
최근에 robotics에서 LLM으로 주어진 instruction에 대한 planning을 생성하고 수행하는 태스크에 관한 연구들이 많이 되고 있는데, openai에서 공개해서 화제가 됐던 figure 01, 02 모델 보면 그 성능이 진짜 놀랍다.

안 봤다면 유투브의 Figure 1 데모영상을 꼭 보시길!
여튼 LLM이나 foundation model을 로보틱스에 접목하는건 꽤 매력있는 연구 분야인 것 같고, 특히 LLM planner 쪽에 관심이 생겨서 논문을 종종 찾아보기도 했었는데, 최근에 산학과제에서 관련 연구를 실제로 해볼 기회가 생겨서 공부 겸 벨로그에 정리해보려고 한다.
처음으로 리뷰할 관련 논문은 최근에 영감을 많이 받았던 LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models (ICCV, 2023)이다.
1. Introduction
다용도의 embodied agents을 개발하는 것은 오랜 연구 과제였으나, 현재의 language-driven agents는 많은 labeling data가 필요하다는 한계점이 있다. 최근 gpt와 같은 LLM에서 few-shot learning을 통해 새로운 태스크를 학습하는 잠재력을 보였으나, 제한된 환경에서만 수행이 가능했다. 대표적으로, SayCan(2022)은 사전 정의된 object, skill set에 의존하며, 복잡한 환경에서 비용 및 효율성 문제를 겪는다. 또한, 환경 인식(environmental perception)을 기반으로 동적으로 계획을 조정하는 기능이 부족하다.
→ agent가 모든 단계에서 모든 admissible skills를 평가하기 위해 LLM을 호출해야 하므로, 더 많은 개체가 있는 더 복잡한 환경에서는 비용이 빠르게 누적될 수 있으며 동시에 효율성이 저하됨
이러한 문제를 해결하기 위해, 본 논문은 LLM-Planner를 제안한다. LLM-Planner는 다양하고 부분적으로 관찰 가능한(partially-observable) 환경에서도 유연하게 동작하며, 환경의 변화에 따라 계획을 동적으로 조정이 가능하다.
본 논문에서는 hierarchical planning model을 채택하여 LLM이 high-level planner(HLP)을 생성하고, low-level planner가 이를 세부 작업으로 변환시키도록 한다. 기존 연구와 달리, LLM-Planner는 환경에서 관찰된 객체 정보를 프롬프트에 포함해 LLM이 생성한 계획의 grounding(LLM의 텍스트를 물리적인 실제 환경 정보와 mapping하는 것)를 강화하고, 실패 시 동적으로 재계획을 생성하는 알고리즘을 도입한다.
이러한 접근 방식은 LLM의 계획과 환경 간 closed-loop(에이전트가 반복적으로 환경에서 피드백을 받으며 계획을 재조정하는 과정)를 형성해 에이전트가 환경 변화에 유연하게 대응하도록 한다.
LLM-Planner는 강력한 baseline model HLSM(Hierarchical Language-conditioned Spatial Model,2021)의 perception module과 low-level planner를 통합하여, ALFRED 데이터셋에서 평가되었고 그 강력한 성능을 입증했다. 소수의 페어링된 데이터(0.5% 미만)만 사용하여도, HLSM에 필적하는 성능을 거두었으며 다른 베이스라인 모델들을 능가하는 성과를 보였다. 본 논문은 LLM과 grounding을 활용하여 다목적, 고효율 embodied agent 개발의 새로운 가능성을 열었다.
2. Related Works
Vision-and-Language Navigation(VLN)에서는 Transformer 기반 모델이 R2R(Room-to-Room)(CVPR, 2018)과 같은 데이터세트에서 좋은 성능을 보였으나, ALFRED(CVPR, 2020)와 같은 복잡한 데이터세트에서는 상위 수준(high-level)과 하위 수준(low-level) 계획을 분리하는 hierarchical planning models(계층적 계획 모델)이 더 효과적임이 입증되었다. 이러한 모델은 사전 학습된 언어 모델(BERT 등)을 활용해 상위 수준 계획(high-level plan, HLP)을 생성하고, 시맨틱 맵을 통해 하위 목표를 실행한다.
예를 들어, Skill induction and planning with latent language(2021)의 은 ALFRED 데이터의 일부(10%)만으로도 자연어 기반 하위 작업을 생성해 높은 효율을 보여주었으며, LLM 기반 few-shot 학습 접근법의 가능성을 제시한다.
기존 연구에서 LLM은 주로 보조 도우미(Auxiliary Helper)나 플래너(Planner)로 사용되었다. 보조 도우미로 LLM을 활용한 연구(예: LM-Nav)는 내비게이션을 돕기 위해 관련 정보를 생성하는 데 초점을 맞췄으나, 이는 계획 단계에서의 적극적인 활용이 부족했다. 반면, 플래너로서의 LLM을 탐구한 연구들은 허용 가능한 동작(action)의 목록을 가정하거나 이를 모델로 예측하려는 접근법을 사용했다. 하지만 이러한 가정은 부분적으로 관찰 가능한 환경이나 객체 수가 많아지는 상황에서는 현실적이지 못하다.
LLM-Planner는 기존 연구를 확장하며 허용 가능한 행동 목록에 의존하지 않고 HLP를 직접 생성함으로써 새로운 observation에 따라 계획을 동적으로 조정할 수 있다. 또한, LLM-Planner는 ALFRED 환경에서 라벨링된 데이터의 일부만으로도 고품질의 HLP를 생성해 few-shot example 기반의 효과적인 계획 수립과 실행 가능성을 입증했다.
3. Prelimiaries
Vision-and-Language Navigation
Embodied instruction following은 종종 vision-and-language navigation(VLN)이라고도 하지만, 상호작용 동작이 추가로 포함되며 일반적으로 일반적인 VLN 태스크(예: Room2Room)보다 훨씬 긴 시간 범위가 특징이다. 본 논문에서는 주로 AI2-Thor 시뮬레이터 위에 구축된 표준 ALFRED 데이터 세트에 초점을 맞추겠지만, 다른 데이터 세트와 환경으로도 쉽게 일반화가 가능하다.
VLN 태스크는 다음과 같이 정의된다: language instruction 가 주어질 때, agent는 태스크 수행을 위해 environment 에서 일련의 primitive actions를 예측하고 수행해야 한다. ALFRED와 같은 데이터 세트에서 instruction 는 high-level goal 와 (optionally) step-by-step instruction 로 구성된다. 따라서 VLN 태스크는 튜플(, , )로 표현될 수 있으며, 여기서 는 goal test를 나타낸다. 최근 여러 연구에서 VLN에 hierarchical planning models을 적용하는 방안을 탐구하지만, planning에서 few-shot setting이나 LLM을 고려하지는 않는다.
본 논문에서도 hierarchical한 방식으로 planning을 모델링한다. high-level planner(상위 계획자)는 instruction 를 high-level plan (HLP) 로 매핑하며, 여기서 각 subgoal(하위 목표) 는 (high-level action, object)으로 지정한다. high-level action은 ALFRED에서 single goal-condition을 완료할 수 있는 primitive actions의 모음으로 정의한다. 본 논문에서는 ALFRED의 interaction actions(상호작용 행동)를 인용하고, Navigation action만 추가한다. 따라서, high-level action space는 하나의 navigation action (Navigation)과 7개의 interaction actions(, , , , , , )으로 구성된다. SayCan, LM zero-shot planner와 같은 다른 관련 연구에서도 유사한 action들이 흔히 사용된다.
low-level planner는 각 subgoal을 일련의 기본 동작 로 매핑한다. SOTA VLN methods에서는 지도 기반 low-level planner와 간단한 경로 찾기 알고리즘(path-finding algorithm)을 사용하여 지도에서 현재 하위 목표에 대한 target object를 찾는다.
한 가지 중요한 점은, high-level plan 가 지정되면 low-level planning은 명령어 와 독립적이 되며, 이를 공식적으로 표현하면 가 된다는 것이다. low-level planner에 포함된 모든 구성 요소는 결정론적(determinisitic)이거나 시뮬레이터의 합성 데이터를 사용하여 훈련된다. language instruction을 포함하는 paired data를 필요로 하지 않는다.
In-Context Learning/Prompting.
최근에는 in-context learning(prompt)이 LLM의 부상과 함께 큰 주목을 받고 있다. 다양한 프롬프트를 설계함으로써 LLM은 파라미터를 업데이트하지 않고도 몇 가지 데모 예제를 통해 다양한 downstream task에 적용될 수 있다. 본 논문에서는 embodied agent planning을 위한 LLM의 in-context learning에 대해 탐구한다.
True Few-Shot Setting.
소수의 훈련 예제만 사용하지만, 다수의 few-shot 연구에서는 신속한 설계와 모델 선택을 위해 대규모 검증 세트를 사용한다. 최근 연구는 이러한 대규모 검증 세트가 모델 선택에 강한 편향을 일으키고, 의도한 few-shot setting을 위반하여 언어 모델의 효능을 과대평가하는 원인이 된다는 것을 입증했다. 이러한 편향을 피하기 위해, 본 논문에서는 별도의 검증 세트를 사용하는 대신 동일한 소규모 훈련 세트에서 교차 검증을 통해 신속한 설계와 모델 선택을 수행하는 true few-shot setting을 고수한다.
4. LLM-Planner
GPT-3과 같은 LLMs를 사용하여 embodied agent에서 few-shot grounded high-level planning을 수행하는 LLM-Planner에 대해 설명한다
4.1. Overview
GPT-3과 같은 LLM들은 자연어 생성을 위해 사전학습된다. 이러한 LLM을 high-level planners에 적용하려면, 가장 먼저 해야 할 일은 high-level plan 생성을 위해 적절한 프롬프트를 설계하는 것이다. 다음 section 4.2 에서 이러한 프롬프트 설계에 대해 설명한다. in-contenxt examples의 선택은 LLM의 성능에 중요한 영향을 끼치고, 최근 연구에서는 각 test example에 대해 유사한 examples를 동적으로 검색하는 것이 효율적임을 입증한 바 있다.
본 논문에서는 KNN retriever를 사용하여 in-context examples를 선택한다. 또한, 로짓 편향(logit biases)을 사용하여 LLM의 output space를 허용된 action, object set 내로 한정시킨다.
위와 같은 설계 과정을 통해 static version의 LLM-Planner를 얻을 수 있는데, LLM-Planner는 이러한 설계만으로도 합리적인 HLPs를 생성해낼 수 있다.
4.2. Prompt Design
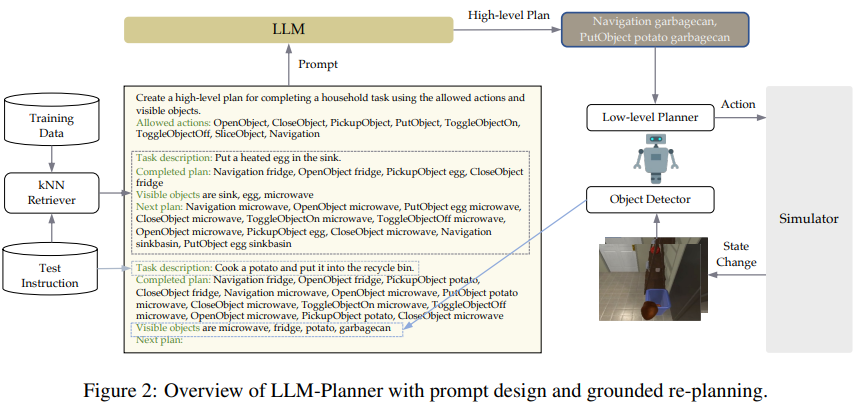
prompt involves :
(1) an intuitive explanation of the task , list of allowable high-level actions
(2) knn-retriever를 통해 선택된 in-context examples
(3) step-by-step 또는 high-level goal instruction format 사용
(4) dynamic grounded replanning : 완료된 subgoal과 현재 환경에서 지금까지 인식된 객체 리스트를 task description 뒤에 추가
(5) test example 추가, “Next Plan" 으로 포맷 끝내기
4.3. In-context Example Retrieval
in-context examples는 LLM에서 task-specific information의 중요한 원천이다. 다양한 예제는 현재 태스크에 대해 다양한 정보를 제공해준다. 직관적으로, 현재 태스크가 “cook a potato"라면, “cook an egg"에 대한 HLP를 설명하는 in-context example이 “clean a plate"에 대해 설명하는 예제보다 더 informative할 가능성이 높다.
본 논문에서는 frozen BERT-base model을 사용하여 각 training examples와 현재의 test example에 대한 pairwise similarity를 평가한다. 두 예제 간의 similarity는 각 예제에 대응하는 instruction의 BERT embedding에 대한 Euclidean distance에 기반하여 정의된다.
각 test example에 대하여, 본 논문의 저자들이 갖고 있는 paired training examples set에서 K-most similar examples를 검색하게 한다. 여기서 K는 true-shot setting의 hyperparameter가 된다. (사용하고자 하는 few-shot example 개수)
4.4. Grounded Re-planning
LLM-Planner를 태스크 시작 시점에서만 HLP를 예측하는 static high-level planner로 사용하는 것의 데이터 효율성과 정확성은 이미 입증되었다. 그러나, 이러한 static planning은 물리적 환경과의 grounding이 부족하며, 부적절한 객체와 수행불가능한 계획의 생성으로 이어질 수 있다.
이러한 문제가 발생했을 때, 에이전트는 HLP에서 명시했던 현재의 하위 목표를 수행할 수 없게 되고, 이러한 상황은 2개 중 한 가지 상황으로 이어진다 : 1) action 수행에 실패한다 (예를 들어, 벽에 충돌하거나, 객체와 상호작용하는 데 실패하게 됨), 2) 오랜 시간이 경과하였음에도, 현재의 하위 목표를 여전히 이행하지 못함 (예를 들어, 로봇이 끊임없이 방황하게 됨).
직관적으로, “현재의 환경에서 객체를 인지하는 것”은 이러한 문제들을 해결하는 데 큰 도움이 된다. 예를 들어, “냉장고가 있다"는 것을 인지하고 있다면, 감자를 냉장고 안에서 찾으려고 할 것이다. 왜냐하면, 언어 모델은 사전학습 동안에 “식품은 주로 냉장고 안에 보관된다"와 같은 상식(commonsense knowledge)을 학습했기 때문이다.
이러한 관점에서 본 논문은 환경에서 관측된 객체(embodied agent의 object detector로부터 제공받는다)의 리스트를 프롬프트에 주입함으로써, LLM의 physical grounding을 향상시키는 단순하고 효율적인 방법을 사용한다. 또한, 이러한 관측 객체들에 로짓 편향을 추가하여, LLM-Planner가 계획을 생성할 때 태스크와 관련된 관측 객체들을 우선으로 생성할 수 있도록 한다.
위 설명에 기반하여, 본 논문은 태스크를 수행하는 동안 동적으로 HLP를 업데이트하는 grounded re-planning algorithm (Algorithm 1)을 제안한다. 이러한 방법은 fixed HLP를 생성하고, action 수행 시간 동안 이러한 고정 HLP 값을 고수(수행시간 내 발생하는 문제에 동적으로 대응하지 못함)하는 현존하는 다른 hierarchical planning model들과는 대조적이라고 할 수 있다.

이러한 re-planning 과정은 다음 두 조건 하에서 촉발된다: (1) agent가 액션 수행에 실패 (2) 액션 수행 시 일정 time step 초과
LLP-Planner를 통해 부분적으로 수행된 HLP를 새로 생성할 때, 관측된 객체에 기반하며, 에이전트는 새로운 계획을 수행하게 된다.
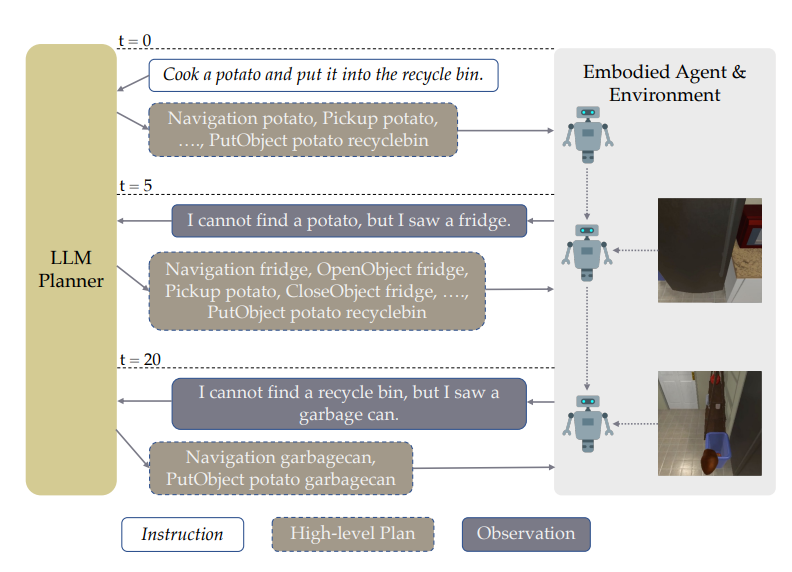
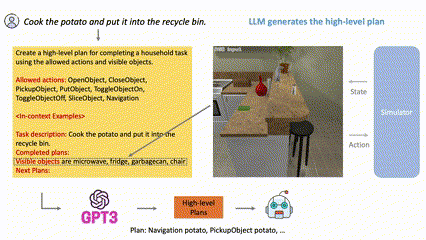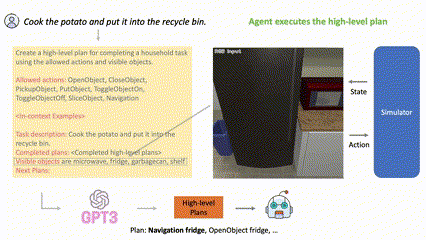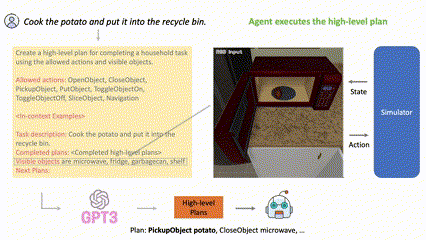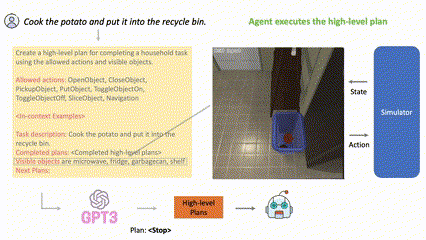
(Figure 1) LLM-Planner for high-level planning. t=0에서 natural language instruction을 전달받은 후 LLM-Planner는 gpt-3와 같은 LLM에 prompting하여 high-level plan을 생성한다. embodied agent가 현 계획을 실행하다가 막히면 (t=5, t=20), LLM-Planner는 environment observation을 기반으로 계획을 재수립하여, grounded plan을 생성함으로써 에이전트가 막힘 상태에서 벗어나는 데 도움을 줄 수 있다.
LLM에서 사전학습된 상식(commonsense knowledge) (예를 들어, 음식은 대체로 냉장고에 보관된다)을 통해 그럴듯한 고수준의 계획을 생성하고 새로운 환경 인식을 기반으로 다시 계획을 세울 수 있다.
4.5 .Integration with Existing VLN models
LLM-Planner를 현존하는 모델과 통합하여 few-shot planning 능력을 부여하는 방법에 대해 논의한다. LLM-Planner는 통합을 위해 상당히 일반적이고 유연한 인터페이스를 제공한다.
Algorithm 1에서와 같이, embodied agent가 object list를 제공하기만 하면 되고, predicted HLP를 low-level actions으로 전환할 수 있는 low-level planner가 있다. 에이전트의 내부 작업에 대한 가정은 없다. LLM-Planner의 end-to-end task 완료 성능을 평가하기 위해, 이러한 인터페이스를 만족하는 강력한 베이스라인 모델인 HLSM과 통합한다.
5. Experiments
Dataset
본 논문에서는 ALFRED benchmark dataset을 사용하여 높은 수준의 계획을 생성하는 데 있어 LLM-Planner의 효율성을 평가한다.
- ALFRED benchmark : 207개의 고유한 환경, 115개의 서로 다른 객체 유형, 4,703개의 작업에 걸쳐 7가지 태스크 유형으로 구성. 작업은 “하나의 물체를 새로운 위치로 옮기는 것”부터 “가열된 물체 조각을 용기에 넣는 것”까지 다양한 난이도로 구성되어 있음. 각 작업에는 높은 수준의 목표에 대한 사람이 작성한 주석과 전문가가 작업의 시연을 보면서 만든 일련의 세분화된 단계별 지침이 함께 제공됨.

Metrics
ALFRED에서 사용하는 2개의 main metrics와 본 논문에서 만든 1개의 metrics를 사용하여 high-level planning의 정확도를 계산한다.
-
성공률(Success rate, SR)은 에이전트가 완전히 완료한 태스크(fully completed)의 비율이다. 태스크는 모든 하위 목표가 완료된 경우에만 완료된 것으로 간주된다. -
목표 조건 성공률(Goal-condition success rate,GC)은 완료된 목표 조건의 백분율이다. 목표 조건은 작업을 완료하는 데 필요한 상태 변경(state changes)으로 정의된다. 예를 들어, “가열된 빵 슬라이스하기” 태스크에서 “빵이 슬라이스되는 것”과 “빵이 가열되는 것”은 모두 목표 조건이다. -
본 논문에서는 high-level planning을 직접 평가하기 위해,
high-level planning accuracy (HLP ACC)라는 새로운 metrics를 도입했다. 실측 HLP와 비교하여 예측된 HLP의 정확도를 나타낸다.static planning setting의 경우, 생성된 HLP를 기준 ground-truth HLP와 비교하여 기준 진실과 완벽하게 일치하지 않으면 계획이 잘못된 것으로 간주하고 그렇지 않은 경우 수정한다.
dynamic planning setting의 경우, oracle low-level controller에 액세스할 수 없어 LLM-Planner performance와 low-level controller choice를 완전히 분리할 수 없기 때문에, 범위를 기록한다. 하한은 로우레벨 컨트롤러에 의해 성공적으로 실행되었는지 여부와 관계없이 전체 생성된 계획의 HLP 정확도다(즉, 정적 HLP를 평가하는 것과 동일). 상한은 작업이 종료되었을 때(즉, 작업 성공 또는 치명적인 실패) low-level controller에 의해 환경에서 성공적으로 실행된 예측된 HLP의 HLP 정확도다.
Implementation Details
본 논문에서는 ALFRED 벤치마크의 training examples 21,023개 중, 100개를 선택하여 LLM-Planner에 사용한다. 무작위 계층화 샘플링(random stratified sampling)을 적용하여 100개의 example set에서 7가지의 태스크 유형을 모두 공정히 나타낼 수 있도록 한다.
- kNN-retriever → Huggingface의 pretrained BERT-base-uncased model을 사용.
- LLM → public GPT-3 API와 kNN retriever가 선택한 in-context examples 사용(100개의 예제 중 9개를 선택). temperature를 0으로 설정하고 모든 허용 가능한 출력 토큰(allowable output token)에 0.1의 logit bias를 적용한다.
grounded re-planning을 위한 object list는 object detector에서 검색된다. (object detector → 본 논문에서는 HLSM의 perception model에서 사전 학습된 객체 감지기를 사용)
노이즈 감소를 위해 label confidence가 80% 이상인 객체만 포함한다. few shot assumption을 위반하지 않기 위해, 본 논문에서는 자연어 명령(natural language instructions, NLI)나 human annotations을 포함하는 paired training data를 사용하지 않고, simulator에서 synthesized trajectories만을 사용하여 학습된 HLSM로부터 사전 훈련된 navigation, perception,depth model 을 사용한다.
본 논문에서는 두 가지 주요 baseline model인 HLSM(PMLR, 2022), FILM (ECCV, 2020)을 비교했다. 두 모델 역시 hierarchical planning models이며, ALFRED 리더보드에서 강력한 성능을 달성했다. 본 논문에서는 두 모델에 대해 훈련된 high-level planner를 LLM-Planner로 대체했고, 다른 부분은 전혀 수정하지 않았다. 또한, 동일한 few-shot setting에서 LLM-Planner와 비교하기 위해 이 모델들을 재훈련시켰다.
전체 데이터로 훈련된 다른 여러가지 베이스라인 모델과도 비교하고, SayCan를 ALFRED에 구현하여 LLM-Planner와 동일한 few-shot setting에서 비교한다.
SayCan(2022)은 admissible actions 목록을 필요로 하는 ranking based high-level planner로, LLM을 사용하여 admissible action에 대한 순위를 매긴다. SayCan이 ALFRED의 복잡하고 부분적으로 관찰 가능한 환경에서도 작동할 수 있도록 하기 위해, 현재 환경의 모든 객체와 어포던스(affordances)를 선험적으로 파악하여 스킬 목록을 컴파일하는 불공정한 경쟁 우위(unfair competitive advantage)를 부여했습니다. 또한 원문에서는 필요하지 않았던(→원문의 태스크 다양성이 부족해서 필요하지 않았음) LLM-Planner의 kNN retriever를 SayCan에 적용했다.
Other Baselines. Table 1에 포함된 다른 베이스라인 모델들은 퍼블릭 모델을 기반으로 결과를 도출했다.
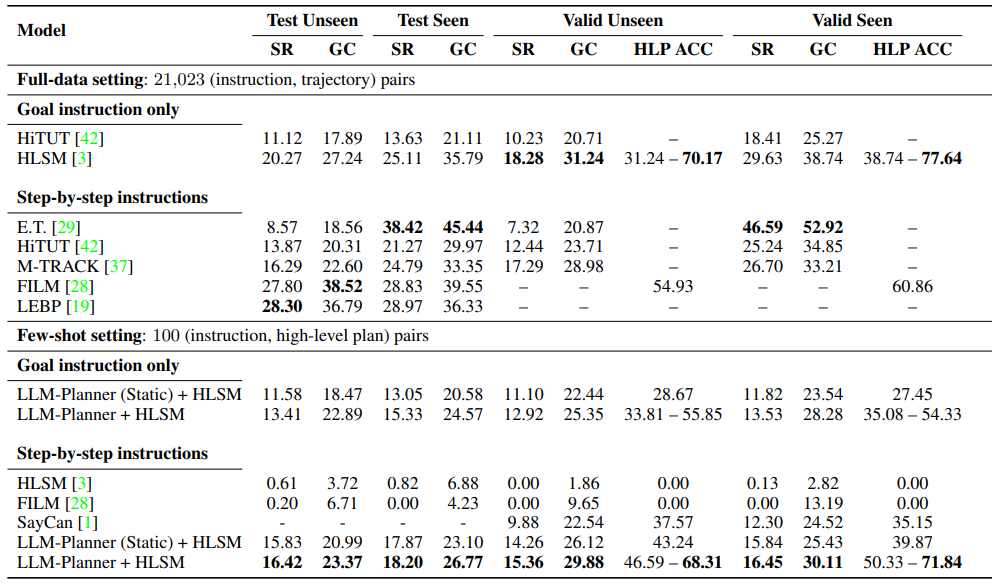
Table 1. ALFRED dataset의 main results. “(static)”은 정적 계획 setting을 나타내고, 그 외에는 grounded-replanning과 동적 계획 setting을 디폴트로 사용한다.
Main Results
주요 결과는 Table 1을 참조.
먼저 HLSM의 성능을 LLM-Planner를 high-level planner로 사용했을 때와 ALFRED의 전체 훈련 세트를 사용하여 훈련했을 때(native version)를 비교한다. LLM-Planner의 few-shot performance는 0.5% 미만의 paired training data를 사용함에도 불구하고 원본 HLSM과 competitive하며, E.T., HiTUT, M-TRACK 등 여러 최신 베이스라인 모델보다 뛰어난 성능을 보였다.
반면, 동일한 100개의 예제를 사용하여 훈련할 경우(즉, HLSM의 high-level planner를 재훈련할 경우) HLSM(그리고 FILM도 마찬가지임)은 거의 모든 작업을 성공적으로 완료할 수 없었다.
또한, 전체 환경 정보에 액세스할 수 있음에도 불구하고 SayCan은 여전히 LLM-Planner보다 성능이 크게 떨어지는 것으로 나타났다.
또 다른 중요한 차이점은 비용과 효율성이다. SayCan은 순위를 매기는 특성으로 인해 LLM-Planner와 같은 생성 모델보다 훨씬 더 많은 횟수로 LLM을 호출해야 한다: LLM-Planner는 작업당 평균 7회, SayCan은 22회 호출한다 (현재 환경에 대한 oracle knowledge로 스킬 목록을 줄인 것).
마지막으로, static planning보다 grounded re-planning이 상당한 개선을 보였으며, 특히 unseen test split에서 1.83%의 SR이 개선되었. 이는 grounded re-planning의 효과를 입증하는데, 여전히 개선의 여지가 크다는 점도 주목할 필요가 있다.
Ablation Studies
ablation study에서는 LLM-Planner의 다양한 구성 요소에 대한 제거 연구를 수행하여 그 효과를 검증한다. 본 논문에서는 LOOCV 프로세스를 따르고 high-level planning 정확도만을 사용하여 선택을 결정한다. 이 연구의 결과는 Table 2에 명시되어 있다.
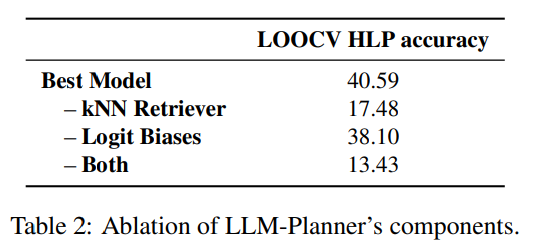
먼저 100개의 example set에서 kNN retriever module을 제거하고, in-context example를 무작위로 선택하는 retriever로 대체하여 본다. Table 2의 결과에 따르면, 이 경우 성능이 크게 저하되어 dynamic retrieval의 필요성을 확인할 수 있다.
또한 환경에 존재하는 개체를 선호하도록 logit bias를 활성화하면 high-level planning accuracy가 상당히 향상되는걸 볼 수 있다. 이는 명령어가 모호하거나(ambiguous), 객체가 다른 이름으로 참조되는 경우 더욱 강력하게 작동한다.
“Turn on the lamp(램프를 켜라)”라는 명령을 예로 들어보자. 테이블 램프 또는 플로어 램프 등 다양한 유형의 램프가 있을 수 있다. 환경에 나타나는 오브젝트(예: TableLamp)를 선호하도록 logit bias를 활성화하면, LLM-Planner가 올바르게 출력(TurnOnObject, TableLamp)하도록 안내할 수 있다.
또 다른 예로, 명령이 RecycleBin을 참조하지만 환경에서 사용되는 오브젝트 이름이 GarbageCan인 경우이다. 이 경우 로짓 바이어스를 사용하면, LLM-Planner가 관련성 있고 올바른 오브젝트를 출력하도록 올바르게 안내할 수 있다.
Fine-grained Analyses
Effect of Number of Examples.
main experiment에서는 교차 검증(cross-validation) 없이, few-shot setting의 목표 수인 100개를 훈련 예제 수로 선택했다. 그런 다음 LOOCV(Leave-One-Out Cross-Validation)를 사용하여 100개의 샘플링된 훈련 예제를 사용하여 최적의 in-context examples의 수를 선택한다. 본 논문에서는 여전히 다양한 선택의 효과를 궁금해했고, main experiment 후에 하이퍼파라미터에 대한 민감도를 보여주기 위해 다음 분석을 수행한다.
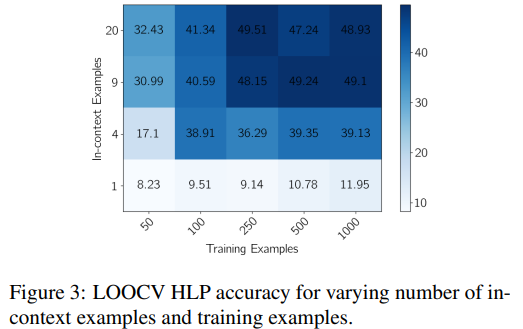
Figure 3에서 볼 수 있듯이, 일반적으로 훈련 예제가 많을수록 HLP accuracy는 향상되지만, 250개 정도의 훈련 예제에서 감소하기 시작한다. Table 1의 주요 실험에서 더 많은 훈련 예제(예: 250개)를 사용하도록 선택하면 상당한 개선을 기대할 수 있다.
또한, in-context example에는 일반적으로 9개가 좋은 수라는 것을 알 수 있다. in-context example을 더 추가해도 성능이 약간 향상될 수는 있지만, 추가 비용을 정당화할 만큼 의미 있는 수준은 아닐 수 있다. in-context examples이 많을수록 검색할 수 있는 유용한 예시가 적기 때문에, 훈련 예시가 적을 때 더 유리하다고 볼 수 있다.
HLP Accuracy by Task Type.
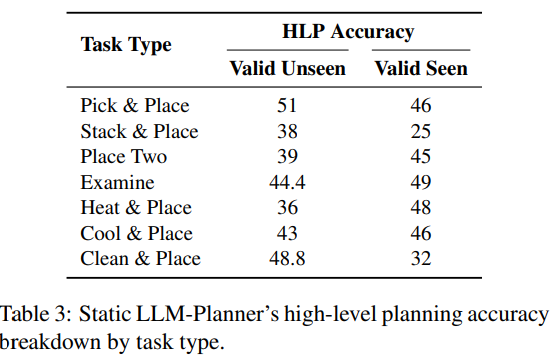
Table 3에는 작업 유형별 LLM-Planner의 high-level planning(HLP) 정확도 분석이 나와 있다. dynamic LLM-Planner는 HLP 정확도에 대한 단일 값을 결정하기 어려워 static LLM-Planner에 초점을 맞추었지만, 일반적으로 동적 버전의 HLP accuracy는 정적 버전의 accuracy와 높은 상관관계를 보인다.
결과를 보면, 작업의 난이도에 따라 결과가 크게 달라지지 않는다는 것을 알 수 있다. 예를 들어, 'Stack & Place' 작업은 최신 모델의 성공률 기준으로 가장 어려운 작업으로 간주되는 경우가 많지만, LLM-Planner의 HLP accuracy는 'Place two'와 같은 쉬운 작업과 비슷하다. LLM-Planner는 작업의 복잡성에 지나치게 민감하지 않다는 것을 알 수 있으며, 이는 몇개의 in-context examples만 있으면 다양한 유형의 작업에 잘 일반화할 수 있음을 시사한다.
Failure Analysis.

ground-truth segmentation, oracle map, teleportation(navigation 대체)을 활용하여 oracle low-level controller를 구현하고 이를 oracle high-level planner를 사용할 때와 비교했다. Table 4의 결과는 성능 차이가 주로 low-level controller의 실패에서 기인한다는 것을 시사한다.
dynamic re-planning을 적용한 oracle low-level controller를 사용하면 성능을 크게 개선할 수 있고, 이는 고수준 계획보다 저수준 제어의 중요성을 강조하며 동적 상황에서의 재계획 기능이 큰 이점을 제공함을 나타낸다.
End-to-End Performance by Task Type.
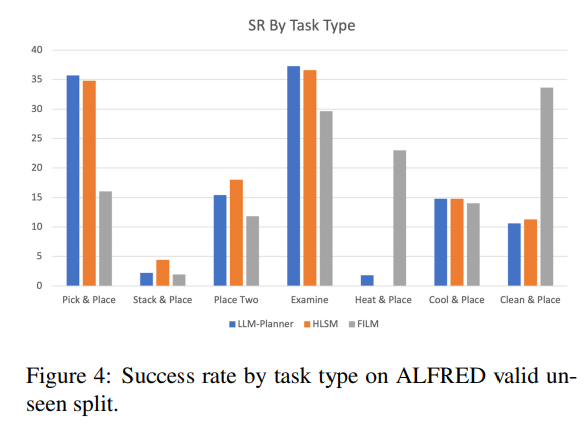
Figure 4는 dynamic LLM-Planner + HLSM의 작업 유형별 end-to-end 성능 분석을 시각화한 것이다. (ALFRED의 전체 훈련 세트로 훈련된 HLSM 및 FILM 포함) LLM-Planner는 few-shot 설정이 적용되었으므로 결과를 직접 비교하는 것이 적절하지는 않다. 그럼에도 불구하고, LLMPlanner + HLSM이 HLSM과 비슷한 성능을 달성하고 둘의 분포가 비슷함을 알 수 있다.
이는 low-level planner와 object detector가 공유되어 유사한 error profile이 발생하기 때문일 수 있다. 이것은 다시 한번 few-shot high-level planner가 전체 훈련 세트로 훈련된 HLSM의 하이레벨 플래너만큼 우수하다는 것을 증명하고, 반면 더 나은 low-level planners와 object detectors를 사용하여 개선할 여지가 여전히 크다는 것을 보여준다.
Case Studies.
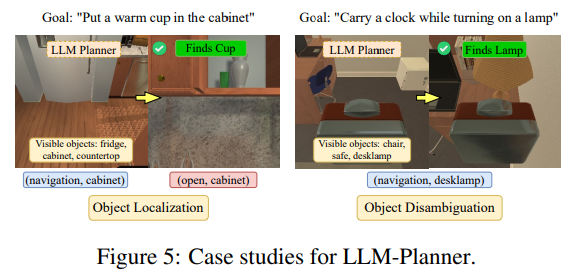
Figure 5에서는 LLM-Planner가 grounded re-planning을 통해 객체 위치 파악 및 모호성 해소에 도움을 주는 두 가지 예를 보여준다. 첫 번째 사례에서, high-level goal instruction만 사용했을때 LLM-Planner는 컵을 찾지 못했지만, 환경에서 cabinet을 관찰한 후 컵이 cabinet에 있을 가능성이 높다고 정확하게 예측한다.
이는 LLM-Planner가 FILM에서 시맨틱 맵이 달성하고자 하는 것과 유사한 효과, 즉 대상 객체의 그럴듯한 위치 예측을 달성할 수 있음을 증명한다. 두 번째 사례에서는 LLM-Planner가 '램프'라는 단어를 환경의 탁상용 램프에 정확하게 grounding할 수 있음을 보여준다.
Conclusion
본 논문은 다양하고 부분적으로 관찰 가능한 복잡한 환경에서 사용할 수 있는 embodied agents를 위한 LLM 기반 새로운 high-level planner를 제시한다. 또한 환경 인식을 기반으로 동적으로 재계획하여 보다 근거에 입각한 계획을 생성할 수 있다. 이러한 작업을 통해 다음 작업의 지침을 학습하는 데 필요한 human annotation 작업을 획기적으로 줄일 수 있다.
또한 대규모 언어 모델의 힘을 활용하고 물리적 근거를 통해 이를 강화함으로써 다재다능하고 샘플 효율성이 매우 높은 embodied agents 개발할 수 있는 새로운 지평을 열었다. 향후 유망한 연구 방향성으로는 Codex(GPT 계열의 프로그래밍 및 코드 생성 작업에 특화된 모델)와 같은 다른 LLM 탐색, 더 나은 프롬프트 설계, 접지 및 동적 리플래닝을 위한 고급 방법 등이 있다.
