
Introduction
1. 기존 로봇 학습의 한계 - 일반화(Generalization)의 어려움
로봇 조작(Robotic Manipulation)을 위한 학습된 정책(Learned Policies)의 가장 큰 약점은 훈련 데이터 범위를 벗어난 상황에 대처하지 못한다는 점, 즉 일반화(Generalize) 능력이 부족하다는 것이다.
기존 모델들은 물체의 위치가 바뀌거나 조명이 달라지는 등의 사소한 환경 변화에 대해서는 어느 정도 외삽(Extrapolate)하여 적응할 수 있다.
- 외삽(Extrapolate): 로봇이 이미 배운 지식을 바탕으로, 조금 다른 상황(예: 컵이 평소보다 10cm 옆에 있는 경우)을 추론해 행동하는 능력
하지만 훈련 때 보지 못한 새로운 방해 요소(Scene Distractors)가 등장하거나, 전혀 새로운 객체를 마주했을 때(예: 책상 위에 컵 대신 처음 보는 꽃병이 있거나, 책상이 매우 어지럽혀져 있다거나 하는 기존 훈련데이터에 없던 상황이 주어졌을 때)는 견고성(Robustness)이 크게 떨어진다.
2. 데이터 부족과 파운데이션 모델(Foundation Models)의 기회
로봇 공학 분야에서 인터넷 규모의 거대 데이터를 이용한 사전 훈련(Pretraining)을 재현하는 것은 여전히 어려운 과제이다.
가장 큰 로봇 데이터셋조차 샘플 수가 10만~100만 개 수준에 불과해, 수십억 개의 데이터를 가진 비전/언어 모델에 비해 턱없이 부족하다.
저자는 이러한 데이터 불균형이 역설적으로 기회가 될 수 있다고 한다. 이미 시각(Vision)과 언어(Language)를 완벽히 학습한 거대 파운데이션 모델(Foundation Models)을 가져와 로봇의 '두뇌'로 활용할 수 있기 때문이다.
3. 기존 VLA(Vision-Language-Action) 모델의 문제점
하지만 로봇 제어를 위해 VLA 모델을 널리 사용하는 데에는 두 가지 큰 장벽이 있다.
-
폐쇄성(Closed): RT-2와 같은 기존 모델들은 아키텍처나 훈련 방식이 비공개여서 대중이 접근하거나 연구하기 어려움
-
미세 조정(Fine-tuning) 가이드 부재: 새로운 로봇이나 작업에 맞춰 VLA를 효율적으로 재학습시키는 미세 조정(Fine-tuning) 방법에 대한 모범 사례(Best Practices)가 정립되지 않음
본 논문은 이러한 문제를 해결하기 위해 70억(7B) 파라미터를 가진 오픈 소스 VLA 모델, OpenVLA를 제안한다.
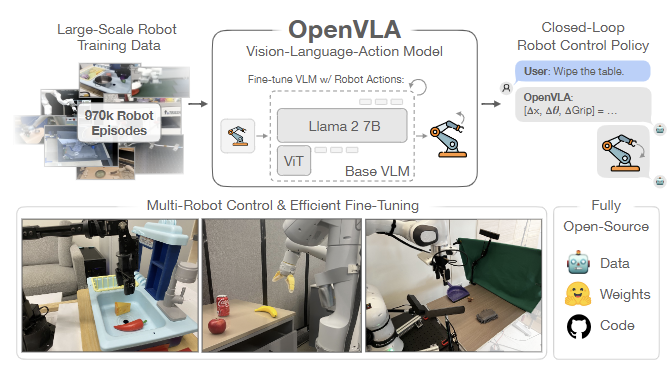
-
Architecture
강력한 시각 처리를 위해 SigLIP과 DINOv2를 비전 인코더로 사용하고, 언어 처리를 위해 Llama 2를 백본(Backbone)으로 결합 -
Training
Open-X Embodiment 데이터셋의 97만 개 로봇 조작 궤적(Trajectories)을 사용하여, 다양한 로봇 형태와 작업 환경을 학습 -
Evaluation
OpenVLA는 더 효율적인 구조와 다양한 데이터 학습을 통해 압도적인 성능을 보인다.
이전 최고 성능(SOTA) 모델이자 550억(55B) 파라미터를 가진 구글의 RT-2-X와 비교했을 때, WidowX 및 Google Robot 테스트에서 절대 성공률이 16.5% 더 높았다.
2. Related Work
본 섹션에서는 OpenVLA의 기반이 되는 대규모 비전-언어 모델(VLMs), 대규모 데이터셋을 통한 로봇 학습(Generalist Robot Policies, VLA)에 대해 서술한다.
Visually-conditioned language models (VLMs)
최근의 VLM들은 거대 언어 모델(Large Language Models, LLMs)의 성공을 시각적 영역으로 확장했다.
LLaVA(Large Language and Vision Assistant)와 같은 최신 모델들은 Vision Encoder(예: CLIP, SigLIP)가 이미지를 처리하여 특징(Feature)을 추출하면, 이를 Projector(예: MLP)를 통해 언어 모델이 이해할 수 있는 토큰 공간으로 매핑한다.
Patch-as-token: 이미지를 작은 조각(Patch)으로 나눈 뒤, 이를 텍스트 토큰처럼 취급하여 언어 모델에 입력하는 구조
이러한 모델들은 인터넷 규모의 이미지-텍스트 쌍으로 훈련되어 이미지 캡셔닝(Image Captioning)이나 시각적 질의응답(VQA)에서 뛰어난 성능을 보였다.
본 논문은 이러한 아키텍처(특히 LLaVA 및 Prismatic 계열)를 채택하여, 로봇이 시각적 정보를 언어적으로 이해하고 처리할 수 있는 강력한 기반을 마련한다.
Generalist Robot Policies, Vision-Language-Action Models(VLA)
로봇 공학에서도 특정 작업만 수행하는 전문가 모델에서, 다양한 작업을 수행하는 일반 목적(Generalist) 모델로의 전환이 일어나고 있다.
-
Octo: Octo는 언어 임베딩이나 비전 인코더 같은 '사전 학습된 부품'을 가져오긴 하지만, 이를 연결하는 나머지 부분은 바닥부터(From scratch) 새로 학습해서 이어 붙이는(Stitching) 방식을 사용
→ 반면, OpenVLA는 VLM 전체를 end-to-end로 finetuning한다. 로봇의 행동(action)을 언어 단어처럼 취급하여, 모델이 직접 예측하게 한다. -
VLA 초기 모델 (
RT-1): RT-1은 트랜스포머(Transformer) 아키텍처를 사용하여 대규모 로봇 데이터셋을 학습했지만, 언어 모델의 사전 지식을 충분히 활용하지 못하고 처음부터(From scratch) 훈련되었다. -
VLA의 등장 (
RT-2): RT-2는 거대 VLM을 로봇 행동(Action) 토큰으로 미세 조정(Fine-tuning)하여, 인터넷 규모의 상식과 추론 능력을 로봇 제어에 접목시킨 Vision-Language-Action(VLA) 모델을 제안했다.이는 새로운 명령어나 객체에 대한 일반화 능력을 크게 향상시켰다. 그러나 RT-2와 같은 모델은 폐쇄적(Closed)이며, 모델 크기가 너무 커서(예: 55B) 추론 속도가 느리고 실제 로봇에 탑재하기 어렵다.
3. The OpenVLA Model
3.1 Preliminaries: Vision-Language Models
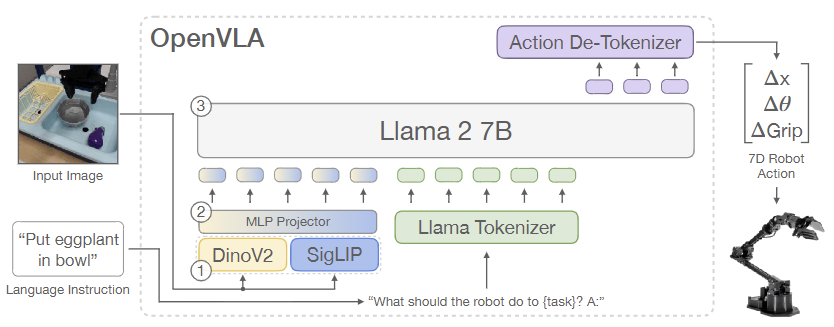
최근 대부분의 VLM 구조는 위 그림과 같이 세 가지 key component로 구성된다.
- Visual Encoder: 이미지 입력을 다수의 "Image patch embeddings"으로 매핑(변환)하는 역할
- Projector: 시각 인코더에서 나온 출력 임베딩을 받아서, 이를 언어 모델이 처리할 수 있는 입력 공간(Input space)으로 매핑해주는 연결 모듈
- LLM Backbone: 변환된 시각 정보와 텍스트 정보를 처리
VLM 훈련 과정에서, 모델은 인터넷의 다양한 소스에서 수집된 '비전-언어 데이터 쌍' 혹은 '교차 데이터(interleaved data)'를 사용하여, Next text token prediction Objective를 가지고 처음부터 끝까지(End-to-end) 학습된다.
본 연구에서는 Prismatic-7B VLM을 기반으로 모델을 구축했다.
기본 구조: 입력 이미지는 시각 인코더(Vision Encoder)를 통해 특징(Feature)으로 변환되고, 프로젝터(Projector)를 거쳐 언어 모델(LLM)에 입력됩니다.
핵심 구성 요소:
vision encoder: SigLIP + DINOv2 (두 가지를 결합)
backbone: Llama 2 (7B) 언어 모델
CLIP이나 SigLIP만 사용하는 일반적인 비전 인코더와 대조적으로, DINOv2 특징을 추가하는 것은 공간 추론(Spatial reasoning) 능력을 향상시키는 데 도움이 되는 것으로 밝혀졌으며, 이는 특히 로봇 제어(Robot control)에 유용하다.
3.2 OpenVLA Training Procedure
일반적인 VLM은 텍스트를 출력하지만, 로봇 제어 모델은 물리적인 행동(Action)을 출력해야 한다. OpenVLA는 이를 위해 모델 전체를 Fine-tuning한다.
- Input : 관측 이미지(Observation Image) + 자연어 작업 지시(Language Instruction)
- Output : 예측된 로봇 행동의 토큰 문자열(String of predicted robot actions)
- Action Discretization
로봇 팔의 움직임(6DoF 또는 7DoF)은 연속적인 실수 값(Continuous values)이므로, 이를 언어 모델이 이해할 수 있는 '단어'처럼 만들기 위해 이산화(Discretization) 과정을 거쳐야 한다.
- Binning: 각 행동 차원(x, y, z, r, p, y 등)을 256개의 균일한 구간(bins)으로 나눈다.
분위수(Quantile) 기반 설정:
기존 연구(Brohan et al.)는 최솟값-최댓값(Min-Max)을 기준으로 범위를 잡았다.
하지만 OpenVLA에서는 하위 1% ~ 상위 99% 분위수(Quantile) 사이를 균일하게 나눈다.그 이유는, 데이터에 포함된 이상치(Outlier)가 구간의 폭을 불필요하게 넓혀, 실제 중요한 동작의 정밀도(Granularity)를 떨어뜨리는 것을 방지하기 위함이다.
이제 이산화를 거친 N차원 로봇 행동은 범위의 개의 정수 시퀀스로 변환된다.
- Handling Tokenizer Limitations
OpenVLA의 백본인 Llama 토크나이저는 새로운 토큰을 위한 '특수 토큰(Special tokens)' 공간이 100개 뿐이다. (필요한 행동 토큰은 256개)
이에 대한 해결책으로, 복잡한 구조 변경 대신 단순한 방식을 택했다. Llama의 전체 어휘(Vocabulary) 중 가장 적게 사용되는 마지막 256개 토큰을 로봇 행동 토큰으로 덮어쓰기(Overwrite) 한다.
- Training Objective
행동이 토큰 시퀀스로 변환되면, 모델은 표준적인 'Next-token prediction' 방식으로 훈련된다.
오직 예측된 행동 토큰 부분에 대해서만 Cross-entropy loss를 계산하여 모델을 최적화한다.
3.3 Training Data
OpenVLA는 세계 최대 규모의 로봇 조작 데이터셋인 Open X-Embodiment 데이터셋을 사용하여 학습되었다.
- 970,000개 이상의 로봇 조작 에피소드
- Franka Panda, WidowX, Google Robot 등 다양한 로봇 기종과 환경 포함
- 데이터 증강 (Augmentation): 모델의 과적합(Overfitting)을 막고 견고성을 높이기 위해 훈련 이미지 변형
Random Resized Crop: 이미지를 무작위로 자르고 크기를 조절 (0.8 ~ 1.0 비율)Color Jitter: 밝기, 대비, 채도 등을 미세하게 조정
3.4 OpenVLA Design Decisions
1. VLM 백본 선택 (VLM Backbone)
어떤 비전-언어 모델을 베이스로 쓸 것인가를 결정
-
실험 대상: Prismatic, IDEFICS-1, LLaVA
-
결과:
- 단일 객체: 세 모델 모두 비슷한 성능을 보임
- 다중 객체 (Language Grounding): 여러 물건 중 지시한 물건(예: "오렌지 집어")을 찾는 능력은 LLaVA가 IDEFICS-1보다 절대 성공률이 35% 더 높았음. Prismatic은 LLaVA보다도 약 10% 더 높은 성능을 보임. Prismatic의 이중 비전 인코더(SigLIP + DINOv2) 구조가 복잡한 공간 추론(Spatial Reasoning) 능력을 크게 향상시켰기 때문. 또한 코드베이스가 모듈화되어 있어 사용하기 편리함
2. 이미지 해상도 (Image Resolution)
입력 이미지 크기는 훈련 속도에 큰 영향을 미침
-
비교: vs
-
결과: 해상도는 훈련 시간이 3배나 더 걸렸지만, 로봇 제어 성능에는 차이가 없음
-
결정: 효율성을 위해 px 해상도를 선택 (일반적인 VLM 벤치마크에서는 해상도가 높을수록 좋지만, 로봇 제어 VLA에서는 아직 그런 경향이 나타나지 않음)
3. 비전 인코더 미세 조정 (Fine-Tuning Vision Encoder)
비전 인코더(눈)를 고정할지, 같이 학습시킬지를 결정
-
기존 통념: 보통 VLM을 만들 때는 비전 인코더를 고정(Freeze)하는 것이 성능이 더 좋음 (인터넷 데이터로 배운 특징을 보존하기 위해)
-
발견: 하지만 로봇용 VLA에서는 비전 인코더를 미세 조정(Unfreeze & Fine-tune)하는 것이 필수적
-
가설: 사전 학습된 비전 모델은 로봇이 물체를 정밀하게 제어하는 데 필요한 '미세한 공간적 디테일(Fine-grained spatial details)'을 충분히 파악하지 못하기 때문에, 로봇 데이터에 맞춰 눈을 다시 훈련시켜야 함
4. 훈련 에포크 (Training Epochs)
데이터셋을 몇 번 반복해서 공부시킬 것인가를 결정
-
기존 통념: 일반적인 LLM이나 VLM은 데이터셋을 1~2회(Epoch)만 훑어보고 학습을 끝냄
-
발견: VLA는 훨씬 더 많은 반복 학습이 필요. 행동 토큰 예측 정확도가 95%를 넘을 때까지 실제 로봇 성능이 계속 향상됨
-
결정: 최종 모델은 데이터셋을 무려 27 Epochs 동안 반복 학습함
5. 학습률 (Learning Rate)
모델이 얼마나 빠르게 학습할지 결정하는 파라미터
-
실험: 여러 단위(Orders of magnitude)의 학습률을 테스트
-
결정: 고정 학습률 (0.00002)가 가장 좋은 결과를 보임. 이는 Prismatic VLM 사전 훈련 때 썼던 값과 동일함.
-
학습률을 서서히 올리는 웜업(Warmup) 방식은 별다른 이득이 없는 것으로 드러남
4. Experiments (실험)
본 섹션에서는 OpenVLA의 성능을 포괄적으로 평가하기 위해 세 가지 주요 질문에 답하고자 한다.
- 일반화(Generalist) 성능: OpenVLA는 광범위한 작업과 로봇 형태에 대해 강력한 일반적인 정책(generalist policy)으로 작동하는가?
- 적응성(Adaptation): OpenVLA는 새로운 다중 작업(multi-task) 도메인에 효과적으로 미세 조정(fine-tuned)될 수 있는가?
- 효율성(Efficiency): OpenVLA는 소비자용 GPU에서 훈련 및 추론이 가능할 만큼 효율적인가?
4.1 Direct Evaluations on Multiple Robot Platforms
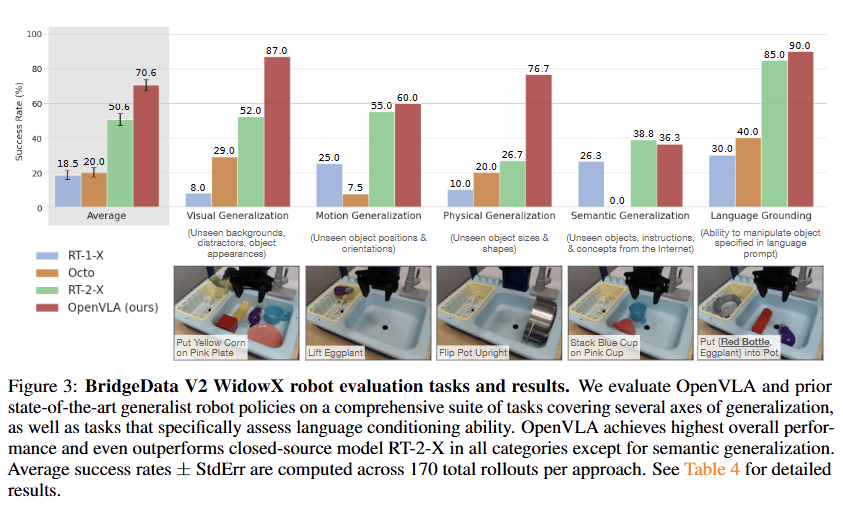
OpenVLA가 학습 데이터에 없던 새로운 환경(Out-of-distribution)에서 기존 최고 모델들과 비교해 얼마나 잘 작동하는지 평가한다.
-
비교 모델 (Baselines)
- RT-2-X (55B): 구글의 초대형 비전-언어-행동 모델.
- Octo: 최근 공개된 일반 목적 로봇 정책 (Transformer 기반) -
실험 결과
- WidowX 로봇: BridgeData V2 데이터셋을 기반으로 테스트했다. 물체 위치 변화, 새로운 물체, 새로운 배경 등 다양한 조건에서 OpenVLA는 Octo보다 18% 더 높은 성공률을 보였다.
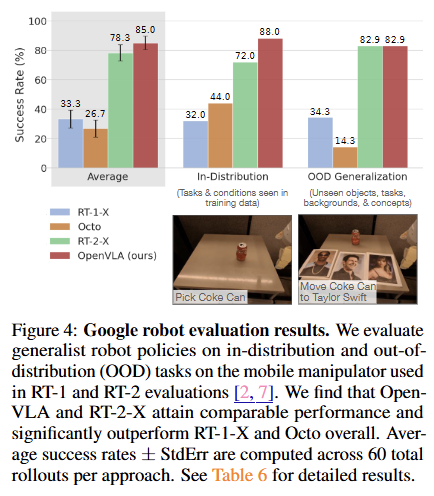
-
Google Robot: 구글 자체 로봇 환경에서 테스트했다. OpenVLA(7B)는 파라미터 수가 훨씬 많은 RT-2-X(55B)보다 평균 16.5% 더 높은 성능을 기록하며, 더 작지만 더 강력함을 입증한다.
특히 훈련 때 본 적 없는 새로운 물체(Unseen Objects)나 복잡한 언어 지시를 처리하는 능력에서 기존 모델들을 압도한다.
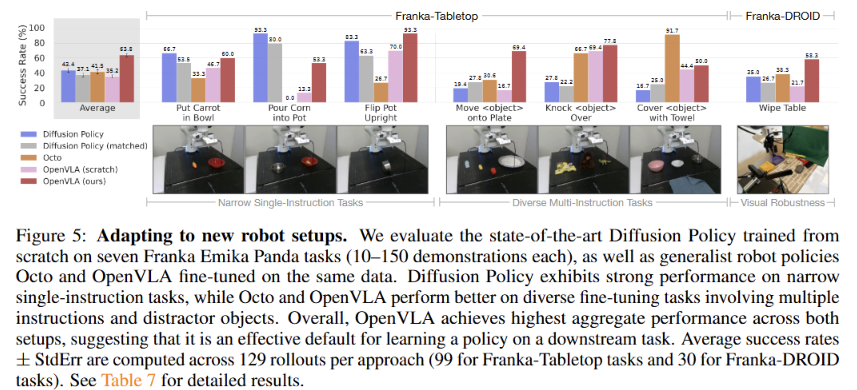
4.2 Data-Efficient Adaptation to New Robot Setups
사용자가 이 모델을 다운로드하여 자신의 로봇(Custom Robot)이나 새로운 작업에 적용할 때, 얼마나 적은 데이터로 학습이 가능한지 평가한다.
-
실험 환경
OpenVLA가 훈련 과정에서 한 번도 본 적 없는 Franka Panda 로봇을 사용 -
결과
-
적은 데이터로 고성능: 작업당 단 50개의 데모(시연) 데이터만으로도 새로운 작업을 효과적으로 학습함
-
강력한 언어 이해: "빨간 블록 말고 초록 블록을 밀어라"와 같이 언어적/공간적 추론이 필요한 작업에서, 처음부터 학습하는 방식(Diffusion Policy)이나 다른 모델(Octo)보다 월등히 높은 적응력을 보임.
따라서, 많은 데이터를 새로 모을 필요 없이, 적은 데이터로도 내 로봇에 맞게 빠르게 튜닝할 수 있음을 입증.
-
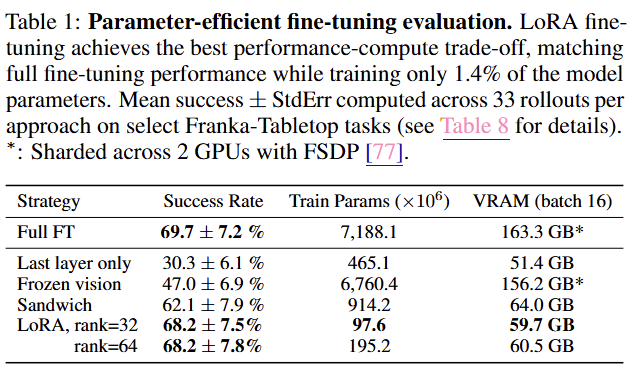
4.3 Parameter-Efficient Fine-Tuning
모델 전체를 재학습(Full Fine-tuning)하는 것은 비용이 많이 든다. 여기서는 효율적인 튜닝 기법인 LoRA(Low-Rank Adaptation)의 효과를 검증한다.
-
비교:
-
Full Fine-Tuning: 모델의 모든 파라미터(70억 개)를 다 업데이트.
-
LoRA: 전체 파라미터의 극히 일부(약 1~2%)만 업데이트.
-
-
결과
LoRA를 사용하여 학습해도 전체를 다 학습한 것과 성능 차이가 거의 없었음(No significant performance drop)
사용자는 LoRA Finetuning을 통해 가볍고 빠르게 모델을 커스터마이징할 수 있다.
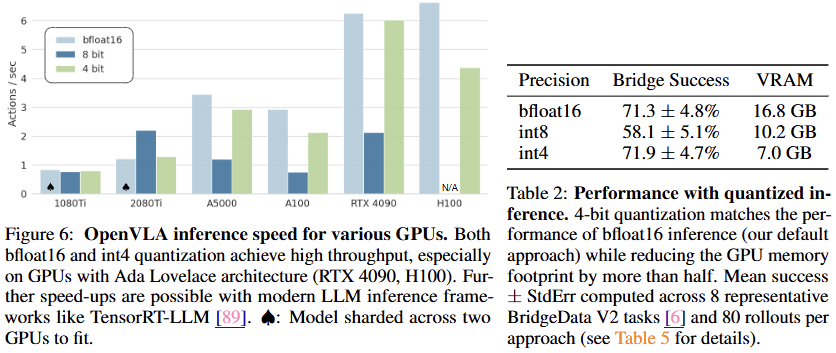
4.4 Memory-Efficient Inference via Quantization
모델이 실제 로봇에 탑재될 수 있을 만큼 가볍고 빠른지(Inference) 확인한다.
-
실험 설정: 모델의 정밀도를 16-bit에서 4-bit로 압축(Quantization)하여 테스트했다.
-
결과
-
메모리 절약: 모델 용량이 획기적으로 줄어들어 일반 소비자용 GPU(RTX 3090/4090)에서도 여유롭게 동작
-
속도: 4-bit 환경에서도 초당 20회(20Hz) 이상의 제어 명령을 생성할 수 있어, 실시간 로봇 제어에 문제가 없음
-
성능 유지: 압축을 해도 로봇 조작 성공률에는 영향이 없음
-
비싼 서버급 GPU가 없어도, 누구나 집에서 OpenVLA를 돌릴 수 있음을 입증한다.
5 Discussion and Limitations
Discussion (논의)
본 논문은 일반적인 로봇 조작을 위한 70억(7B) 파라미터 규모의 오픈 소스 비전-언어-행동(VLA) 모델인 OpenVLA를 소개했다.
OpenVLA는 인터넷 규모의 비전-언어 사전 훈련(pre-training)과 대규모 로봇 데이터셋(Open X-Embodiment)을 활용하여 강력한 일반화 성능을 달성했다.
주요 기여는 다음과 같다:
-
성능: 기존의 비공개 최첨단 모델(RT-2-X 55B)보다 훨씬 작은 크기로 더 높은 성공률을 기록했다.
-
접근성: 소비자용 GPU(예: RTX 3090, 4090)에서도 LoRA (Low-Rank Adaptation)와 4비트 양자화(4-bit Quantization)를 통해 효율적으로 미세 조정(fine-tuning)하고 실행할 수 있다.
-
오픈 소스: 모델 가중치(weights), 훈련 코드, 데이터 처리 파이프라인을 모두 공개하여 로봇 커뮤니티의 연구 진입 장벽을 낮췄다.
Limitations (한계점)
OpenVLA가 강력한 성능을 보여주지만, 여전히 해결해야 할 몇 가지 중요한 한계점이 존재한다.
-
Inference Latency (추론 지연 시간):
OpenVLA는 효율적인 훈련과 배포를 위해 최적화되었지만, 70억 개의 파라미터를 가진 대규모 트랜스포머 모델이다. 따라서 ResNet이나 작은 CNN 기반의 정책(policy)보다 추론 속도가 느리다.현재 소비자용 GPU에서 약 10~20Hz 정도의 제어 주기를 달성할 수 있지만, 이는 매우 빠른 반응 속도가 필요한 동적 작업(예: 날아오는 공 잡기)에는 부족할 수 있다.
-
Single-View Limitation (단일 시점의 한계):
현재 OpenVLA는 기본적으로 단일 카메라 시점(single-view) 입력에 최적화되어 있다. 많은 로봇 시스템이 다중 카메라(손목 카메라 + 3인칭 카메라 등)를 사용하여 가려짐(occlusion) 문제를 해결하지만, OpenVLA의 기본 아키텍처는 이를 직접적으로 지원하지 않거나 처리 비용이 비싸다.다중 시점을 처리하려면 이미지를 합쳐서 넣거나 모델 구조를 변경해야 하는데, 이는 계산 비용을 더욱 증가시킨다.
-
Lack of History (과거 이력 부재):
OpenVLA는 현재 시점의 이미지만 보고 행동을 결정하는 경향이 있다. 즉, 과거의 행동 이력(action history)이나 이전 프레임 정보를 길게 기억하고 활용하는 데에는 한계가 있다.
이는 '물체가 잠시 가려졌을 때'나 '순서가 중요한 긴 작업'을 수행할 때 불리할 수 있다.
-
Precision (정밀도):
VLA 모델은 언어 모델 기반이므로, 행동을 이산적인 토큰(discrete tokens)으로 출력한다. 이는 연속적인 좌표를 직접 출력하는 회귀(regression) 기반 모델보다 초정밀 제어(millimeter-level precision)에서 성능이 떨어질 수 있다.예를 들어, 바늘 구멍에 실을 꿰는 것과 같은 극도로 정밀한 작업에서는 전용 제어기보다 성능이 낮을 수 있다.
-
Hallucination (환각 현상):
비전-언어 모델(VLM)의 고질적인 문제인 환각(hallucination)이 발생할 수 있다. 로봇이 실제로는 없는 물체를 있다고 판단하거나, 지시사항을 잘못 해석하여 엉뚱한 행동을 할 위험이 여전히 존재한다.
