델들을 압도했다.- OpenVLA의 한계: 행동을 언어처럼 이산적인 토큰(Discrete Tokens)으로 끊어서 처리하기 때문에, 50Hz의 부드러운 고주파 제어나 미래 동작을 미리 예측하는 액션 청킹(Action Chunking)을 제대로 구현하지 못해 성능이 저조했다.
- Octo의 한계: 액션 청킹은 지원하지만, 모델 용량(93M)이 너무 작아 복잡한 상황을 이해하는 표현력에 한계가 있었다.

2. 언어 명령 수행 능력 (Following Language Commands)
-
"커피콩을 집어서 가방에 넣어라" 같은 구체적인 언어 지시를 얼마나 잘 따르는가?
-
비교: (VLM 백본 O) vs. -small (VLM 백본 X)
-
결과: VLM 백본의 유무가 결정적 차이를 만들었다.
- : 거대 언어 모델의 지식을 물려받아, 상위 레벨의 복잡한 언어 지시를 정확히 이해하고 동작으로 옮겼다.
- -small: 언어 이해력이 부족하여, 전문가(Human/Oracle)가 옆에서 단계별로 상세히 지시해줘도 그 의미를 파악하지 못해 성능 향상이 거의 없었다. 즉, "말귀를 알아듣는 능력"이 로봇 제어 성공률에 큰 영향을 미침을 증명했다.

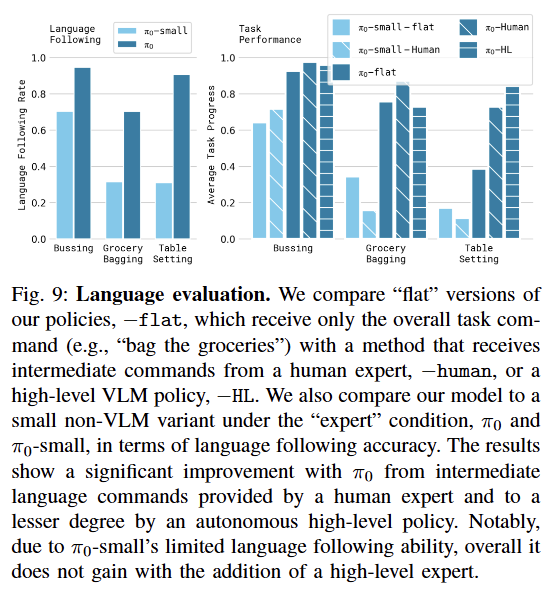
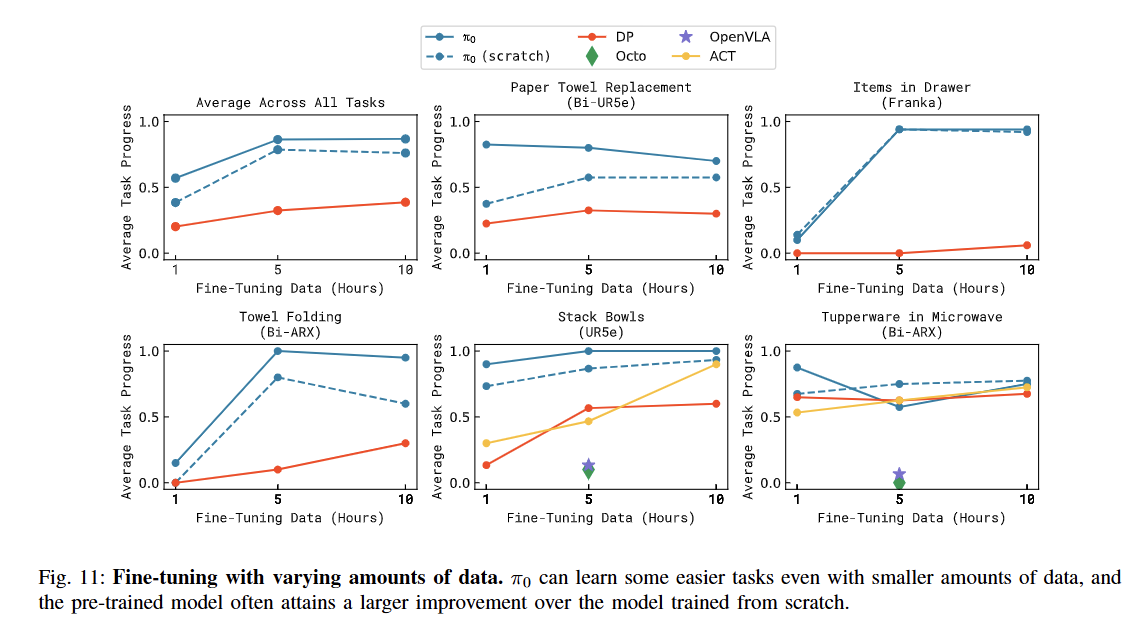
3. 새로운 작업 적응력 (Learning New Dexterous Tasks)
-
사전 학습 때 본 적 없는 낯선 물체나 동작에 대해, 얼마나 적은 데이터로 빠르게 적응(Fine-tuning)하는가?
-
실험 설정
: 전자레인지 사용(미지의 물체), 휴지심 교체(미지의 동작) 등.

- 결과
: 높은 전이 학습(Transfer Learning) 효율:- 는 단 1시간 분량의 적은 데이터만 보여줘도 작업을 능숙하게 배워냈다. 특히 그릇 쌓기처럼 사전 학습 데이터와 유사성이 있는 작업에서는 성능이 비약적으로 상승했다.
- 타 모델 대비 우위: 기존 모델들은 사전 지식을 새로운 작업에 응용하는 능력이 떨어지거나, 아예 처음부터(Scratch) 다시 배워야만 했다.
4. 고난도 복합 작업 완성 (Mastering Complex Multi-stage Tasks)
-
로봇 조작의 '끝판왕'이라 할 수 있는 장기(Long-horizon) 작업을 수행할 수 있는가?
-
실험 설정:
- 세탁물 접기: 구겨진 옷을 인식해 펼치고, 각을 맞춰 개고, 쌓아 올리는 고난도 작업.
- 박스 조립: 평평한 골판지를 입체 박스로 조립하는 작업.
- 계란 담기: 깨지기 쉬운 계란을 힘 조절하며 옮기는 작업.

-
결과
:는 [사전 학습 + 사후 학습]의 전체 파이프라인을 적용했을 때 가장 높은 성공률을 기록하며 SOTA(State-of-the-art) 수준을 달성했다.사전 학습 없이 바닥부터 학습(Scratch)한 모델은 박스 조립처럼 물리적 이해가 필요한 복잡한 작업에서 처참히 실패했다. 이는 의 '기초 체력(Pre-training)'이 고난도 작업 해결의 필수 조건임을 시사한다.
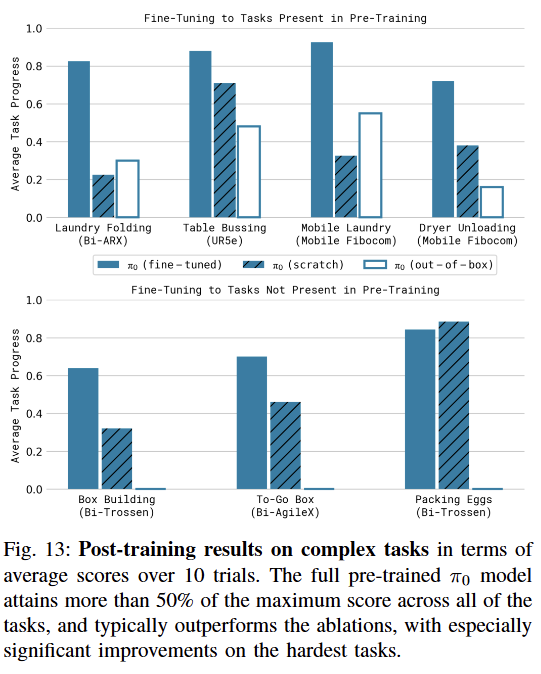
시험 결과를 요약하자면, 는 기본적인 범용성(Out-of-box), 언어 이해력(Language), 새로운 환경 적응력(Fine-tuning), 고난도 작업 수행력(Complexity) 등 모든 지표에서 기존 로봇 모델들을 압도하며 로봇 파운데이션 모델로서의 가치를 입증했다.
VII. DISCUSSION, LIMITATIONS, AND FUTURE WORK
1. 성과: 로봇 파운데이션 모델의 실현 (Discussion)
성공적인 프레임워크: 인터넷 규모의 시각-언어 모델(VLM)과 연속적인 행동 생성을 위한 플로우 매칭(Flow Matching)을 결합하여, 진정한 의미의 로봇 파운데이션 모델 를 구축했다.
역사상 최대 규모: 7가지 로봇 형태, 68개 작업, 총 10,000시간 분량의 데이터를 학습에 사용하여, 현존하는 로봇 조작 모델 중 가장 거대한 '사전 학습 혼합물(Mixture)'을 완성했다.
성능의 증명: OpenVLA나 ACT 등 기존 모델을 압도했을 뿐만 아니라, 그동안 로봇에게는 불가능의 영역으로 여겨졌던 세탁물 접기나 박스 조립 같은 복잡한 다단계 작업(Multi-stage tasks)까지 수행해 냈다.
2. LLM 학습 패러다임과의 평행이론 (Analogy to LLMs)
연구진은 의 성공 요인을 "LLM의 성장 과정과 유사한 학습 전략"에서 찾는다.
-
사전 학습 (Pre-training) 지식 습득
:LLM이 웹 텍스트로 세상의 지식을 배우듯, 로봇은 방대한(하지만 조금 거친) 데이터로 기초적인 물리 상식과 실수 회복력(Recovery)을 배운다. 이는 제로샷(Zero-shot) 능력의 원천이 된다. -
사후 학습 (Post-training) 정렬(Alignment)
:LLM이 인간의 지시를 잘 따르도록 튜닝되듯, 로봇은 고품질 데이터를 통해 특정 작업을 유려하게(Fluent) 수행하는 '기술'을 익힌다. -
결합의 필연성
:고품질 데이터만 있다면? 실수를 만회할 줄 모르는 '온실 속 화초(Brittle)'가 된다.사전 학습 데이터만 있다면? 동작이 투박하고 정교함이 떨어진다.따라서 이 두 단계의 결합은 선택이 아닌 필수다.
3. 한계점 및 향후 과제 (Limitations & Future Work)
는 가능성을 보여주었지만, 완벽한 솔루션은 아니다. 연구진은 다음과 같은 미해결 과제들을 솔직하게 제시한다.
-
데이터 연금술의 부재 (Data Composition)
:현재는 "일단 다 섞자"는 전략을 취했다. 하지만 정확히 어떤 데이터가 성능 향상에 기여하는지, 데이터 간의 최적 혼합 비율(Weighting)은 무엇인지에 대한 이론적 이해는 아직 부족하다. -
신뢰성과 스케일링 법칙 (Reliability & Scaling Laws)
:모든 작업이 100% 성공하는 것은 아니다. 99.9%의 완벽한 성능(Near-perfect performance)에 도달하기 위해 정확히 얼마만큼의 데이터가 더 필요한지 예측하는 '로봇판 스케일링 법칙'은 아직 미지수다. -
범용성의 확장 한계 (Scope of Universality)
:다양한 '로봇 팔(Manipulator)'을 통합하는 데는 성공했다. 하지만 이 방법론이 자율 주행(Autonomous driving)이나 4족 보행(Legged locomotion)처럼 완전히 다른 도메인의 로봇에게도 통할지는 미지수이며, 이는 흥미로운 후속 연구 주제다.
