게으른 탓에 오랜만에 돌아온 논문 리뷰 😢
노예 하려면 자주 좀 읽어야 하는데.. 이제 못해도 2주에 한 개는 읽어보자...!!!
몇개 논문 읽으려고 pdf 뽑아놓고 GPT-3부터 읽었는데, 워낙 논문 장수가 길고 실험 부분이 많아서
앞부분만 읽고 요약해보려고 한다 !!

Language Models are Few-Shot Learners(2020) 논문을 읽고 내용 요약 및 정리 한 내용이다.
앞서 언급했듯 원문의 검증 및 테스트 과정이 세세하고 길어서 섹션 3 Result 파트 까지만 요약하기로 한다.
1. Introduction
NLP의 최신 트랜드는 다운스트림 태스크 전이를 위한 더욱 유연하고 task-agnostic(태스크에 구애받지 않는) 방법에 적용된 사전학습 언어 representation으로 특징되어 왔다.
최초에는 워드 벡터를 사용하여 single layer representation를 학습하고 task-specific(태스크 명시적인) 구조로 전달된다. 그 다음으로 더 강력한 representation 생성을 위해 representations과 contextual state의 multiple layer로 구성된 순환 신경망(RNNs)이 사용된다 (여전히 태스크 명시적인 구조에 적용). 더 최근에는 사전학습된 순환, 또는 트랜스포머 언어 모델이 직접적으로 파인튜닝되고, 전체적으로 태스크 명시적인 구조의 필요성을 없애고 있다.
이러한 패러다임은 reading comprehension, QA, textual entailment 등 다양한 challenging NLP task에서 큰 발전을 이끌었고, 새로운 구조와 알고리즘에 기반하여 계속 발전하고 있다. 그러나, 이러한 접근법의 주된 한계는 task-agnostic한 구조에도 불구하고 여전히 task-specific한 데이터셋과 파인튜닝을 필요로 한다는 것이다.
전형적으로 원하는 태스크에서 좋은 성능을 얻기 위해서, 수천 수백만 태스크에 명시적인 예제로 구성된 데이터셋에 파인튜닝하는 것이 필요하다. 다음의 몇가지 이유로, 이러한 한계점을 없애는 것이 바람직 해 보인다.
첫번째로 실용적 관점에서 살펴보면, 새로운 모든 태스크에 라벨링된 예제로 구성된 대형 데이터셋을 필요로 하는 것이 언어 모델의 적용성(applicablity)을 제한시킨다.
유용한 언어 태스크는 문법 교정부터 abstract concept의 예시 생성, 단편 소설 평론까지 상당히 광범위하다. 이러한 태스크의 대다수는 대규모 지도학습 데이터셋을 수집하기 어렵고, 특히 태스크 프로세스가 모든 새로운 태스크마다 반복되어야 하는 경우 더 어렵다.
두번째로, 훈련 데이터에서 거짓된(spurious) 연관성을 이용할 가능성(potential)이 모델의 표현력과 훈련 분배(training distribution)의 협소함과 함께 근본적으로 커진다. 이는 사전학습과 파인튜닝 패러다임에서 문제를 일으킬 수 있는데, 모델이 사전학습 당시의 정보를 흡수하기 위해 크게 설계되지만, 좁은 범위의 task distributions에서만 파인튜닝이 수행되기 때문이다.
예를 들면, [HLW+20]에서 더 큰 규모의 모델은 필연적으로 더 좋은 out-of-distribution을 일반화하지 않는다는 것을 발견한다. 이러한 패러다임 하에 행해진 일반화 성능은 좋지 못한데, 모델이 지나치게 training distribution에 명시적이고 그 밖에서는 잘 일반화되지 못하기 때문이다.
세번째로, 사람들은 대부분 언어 태스크를 학습하는 데 대규모 지도학습 데이터가 필요하지 않다. 대신 자연어에 대한 간단한 지시사항( e.g. “이 문장이 묘사하는 게 기쁨인지 슬픔인지 말해 줘”) 또는 기껏 해야 몇가지 설명 (e.g. “여기 용감하게 행동한 사람들에 대한 두 가지 예시가 있다; 용감함의 세 번째 예시를 들어 보라”) 은 사람이 최소한의 합리적인 능력으로 새로운 태스크를 수행하기에 충분하다.
현재 우리 NLP 기술의 개념적 한계를 지적하는 것 외에도, 이러한 인간의 적응성(adaptability)은 실용적 장점이 있다. 사람들은 이를 통해 많은 태스크와 기술을 매끄럽게 섞거나 변경할 수 있는데, 예를 들면 긴 대화동안 부가적인 것을 수행한다. 저자는 언젠가 NLP 시스템이 인간과 동일한 유창함과 보편성을 가지길 희망한다.
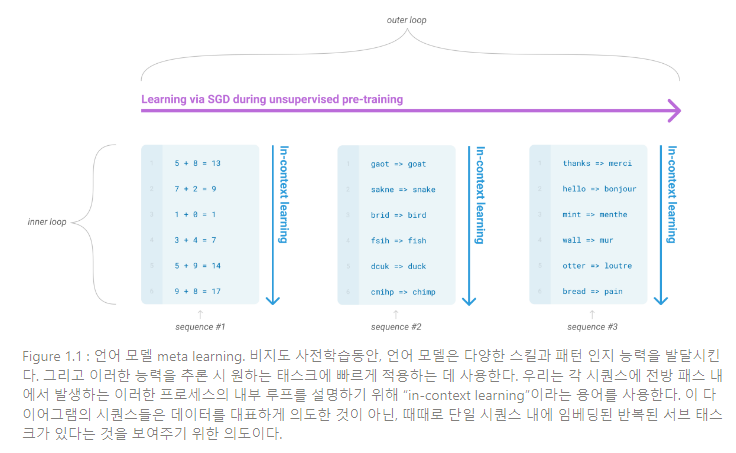
이러한 문제사항을 다루는 한 가지 가능성은 meta-learning이다. 메타러닝이란 언어 모델의 문맥에서 모델이 다양한 기술과 패턴 인지 능력을 학습 당시에 발전시키고, 발전 시킨 능력을 추론에 사용하여 빠르게 적용하거나 원하는 태스크를 인지하는 것이다(Figure 1.1에 설명됨). 최근 연구는 태스크 명시화 형식으로 사전학습된 언어 모델의 입력 텍스트를 사용하며, 소위 “in-context learning”을 통해 이러한 과정을 수행하려 한다.
이 모델은 자연어 지도 또는 태스크에 대한 간단한 설명으로 조성되고, 그리고 나서 단순히 다음에 무엇이 올 지 예측함으로써 추가적인 사례를 완수할 것으로 기대된다.
이러한 접근법(메타 러닝 방식)이 초기의 장래성을 입증해 왔지만, 여전히 파인튜닝보다는 훨씬 뒤떨어진 결과를 내고 있다. 예를 들면 [RWC+19]는 Natural Question에서 4%의 스코어를 달성했고, 심지어 CoQa의 결과는 F1 55로 SOTA 성능에 35포인트나 뒤떨어져 있다. 메타러닝이 언어 태스크를 해결하는 실용적인 방법으로 수행되기 위해, 충분한 발전이 필요한 것은 명백하다.
언어 모델에서 또 하나의 최신 트렌드는 앞으로 나아갈 길을 제시한다. 근 몇년 간, 트랜스포머 기반 언어 모델의 용량은 크게 증가해 왔다.
선행 연구들의 파라미터 수의 증가는 텍스트 합성이나 다운스트림 NLP 태스크의 발전을 이끌었고, 로그 손실(log loss)은 규모에 따라 향상되는 트렌드를 따른다는 것을 입증한다. 문맥 내 학습(in-context learning)이 많은 기술과 모델의 파라미터 내 태스크를 흡수하므로, in-context learning의 능력이 규모에 따른 강력한 이익을 볼 수 있다는 것이 타당하다.
본 논문은 1750억개 파라미터를 사용하여 자기 회귀 언어모델(auto-regressive language model)을 훈련시키고 in-context learning 능력을 측정함으로써 이러한 가설을 검증하고자 하며, 이 훈련 모델을 GPT-3이라 일컫는다.
특히, 본 논문은 태스크에 빨리 적응하는지 평가하기 위해 고안된 몇 가지 태스크(학습 세트에 직접적으로 포함되지 않는) 뿐만 아니라 24가지 NLP 데이터셋에서 GPT-3을 평가한다. 각 태스크에서 GPT-3은 다음 3가지 조건 하에 평가된다.
(a)
few shot learning/in-context learning: 모델의 context window에 fit할 만큼의 충분한 설명을 허용한다. (보통 10 ~ 100)(b)
one shot learning: 설명을 1개만 허용한다.(c)
zero shot learning: 설명을 허용하지 않으며 모델에 자연어에 대한 지시사항만 주어진다.
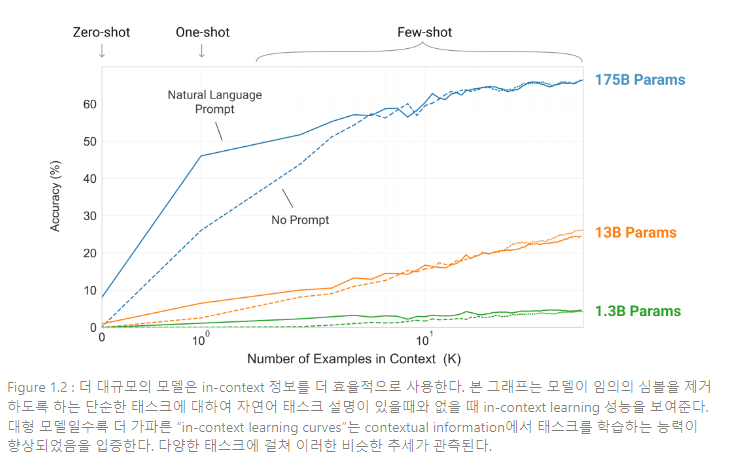
Figure 1.2는 논문의 실험 조건을 설명하고, 모델이 단어에서 관련없는 심볼을 제거하도록 요구하는 단순한 태스크를 학습하는 few-shot learning을 제시한다. 모델의 성능은 자연어 태스크 설명이 증가할수록, 모델의 문맥 예제 수 K가 커질수록 향상된다. few-shot learning의 성능은 모델 크기에 따라 드라마틱하게 발전된다.
GPT-3은 NLP 태스크에서 유망한 zero shot, one shot setting 결과를 얻었고, few shot setting에서는 SOTA 성능과 필적하거나 일부는 SOTA 성능을 능가하기도 한다 (SOTA의 경우 파인튜닝 된 모델로 얻은 결과).
GPT-3은 빠른 적응력이나 즉석(on-the-fly) 추론을 검증하기 위해 설계된 태스크에 대하여 one shot과 few shot의 성능을 보여준다. 또한, few-shot setting은 평론가들이 사람이 쓴 기사인지 구분하기 어려울 정도로 자연스럽게 새로운 합성 기사를 생성할 수 있다는 것을 보여준다.
이와 동시에, GPT-3의 규모에서도 few-shot setting 성능이 좋지 않은 일부 태스크도 발견되었다. 이러한 태스크에는 ANLI 데이터셋과 같은 자연어 추론 태스크, RACE와 같은 일부 독해 데이터셋, 또는 QuAC(QA 데이터셋)가 포함된다. 이러한 한계점을 포함한 GPT-3의 강점과 약점을 다양하게 특징지어 제시함으로써, 본 논문은 언어 모델에서 few shot learning에 대한 연구 흥미를 자극하고자 하고, 어떤 개선이 가장 필요할지 관심을 모으고자 한다.
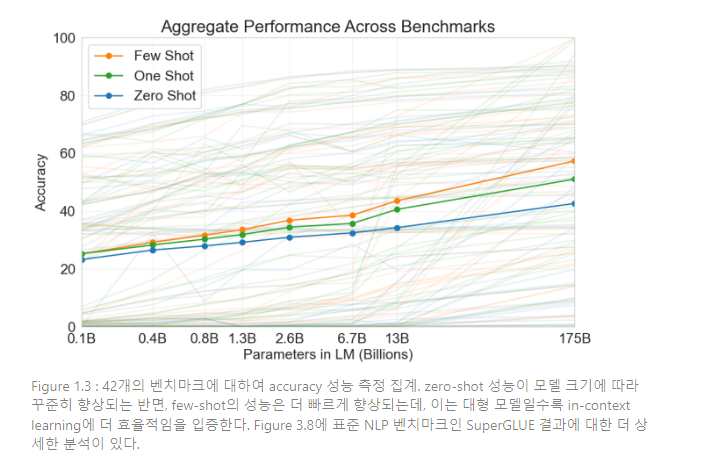
전반적인 결과는 Figure 1.3에서 볼 수 있는데, 다양한 태스크의 집계 결과이다 (그러나 이 자체로 엄밀하거나 의미있는 벤치마크로 여겨져선 안 됨).
본 논문은 앞선 내용과 더불어, 더 작은 모델(12.5억 ~ 130억 파라미터)을 훈련시켜 zero, one, few-shot setting에서 GPT-3과 성능을 비교하고자 한다. 한 가지 눈에 띄는 패턴은 zero-, one-, few-shot 간 차이가 모델 용량에 따라 커진다는 것인데, 이는 더 대용량의 모델이 더 유능한 meta-learners임을 의미한다.
본 논문은 다음과 같이 구성되어 있다. 섹션 2는 GPT-3의 훈련과 평가 접근법과 방법론에 대해 묘사한다. 섹션 3은 모든 태스크에 대한 zero-, one-, few-shot setting의 결과를 제시한다. 섹션 4는 데이터 오염 문제에 대해 다룬다. 섹션 5는 GPT-3의 한계점에 대해 다룬다. 섹션 6은 GPT-3의 광범위한 영향력에 대해 다룬다. 섹션 7은 관련 연구의 리뷰이며, 섹션 8은 결론 부분이다.
2. Approach
본 논문의 기본적인 사전학습 접근법은 모델, 데이터, 훈련 과정을 포함하여 [RWC+19]에서 설명된 프로세스와 유사하다. 상대적으로 단순하게 모델의 크기, 데이터셋의 크기, 데이터셋의 크기와 다양성, 훈련 시간을 늘린다. in-context learning을 사용한 점도 [RWC+19]와 유사한데, 본 논문은 문맥 내 학습에 대한 셋팅을 다양하고 체계적으로 탐구한다. 그리고 본 섹션은 GPT-3을 평가하기 위한 다양한 셋팅을 명확하게 정의하고 대조하며 시작하고자 한다. 셋팅은 의존성이 있는 태스크 명시적인 데이터가 얼마나 많은지에 대한 스펙트럼에 달려 있다. 그리고 이러한 스펙트럼에서 4개의 포인트를 찾을 수 있다.
Fine-Tuning(FT): 최근 가장 흔한 접근법이며, 원하는 태스크에 명시적인 지도 데이터셋을 학습시킴으로써 사전학습된 모델의 가중치를 업데이트 하는 과정을 수반한다. 전형적으로 수천, 수백만의 라벨링 된 예제가 사용된다.
파인튜닝의 주요한 장점은 많은 벤치마크에서 강력한 성능을 보인다는 것이다. 파인튜닝의 주요한 단점은 모든 태스크에서 새로운 대형 데이터셋이 필요하고, out-of-distribution에서 일반화에 실패할 가능성, 그리고 학습 데이터셋에서 거짓된 특성을 이용할 가능성이다.
이러한 단점들은 인간의 수행능력과 비교하기에 부당한 결과를 가져온다. 본 논문은 task-agnostic한 성능에 집중하기 위해 GPT-3을 파인튜닝하지 않는다.
Few-Shot(FS): [RWC+19]의 조건과 동일하게, 모델이 추론 시에 태스크에 대해 약간의 설명을 제공받는데, 가중치 업데이트가 허용되지 않은 경우를 나타내기 위해 사용하는 용어이다.
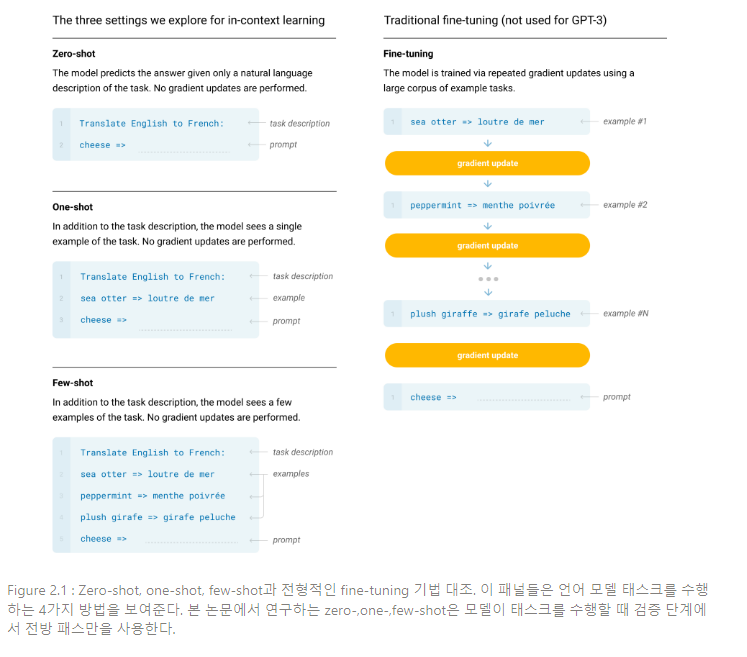
Figure 2.1에서와 같이 전형적인 데이터셋의 예제는 문맥과 희망하는 completion(수행 결과)를 갖고(예를 들면 영어 문장과 불어 번역 한 쌍), few-shot은 K개의 문맥 예제와 completion을 부여하고 그 다음 모델이 completion을 제공할 것으로 예상되는 문맥의 최종 예제 한 개를 제공한다.
일반적으로 얼마나 많은 예제가 문맥의 context window에 fit 할 수 있는지에 따라 K를 10 ~ 100 범위 내에서 설정한다().
Few-shot의 주된 장점은 태스크 명시적인 데이터에 대한 필요성을 줄여주고, large · narrow한 파인튜닝 데이터셋에서 지나치게 편협한 distribution을 학습할 가능성을 줄여준다는 것이다.
주된 단점은 아직까지 파인튜닝 SOTA 모델에 비해 성능이 크게 뒤떨어진다는 것이다. 그리고 여전히 적지만 태스크 명시적인 데이터가 요구된다.
One-Shot(1S): Figure 1에서와 같이 태스크에 대한 자연어 설명에 단 1개의 설명만 허용된다는 것을 제외하면 few-shot과 동일하다. One-shot을 few-shot/zero-shot과 구분하는 이유는 일부 태스크가 사람과 의사소통하는 방식이 가장 비슷하게 매치되기 때문이다. 예를 들어 사람에게 human worker service 데이터셋을 생성해 보라 하면(e.g. Mechanical Turk), 태스크에 대한 1개 설명을 부여하는 것이 일반적이다. 반면, 예시가 주어지지 않는 경우 태스크에 대한 내용이나 형식에 대해 의사소통하는 것이 어려울 때도 있다.
Zero-Shot(0S): 아무런 설명도 허용되지 않는다는 것을 제외하면 one-shot과 동일하며, 이 모델은 태스크를 설명하는 자연어 설명만이 주어진다. 이러한 방법은 최대한의 편의, 견고함에 대한 가능성, 그리고 거짓된 상관성 회피를 제공하지만, 가장 힘든 셋팅이다. 어떤 경우에는 사전 예제가 주어지지 않으면 사람이라도 태스크의 형식을 이해하기 어려울 수 있고, 따라서 이러한 셋팅은 일부 경우에서 “unfairly hard”하다.
예를 들면, 누군가 “200m dash 세계 기록에 대한 테이블을 생성해라” 라고 요청한다고 하자. 이러한 요청에서 요구한 테이블이 정확히 어떤 형식을 띄어야 하고 무엇이 포함되어야 하는지 명확하지 않기 때문에, 모호한 요청이 된다 (이것을 상세히 밝힌다고 하더라도 무엇을 원하는지에 대한 정확한 이해가 어려울 수 있다).
그럼에도 불구하고, zero-shot의 일부 셋팅은 사람들이 태스크를 수행하는 방식과 가장 가깝다. 예를 들면, Figure 2.1의 번역 예에서, 사람들은 텍스트 지시사항으로 무엇을 해야 하는지 알 수 있을 것이다.
Figure 2.1은 영어를 불어로 번역하는 예를 사용하여 4가지 방법을 나타낸다. 본 논문에서는 특정 벤치마크에 대한 성능과 샘플링 효율성 간 다양한 상충(trade-off)를 제공하고자 zero-shot, one-shot, few-shot을 비교하기 위해 3가지 방법에 집중한다.
본 논문은 특히 few-shot 결과를 강조하는데, few-shot의 결과가 대부분 파인튜닝 모델의 SOTA 성능에서 아주 약간만 뒤쳐지기 때문이다. 그러나 궁극적으로는, one-shot이나 zero-shot이 인간의 퍼포먼스와 가장 공정한 비교로 보이며, 향후 연구에 가장 중요한 타겟이 된다.
섹션 2.1 - 2.3에서는 모델, 훈련 데이터와 훈련 과정에 대해 상세히 설명한다. 섹션 2.4에서는 few-shot, one-shot, zero-shot의 평가를 어떻게 수행했는지 다룬다.
본 논문은 변형된 초기화(modified initialization), 사전 정규화(pre-normalization), 그리고 역토큰화(reversible tokenization)를 포함하여 GPT-2와 동일한 모델과 구조를 사용하는데, Transformer layer 내에서 밀도를 다르게 사용하고, Sparse Transformer와 유사하게 지역적으로 이어진 희소한 어텐션 패턴을 사용한다.
모델 크기에 대한 성능 의존도를 연구하기 위해 8개의 다양한 크기 모델을 훈련시키고, 1750억개 파라미터를 사용하여 훈련된 모델이 곧 GPT-3이 된다. Table 2.1은 8개의 모델에 대한 크기와 구조를 보여준다.
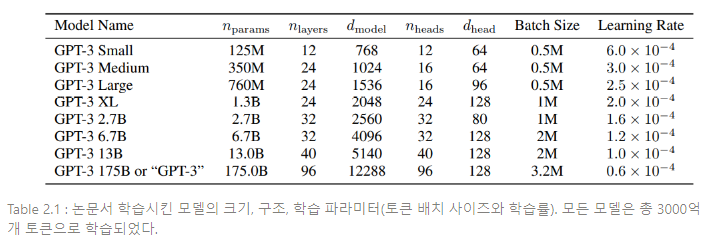
여기서 는 훈련가능한 파라미터의 총 개수이고, 는 총 레이어의 개수, 은 각 병목 레이어에서 유닛의 수(본 논문에서 항상 병목 레이어 크기의 4배만큼 순방향 레이어를 갖는다. ), 는 각 어텐션 헤드의 차원이다. 모든 모델은 tokens의 context window를 사용한다. 본 논문은 노드 간 데이터 전송을 최소화하기 위해 GPUs를 거쳐 차원 깊이와 넓이를 파티셔닝한다.
각 모델에 대한 정확한 구조적 파라미터는 연산 효율성과 GPU를 거친 모델의 레이아웃에서 로드 밸런싱에 기초하여 선택된다. 선행 연구 [KMH+20]에서는 validation loss가 합리적으로 넓은 범위에 있을 때 이러한 파라미터에 크게 민감하지 않다는 것을 시사한다.
본 논문에서는 CommonCrawl 데이터셋을 다운로드하여 고품질의 참조 코퍼스와 유사도를 기반으로 필터링하고, 데이터셋에 대한 도큐먼트 단위의 fuzzy한 중복제거를 수행하여 불필요한 중복을 방지하고, 오버피팅 방지를 위해 홀드아웃 검증 세트를 온전히 보존하며, 유명한 고품질의 참조 코퍼스를 훈련 믹스에 추가하여 CommonCrawl에 더하고 다양성을 향상시킨다. CommonCrawl 처리 과정의 세부사항은 부록 A에 설명되어 있다.
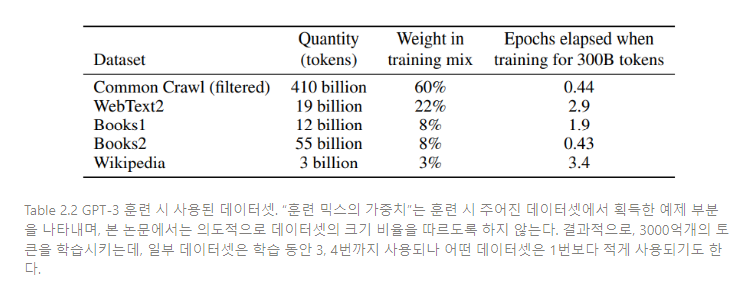
Table 2.2는 훈련 시사용된 데이터셋의 최종 종합본이다. CommonCrawl data는 2016-2019년을 아우른 CommonCrawl에서 일부 발췌했는데, 필터링 이전에 압축된 평문이 45TB, 필터링 이후에 570GB로 구성되어 있고, 이는 byte-pair로 인코딩된 4000억개의 토큰과 동등한 수치이다.
훈련을 진행하는 동안 데이터셋을 동일한 비율로 샘플링되는 것이 아니라 더 높은 품질의 데이터셋이 더 자주 샘플링된다. 이러한 샘플링 방법은 과적합을 감소시킨다.
인터넷 데이터로 사전학습된 언어 모델, 특히 대용량의 모델은 검증 세트나 dev set에서 사전학습 시 사용했던 세트를 무심코 다시 포함하여 다운스트림 태스크를 오염(contamination)시킬 가능성이 있다. 이러한 가능성을 줄이기 위해, 본 논문에서 연구한 모든 벤치마크의 dev set 또는 test set과 오버랩되는 모든 데이터를 삭제하고자 했다. 그러나 일부 오버랩이 남아 있었고, 섹션 4에서는 이러한 잔여 오버랩의 영향력을 특정하고 데이터 오염을 더 공격적으로 제거하고자 한다.
[KMH+20, MKAT180]에서 발견한 것과 같이, 대형 모델은 전형적으로 더 큰 배치 사이즈와 더 작은 학습률을 요구한다. 본 논문은 훈련 시 기울기 잡음(gradient noise) 정도를 측정하고, 이를 배치 사이즈 선택을 지도하고자 사용한다. 학습 과정과 하이퍼파라미터 셋팅의 세부사항은 부록 B에 설명되어 있다.
본 논문에서는 few-shot learning을 위해 태스크 훈련 세트에서 K개의 예제를 임의로 끌어와 검증 세트에서 각 예제를 평가한다. K 값은 최소 0부터 최대로는 모델의 context window가 허용하는 최대 값, 모든 모델에서 이며 일반적으로 예제는 10~100개 정도가 될 수 있다. 더 큰 K값은 일반적으로(항상은 아님) 더 좋으며, 그러므로 dev와 test set를 분리하는 것이 가능하면 dev set에서 K 값을 적게 하여 실험하고 test set에서 최적 값으로 실행한다.
3. Results
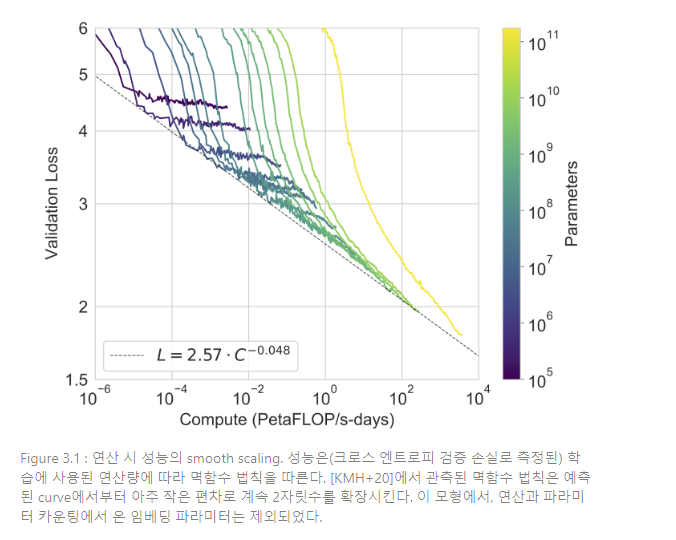
Figure 3.1는 섹션 2에서 설명한 8개 모델에 대한 training curve이다. 본 그래프에는 약 10만 개의 파라미터만 갖는 extra-small model을 추가로 포함한다. [KMH+2-]에서 관측된 바와 같이, 언어 모델링 성능은 훈련 연산을 효율적으로 할 때 power-law(멱함수 법칙)를 따른다.