본 게시글은 MIT Tianhong Li, Kaiming He이 저술한 Back to Basics: Let Denoising Generative Models Denoise (2025) 의 논문 핵심 내용을 정리합니다.
Key Concept
- JiT (Just image Transformers)
: 복잡해진 최신 생성 모델(Generative Models)의 흐름을 거스르고, "기본으로 돌아가자(Back to Basics)"!
기존의 최신 이미지 생성 모델(예: Stable Diffusion, VQ-GAN 등)들은 이미지를 압축하는 Tokenizer나 사전에 학습된 VAE(Variational Autoencoder) 등을 필수적으로 사용했지만, JiT는 이러한 요소 없이 Transformer가 픽셀 데이터를 "직접" 처리하도록 만든다.
본 논문은 현재 널리 쓰이는 Diffusion Model의 학습 방식에 근본적인 의문을 제기했다.
대다수의 Diffusion model은 노이즈()가 섞인 이미지에서 이 ""가 무엇인지를 예측하거나, 노이즈와 데이터가 섞인 "-prediction" 값을 예측하도록 학습된다.
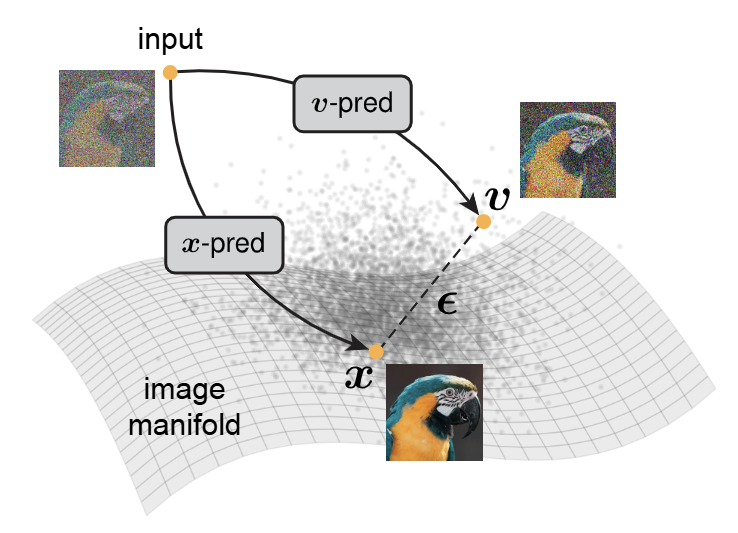
본 논문에서는 이러한 Noise 예측 방식이 비효율적이라고 지적한다. 저차원의 latent space가 아닌 고차원의 pixel space에서 노이즈 예측을 하는 것이 비효율적이라는 것이다. 왜냐하면, 노이즈가 섞인 데이터는 수학적인 Manifold (* Manifold Hypothesis 참조)를 벗어나 있기 때문이다.
따라서 본 논문은 "노이즈가 아닌, 원본(clean image)을 예측하라 (-prediction)"!는 해결책을 내세운다.
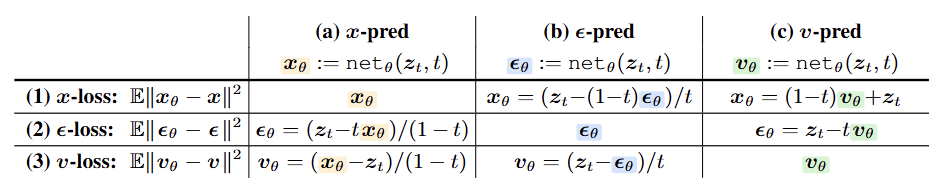
Methodology
JiT의 구조와 학습 방법은 아주 간단하다.
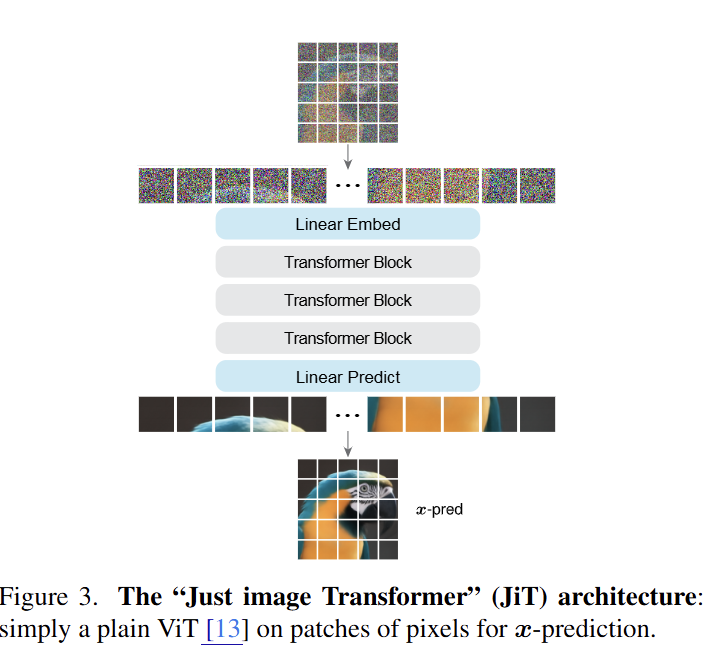
-
이미지 처리: 이미지를 16x16 또는 32x32 크기의 Patch로 자름 (ViT 방식)
-
모델 구조: 일반적인
Vision Transformer (ViT)구조를 거의 그대로 사용 -
학습: 이미지에 노이즈를 섞고, 모델이 원본 이미지() 가 무엇이었는지 맞추도록 학습
-
No Tokenizer: 이미지를 별도의 코드로 변환하지 않음
-
No Latent Model: VAE 같은 사전 학습 모델을 사용하지 않음
-
No Upsampler: 저해상도에서 고해상도로 키우는 복잡한 과정(Cascaded generation) 없이 한 번에 생성
Results and Conclusion
본 논문은 이 단순한 접근법(JiT)이 복잡한 최신 기법들을 능가하거나 대등한 성능을 낸다는 것을 증명한다.
-
ImageNet 성능: ImageNet 256x256 및 512x512 해상도에서 JiT는 기존의 복잡한 Diffusion 모델이나 Autoregressive 모델(MAR 등)과 견줄만한, 혹은 더 뛰어난 생성 성능(FID 점수 등)을 기록
-
vs 비교: 픽셀 공간에서 노이즈() 를 예측하도록 설정하면 학습이 완전히 실패(Catastrophic failure)하는 반면, 원본() 을 예측하면 매우 잘 작동함을 실험적으로 증명
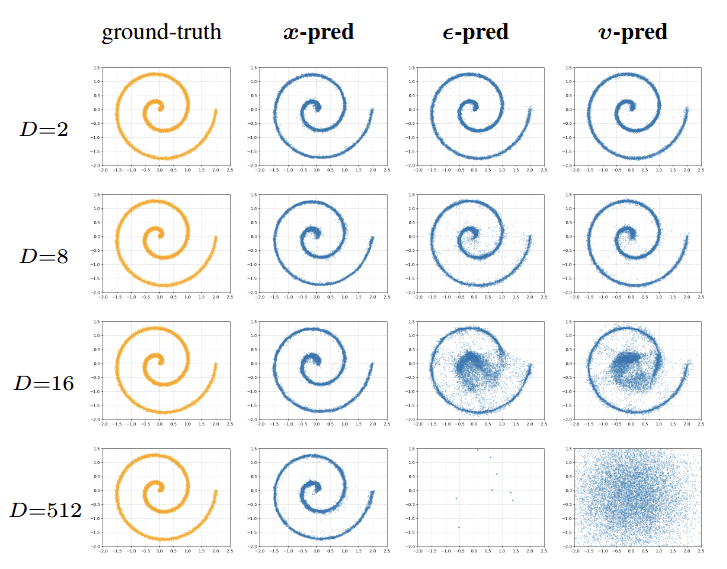
위 Figure는 논문의 Toy Experiment 결과로, "왜 픽셀 공간(pixel space)에서 노이즈를 예측하면 안되는가"를 간단한 실험(265차원 은닉 유닛을 갖는 5-layer ReLU MLP의 간단한 생성 모델을 학습에 사용)으로 직관적으로 증명한다.
-
실험 설정: 인 데이터를 까지의 고차원 공간에 선형 투영(Linear Projection)하여, 픽셀 공간의 차원이 커질 때 모델의 거동을 분석
-
매니폴드 가설: 픽셀 수()가 아무리 늘어나도, 실제 데이터가 존재하는 본질적인 정보량()은 변하지 않으며, 데이터는 고차원 공간 속 얇은 '매니폴드(Manifold)' 위에만 존재
-
-prediction (노이즈 예측) 결과 (failure): 차원()이 증가할수록 예측 대상인 노이즈가 공간 전체에 퍼지게 됨. 이로 인해 모델이 예측한 값이 매니폴드를 벗어나 허공을 헤매게 되며, 결국 학습이 안 되고 발산해버림 (space가 클수록 예측해야 할 노이즈의 분산이 계속 커짐, 학습 난이도가 급격히 상승)
-
-prediction (원본 예측) 결과 (success): 반면 원본을 예측하는 방식은 수학적으로 "부분 공간으로의 투영(Projection onto subspace)" 효과를 가짐. 즉, 모델이 예측을 수행할 때마다 결과값을 강제로 데이터 매니폴드 위로 끌어당기기 때문에, 고차원에서도 매우 안정적으로 학습
결론
본 논문은 최신 이미지 생성 모델들이 지나치게 복잡해지고 있다는 문제의식에서 출발하여, 불필요한 구성 요소(Tokenizer, VAE, Upsampler)를 모두 제거한 단순한 JiT (Just image Transformers) 아키텍처를 제안했다.
연구 결과, 픽셀 공간(Pixel Space)에서 노이즈() 대신 원본 데이터()를 직접 예측하도록 학습 방식을 변경하는 것만으로도, 기존의 복잡한 잠재 모델(Latent Models)들을 능가하거나 대등한 성능을 달성할 수 있음을 입증했다.
이는 생성 AI 연구가 '복잡한 기교'보다는 '데이터 처리의 본질'인 기본(Basics)으로 돌아가야 함을 시사하며, JiT는 향후 고성능 생성 모델 연구를 위한 강력하고 단순한 베이스라인(Baseline)이 될 것이다.
